The Snapdragon 855 Performance Preview: Setting the Stage for Flagship Android 2019
by Andrei Frumusanu on January 15, 2019 8:00 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- SoCs
- 7nm
- Snapdragon 855
Inference Performance: Good, But Missing Tensor APIs
Beyond CPU and GPU, the one aspect of the Snapdragon 855 that Qualcomm made a lot of noise about is the new Hexagon 690 accelerator block.
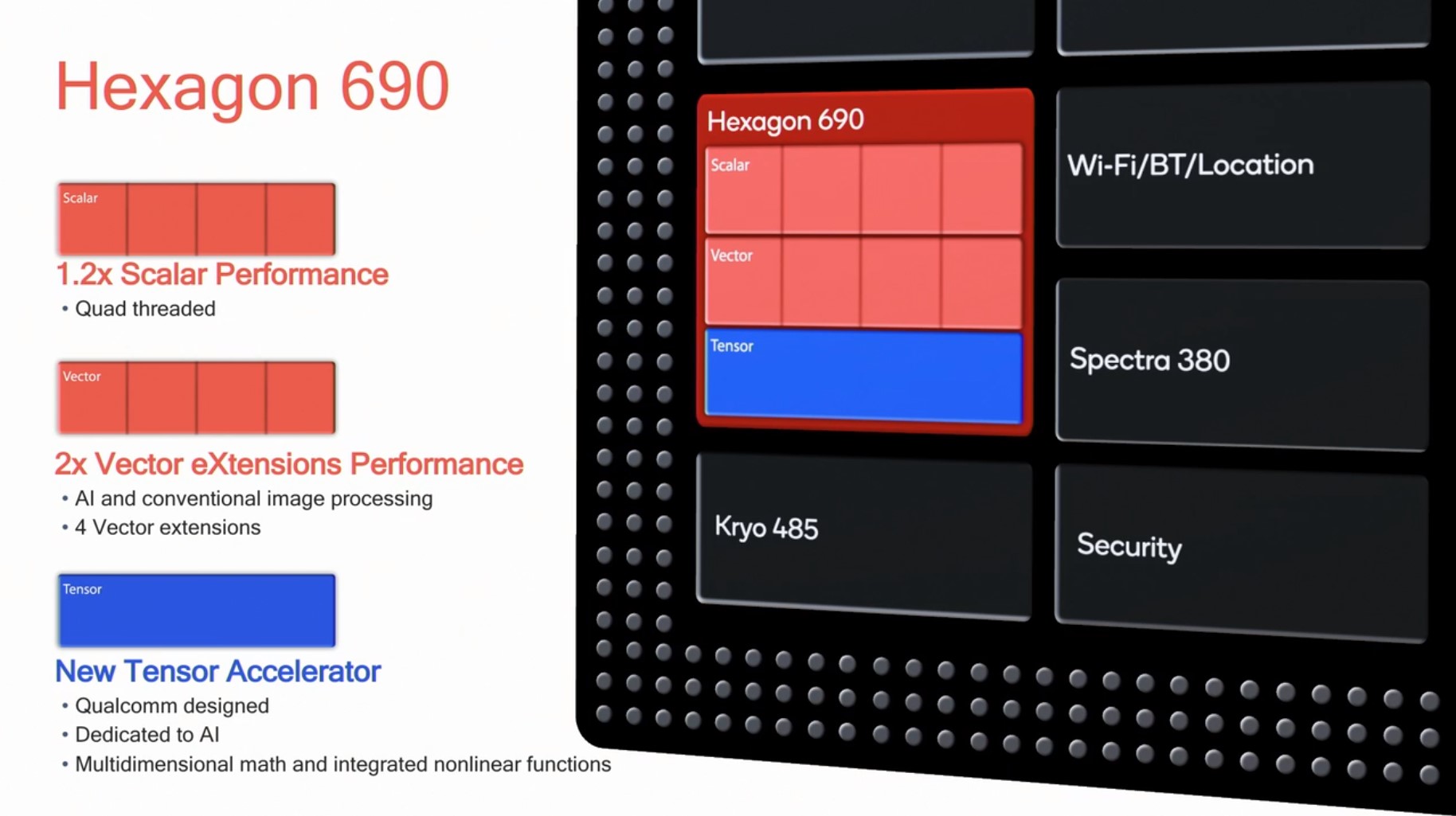
The new unit doubles its vector pipelines, essentially doubling performance for traditional image processing tasks as well as machine inferencing workloads. Most importantly, Qualcomm now includes a dedicated “Tensor Accelerator” block which promises to even better offload inferencing tasks.
