The Snapdragon 855 Performance Preview: Setting the Stage for Flagship Android 2019
by Andrei Frumusanu on January 15, 2019 8:00 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- SoCs
- 7nm
- Snapdragon 855
Inference Performance: Good, But Missing Tensor APIs
Beyond CPU and GPU, the one aspect of the Snapdragon 855 that Qualcomm made a lot of noise about is the new Hexagon 690 accelerator block.
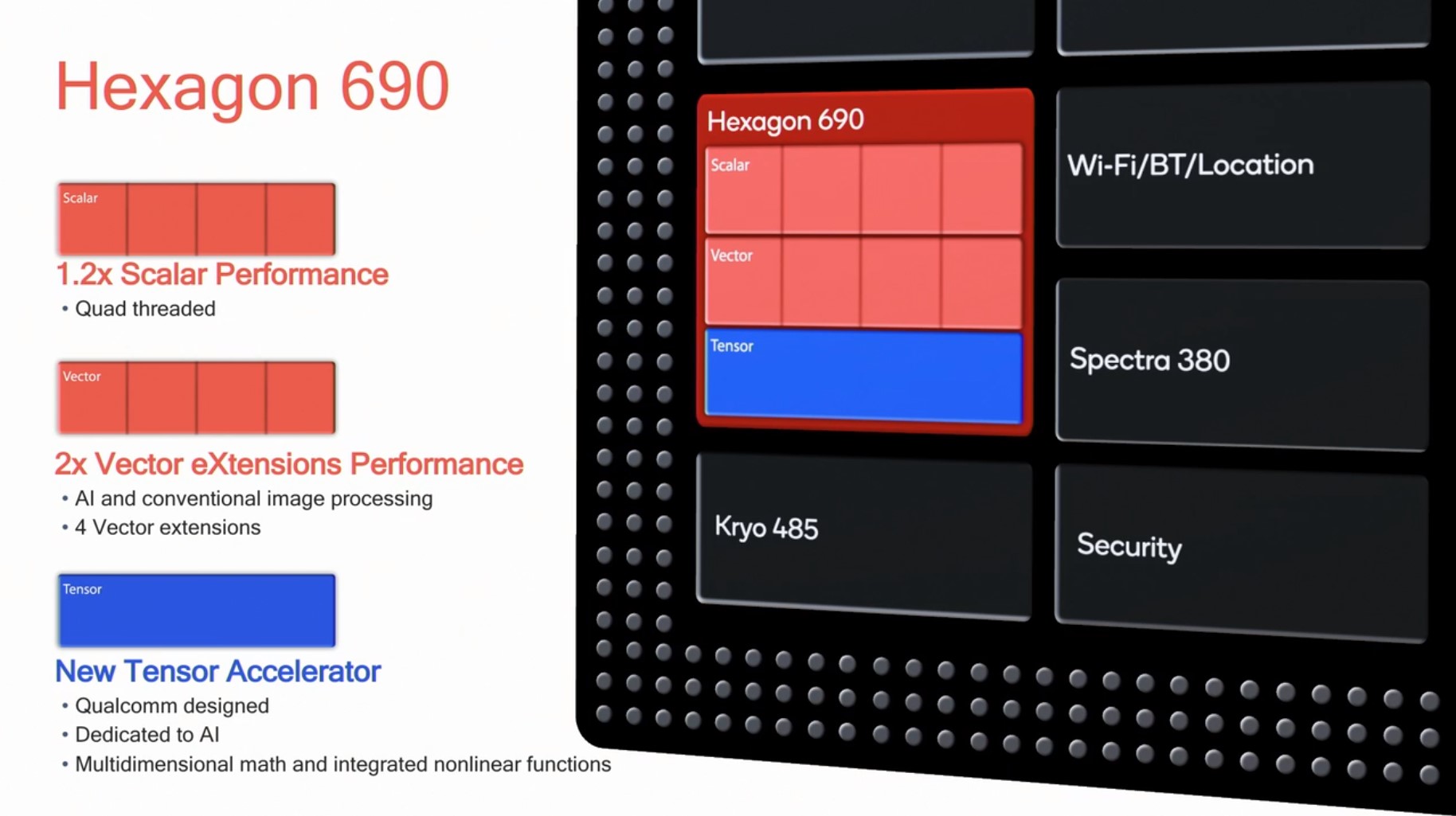
The new unit doubles its vector pipelines, essentially doubling performance for traditional image processing tasks as well as machine inferencing workloads. Most importantly, Qualcomm now includes a dedicated “Tensor Accelerator” block which promises to even better offload inferencing tasks.
I’ve queried Qualcomm about the new Tensor Accelerator, and got some interesting answers. First of all- Qualcomm isn’t willing to disclose more about the performance of this IP block; the company had advertised a total of “7 TOPS” computing power on the part of the platform, but they would not dissect this figure and attribute it individually to each IP block.
What was actually most surprising however was the API situation for the new Tensor accelerator. Unfortunately, the block will not be exposed to the NNAPI until sometime later in the year for Android Q, and for the time being the accelerator is only exposed via in-house frameworks. What this means is that none of our very limited set of “AI” benchmarks is able to actually test the Tensor block, and most of what we’re going to see in terms of results are merely improvements on the side of the Hexagon’s vector cores.
Inference Performance
First off, we start off with “AiBenchmark” – we first starred the new workload in our Mate 20 review, to quote myself:
“AI-Benchmark” is a new tool developed by Andrey Ignatov from the Computer Vision Lab at ETH Zürich in Switzerland. The new benchmark application, is as far as I’m aware, one of the first to make extensive use of Android’s new NNAPI, rather than relying on each SoC vendor’s own SDK tools and APIs. This is an important distinction to AIMark, as AI-Benchmark should be better able to accurately represent the resulting NN performance as expected from an application which uses the NNAPI.
Andrey extensive documents the workloads such as the NN models used as well as what their function is, and has also published a paper on his methods and findings.
One thing to keep in mind, is that the NNAPI isn’t just some universal translation layer that is able to magically run a neural network model on an NPU, but the API as well as the SoC vendor’s underlying driver must be able to support the exposed functions and be able to run this on the IP block. The distinction here lies between models which use features that are to date not yet supported by the NNAPI, and thus have to fall back to a CPU implementation, and models which can be hardware accelerated and operate on quantized INT8 or FP16 data. There’s also models relying on FP32 data, and here again depending on the underlying driver this can be either run on the CPU or for example on the GPU.
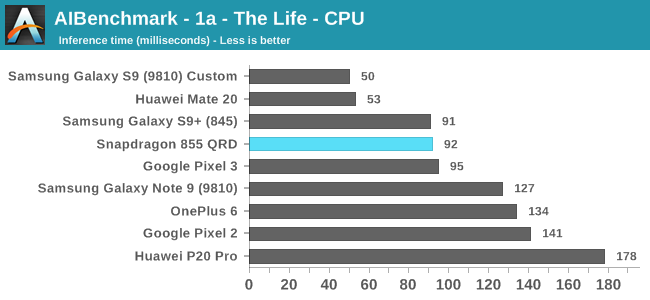

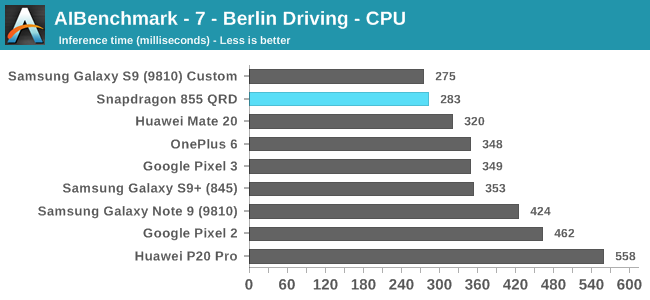
In the first set of workloads which I’ve categorised by being run on the CPU, we see the Snapdragon 855 perform well, although it’s not exactly extraordinary. Performance here is much more impacted by the scheduler of the system and exactly how fast the CPU is allowed to get to its maximum operating performance point, as the workload is of a short burst nature.