I’ve queried Qualcomm about the new Tensor Accelerator, and got some interesting answers. First of all- Qualcomm isn’t willing to disclose more about the performance of this IP block; the company had advertised a total of “7 TOPS” computing power on the part of the platform, but they would not dissect this figure and attribute it individually to each IP block.
What was actually most surprising however was the API situation for the new Tensor accelerator. Unfortunately, the block will not be exposed to the NNAPI until sometime later in the year for Android Q, and for the time being the accelerator is only exposed via in-house frameworks. What this means is that none of our very limited set of “AI” benchmarks is able to actually test the Tensor block, and most of what we’re going to see in terms of results are merely improvements on the side of the Hexagon’s vector cores.
Inference Performance
First off, we start off with “AiBenchmark” – we first starred the new workload in our Mate 20 review, to quote myself:
“AI-Benchmark” is a new tool developed by Andrey Ignatov from the Computer Vision Lab at ETH Zürich in Switzerland. The new benchmark application, is as far as I’m aware, one of the first to make extensive use of Android’s new NNAPI, rather than relying on each SoC vendor’s own SDK tools and APIs. This is an important distinction to AIMark, as AI-Benchmark should be better able to accurately represent the resulting NN performance as expected from an application which uses the NNAPI.
Andrey extensive documents the workloads such as the NN models used as well as what their function is, and has also published a paper on his methods and findings.
One thing to keep in mind, is that the NNAPI isn’t just some universal translation layer that is able to magically run a neural network model on an NPU, but the API as well as the SoC vendor’s underlying driver must be able to support the exposed functions and be able to run this on the IP block. The distinction here lies between models which use features that are to date not yet supported by the NNAPI, and thus have to fall back to a CPU implementation, and models which can be hardware accelerated and operate on quantized INT8 or FP16 data. There’s also models relying on FP32 data, and here again depending on the underlying driver this can be either run on the CPU or for example on the GPU.
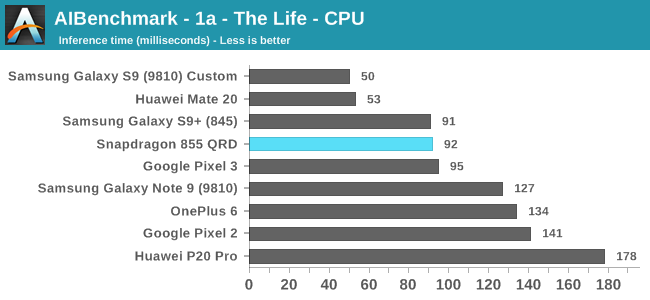

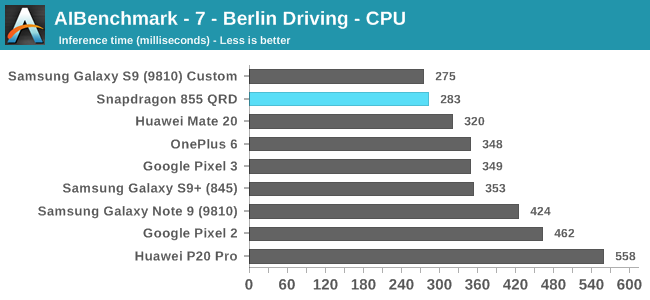
In the first set of workloads which I’ve categorised by being run on the CPU, we see the Snapdragon 855 perform well, although it’s not exactly extraordinary. Performance here is much more impacted by the scheduler of the system and exactly how fast the CPU is allowed to get to its maximum operating performance point, as the workload is of a short burst nature.