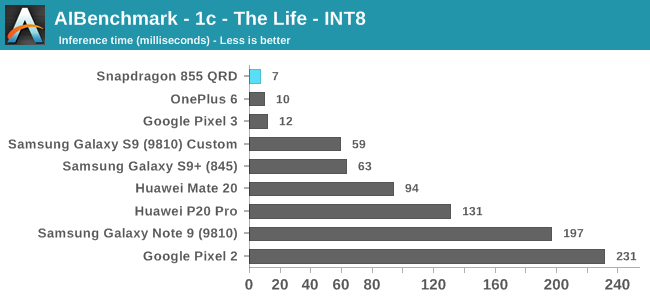

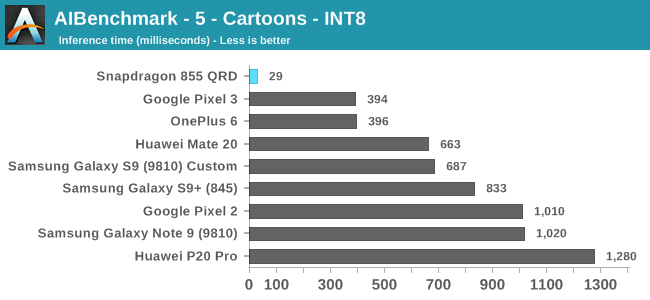
Moving onto the 8-bit integer quantised models, these are for most devices hardware accelerated. The Snapdragon 855’s performance here is leading in all benchmarks. In the Pioneers benchmark we more clearly see the doubling of the performance of the HVX units as the new hardware posts inference times little under half the time of the Snapdragon 845.
The Cartoons benchmark here is interesting as it showcases the API and driver aspect of NNAPI benchmarks: The Snapdragon 855 here seems to have massively better acceleration compared to its predecessors and competing devices. It might be that Qualcomm has notably improved its drivers here and is much better able to take advantage of the hardware, compared to the past chipset.
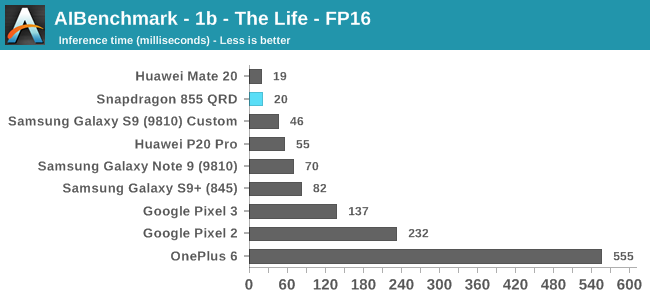


The FP16 workloads finally see some competition for Qualcomm as the Kirin’s NPU exposes support for its hardware here. Qualcomm should be running these workloads on the GPU, and here we see massive gains as the new platform’s NNAPI capability is much more mature.

The FP32 workload sees a similar improvement for the Snapdragon 855; here Qualcomm finally is able to take full advantage of GPU acceleration which gives the new chipset a considerable lead.
AIMark
Alongside AIBenchmark, it still might be useful to have comparisons with AIMark. This benchmark rather than using NNAPI, uses Qualcomm’s SNPE framework for acceleration. Also this gives us a rare comparison against Apple’s iPhones where the benchmark makes use of CoreML for acceleration.
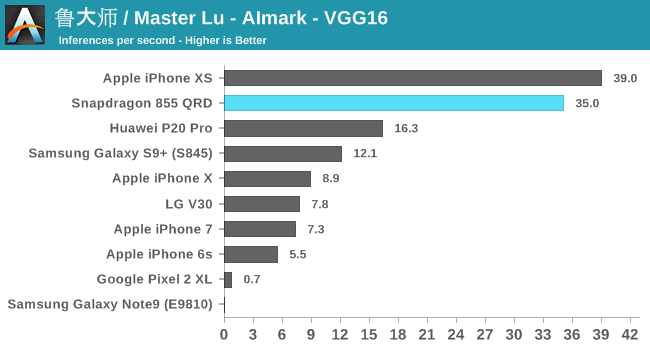
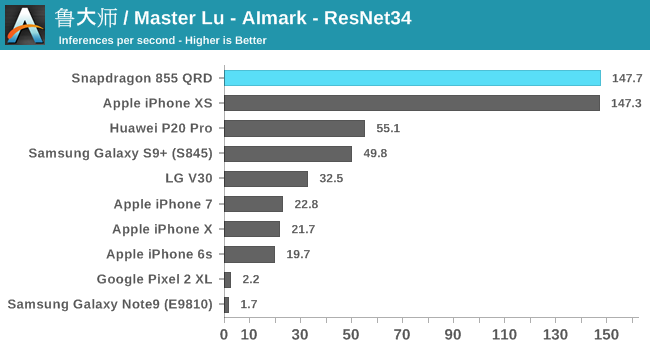
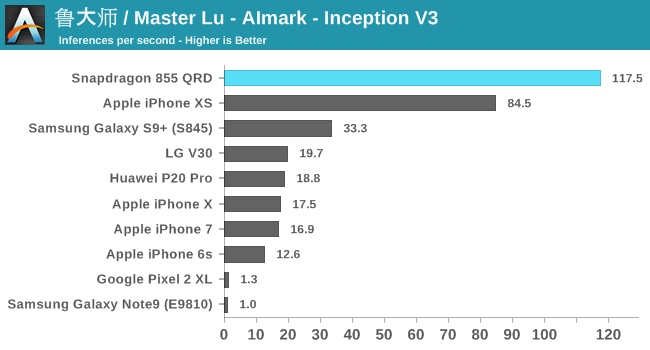
Overall, the Snapdragon 855 is able to post 2.5-3x performance boosts over the Snapdragon 845.
At the event, Qualcomm also showcased an in-house benchmark running InceptionV3 which was accelerated by both the HVX units as well as the new Tensor block. Here the phone was able to achieve 148 inferences/s – which although maybe apples to oranges, represents a 26% boost compared to the same model run in AIMark.
Overall, even though the Tensor accelerator wasn’t directly tested in today’s benchmark results, the Snapdragon 855’s inference performance is outstanding due to the overall much improved driver stack as well as the doubling of the Hexagon’s vector execution units. It will be interesting to see what vendors do with this performance and we should definitely see some exciting camera applications in the future.








132 Comments
View All Comments
genekellyjr - Wednesday, January 16, 2019 - link
You might be clueless too! There weren't any "4k rendering" benchmarks in that link - but there were 4k encoding benchmarks.And as for that encoding performance you are apparently referencing, it is definitely using fixed function encoders - it's not the CPU performance as Geekbench tests use (and I want to stress cross-platform Geekbench isn't 1:1 scoring - you'll never find Andandtech comparing various CPU architectures with Geekbench as it even uses fixed function resources like AES in its crypto stuff). And the speeds the laptops show definitely point to a CPU encoder being used. A fixed function encoder will barely hit the CPU, while CPU encoding will max those cores at 100%. The CPU encoding is higher quality at the cost of heat and speed.
Recently Adobe updated Premier to support Intel's fixed function encoder (called quick sync) read here http://www.dvxuser.com/V6/showthread.php?362263-Ad... post #8 - and Rush may not have gotten that update yet or the benchmark site referenced didn't update their program https://www.laptopmag.com/reviews/laptops/new-ipad... but I managed to find a benchmark for the quick sync in Premier https://forums.creativecow.net/thread/335/101459 - and Intel's quick sync fixed function stuff is all relatively the same afaik so the desktop CPU has less of an impact - gives a 1:20 min 4K -> 1080p conversion at 91 sec w/ CPU and 45 sec w/ fixed function, scale that up to 12 min (x9) and we get 13:39 w/ CPU (it's a nice CPU, i7-8700K) and the fixed function encoder gets 6:45. It'll probably scale pretty linearly. So 6:45 vs 7:47 with fixed function encoding - which isn't comparing CPUs at all at this point but rather their fixed function encoder!