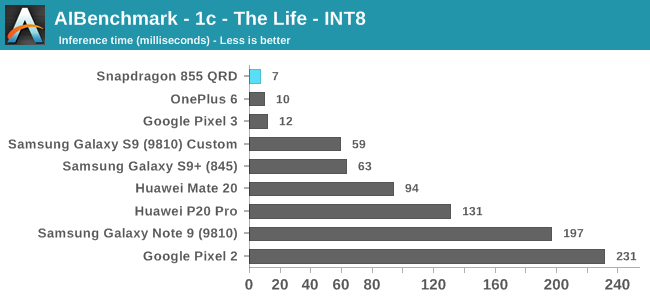

Moving onto the 8-bit integer quantised models, these are for most devices hardware accelerated. The Snapdragon 855’s performance here is leading in all benchmarks. In the Pioneers benchmark we more clearly see the doubling of the performance of the HVX units as the new hardware posts inference times little under half the time of the Snapdragon 845.
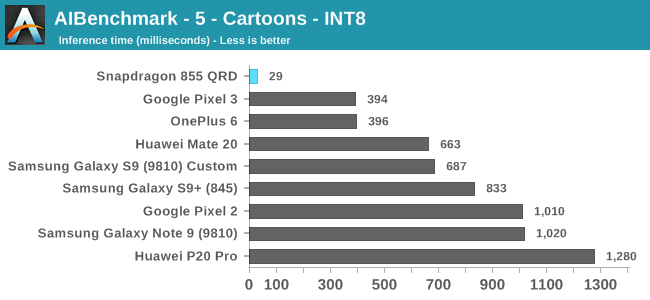
The Cartoons benchmark here is interesting as it showcases the API and driver aspect of NNAPI benchmarks: The Snapdragon 855 here seems to have massively better acceleration compared to its predecessors and competing devices. It might be that Qualcomm has notably improved its drivers here and is much better able to take advantage of the hardware, compared to the past chipset.
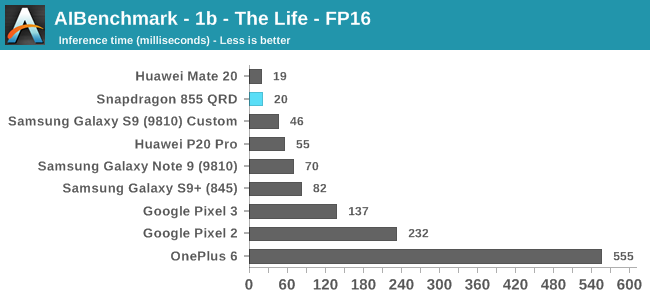


The FP16 workloads finally see some competition for Qualcomm as the Kirin’s NPU exposes support for its hardware here. Qualcomm should be running these workloads on the GPU, and here we see massive gains as the new platform’s NNAPI capability is much more mature.

The FP32 workload sees a similar improvement for the Snapdragon 855; here Qualcomm finally is able to take full advantage of GPU acceleration which gives the new chipset a considerable lead.
AIMark
Alongside AIBenchmark, it still might be useful to have comparisons with AIMark. This benchmark rather than using NNAPI, uses Qualcomm’s SNPE framework for acceleration. Also this gives us a rare comparison against Apple’s iPhones where the benchmark makes use of CoreML for acceleration.