So the iPad has some nice hardware, sure, but it's not outperforming Intel's brand new MB Pro 13" by leaps and bounds. They'll probably be about the same speed with fixed function encoding and the MB Pro 13" will win in a non-encoder setting thanks to its increased TDP.
darkich - Friday, January 18, 2019 - link
Okay.. So in short, the A12X is "about the same" in CPU performance as Intel's actively cooled, CPU-specific and twice more power hungry chip while also having a 1+TFLOPS GPU, 4G modem and advanced ISP on the same die.Overall, if that is what you call "nice", then Intel's hardware is what?
Trash.
Rudde - Friday, January 18, 2019 - link
Let's compare Intel i7-8500Y and Apple A12X. The i7-8500Y is a dual core 5W 14nm notebook/tablet processor. A12X is a octa core 7nm tablet processor with unknown power usage. 8500Y uses the x86-64 instruction set, while A12X uses ARMv8. They have very few benchmarks in common, which introduces notable amounts of uncertainty.Let's start with Geekbench 4.1/4.2 Single threaded:
8500Y scored 4885 and A12X 4993. A12X leads with 2%, which is within margin of error.
Same benchmark, but multithreaded:
8500Y scored 8225 and A12X 17866. A12X demolishes the dual core with 117% higher performance. This is clearly because of the 4-core-cluster in A12X having double core count compared with the dual core 8500Y.
Next up we have Mozilla Kraken 1.1 showing browser performance:
8500Y scores 1822ms and A12X 609ms. The A12X took 67% less time to complete the task, which amounts to a 199% increase in performance.
Octane V2 is another browser performance benchmark:
8500Y scores 24567 and A12X 45080. A12X bests the Intel cpu by 83%.
3D Mark has two versions of Ice Storm Physics and unfortunately our processors use different versions. They use the same resolution however.
8500Y scores 25064 in standard physics and A12X 39393 in unlimited physics. A12X scores a 57% lead.
It's hard to establish system performance with such a limited amount of benchmarks. Geekbench and 3DMark are synthetics and the two others show browser performance.
The processors are equal in ST, but the A12Xs higher core count allows it to double the 8500Ys MT score. The A12X outpaces the 8500Y in 3dMark. The A12X is clearly superior in browser performance. Apples A12 drops closer to the Intel in synthetics, but performs similar to it's larger sibling in web benchmarks.
Winner: A12X
Nemaca - Tuesday, January 15, 2019 - link
Overall, the 855 was thought to be head and shoulders above Kirin, but it seems that it will be on the same level at best.I'm typing this from my already heavily used mate 20pro, so if the US wouldn't nuke Huawei global-wide right now, the Kirin would certainly push ahead, which I hope it will do, since it seems more competitive price-wise.
Huawei bypassed the power issue with larger batteries, but to be honest, the Kirin doesn't seem to be that hungry anyway.
For me, the 855 is a letdown, I was hoping for more, but it seems my mate20pro will be relevant for longer then I thought, so not too bad of a news, I guess.
Thank you, Andrei, for the in-depth review!
Achtung_BG - Wednesday, January 16, 2019 - link
Snapdragon 855 .......https://youtu.be/mqFLXayD6e8
darkich - Tuesday, January 15, 2019 - link
This here proves once and for all that your system performance benchmarks are just bogus and irrelevant.Are we seriously supposed to believe that Snapdragon actually made a lower performing chipset than their previous one?
BS
darkich - Tuesday, January 15, 2019 - link
*Qualcomm, not SnapdragonIcehawk - Tuesday, January 15, 2019 - link
It's happened before in the chase for efficiencynpp - Tuesday, January 15, 2019 - link
I really doubt we’ll see battery life improve much with this generation. Hint - 5G. Maybe that’s why 855 focuses on overall efficiency, and the GPU gains are modest. Let’s hope I’m wrong.Impulses - Tuesday, January 15, 2019 - link
Yeah, that's the big wrench in the works... Hopefully there's at least *some* flagships without 5G! Though I doubt I'll be looking for an upgrade from my Pixel 3 this year or next.