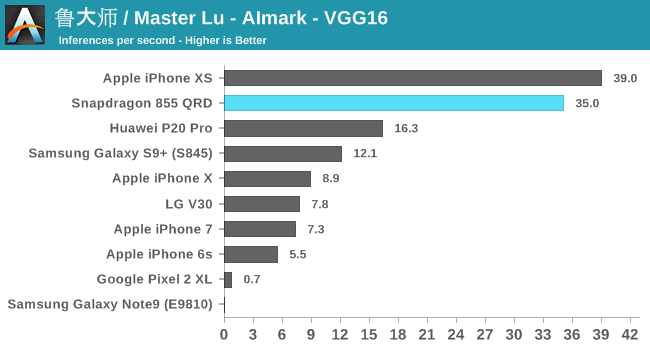
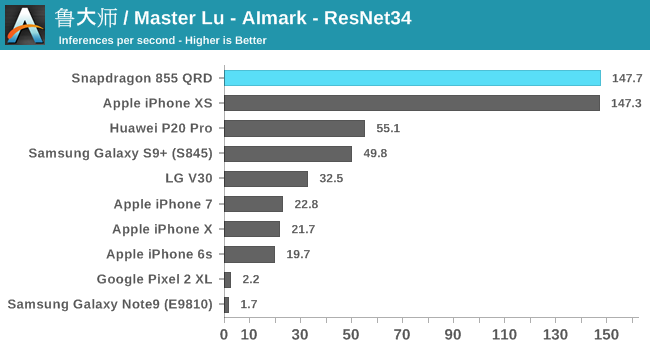
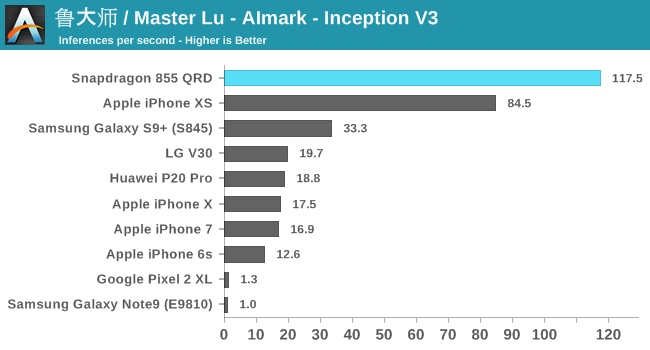
Overall, the Snapdragon 855 is able to post 2.5-3x performance boosts over the Snapdragon 845.
At the event, Qualcomm also showcased an in-house benchmark running InceptionV3 which was accelerated by both the HVX units as well as the new Tensor block. Here the phone was able to achieve 148 inferences/s – which although maybe apples to oranges, represents a 26% boost compared to the same model run in AIMark.
Overall, even though the Tensor accelerator wasn’t directly tested in today’s benchmark results, the Snapdragon 855’s inference performance is outstanding due to the overall much improved driver stack as well as the doubling of the Hexagon’s vector execution units. It will be interesting to see what vendors do with this performance and we should definitely see some exciting camera applications in the future.








132 Comments
View All Comments
tipoo - Wednesday, January 16, 2019 - link
That would be physics.id4andrei - Wednesday, January 16, 2019 - link
Indeed. When you provide a small battery to a powerful SoC you get degraded batteries before the two year warranty(Europe). Problem is Apple's own store diagnostics validated batteries from throttled iphones.melgross - Wednesday, January 16, 2019 - link
Better batteries than Android phones.id4andrei - Wednesday, January 16, 2019 - link
Millions of iphone users walked and some keep walking around with throttled iphones. Let that sink in.Trackster11230 - Thursday, January 17, 2019 - link
Based on the context of this thread, having a throttled SOC that's still well ahead of the competition would still provide a great experience. You dug yourself into a hole with that comment.Sailor23M - Thursday, January 24, 2019 - link
“The” iphone :-)Solandri - Friday, February 15, 2019 - link
What's interesting to me is that its performance per Watt seems to be pretty close to the A12. Which more or less confirms what I've suspected for a while - that a large part of the superior performance of the A12 is simply due to Apple getting priority at the newer 7nm fabs. While the A12 vs 845 comparison made chronological sense (in that both were available in phones at the same time), the A12 was 7nm while the 845 was 10nm.jonrevis1985 - Sunday, February 17, 2019 - link
So true Oyeve, you could put a turbo charged v8 in a ford pinto but it will only ever be a pinto.goatfajitas - Tuesday, January 15, 2019 - link
Catch Apple, no. Alot of the performance is tight integration, not actual CPU speed. If Apple had used Qualcom Snapdragon and Android OEM's had the A12, Apple would still be faster at benchmarks. Take it all with a grain or 10 of salt.Ironchef3500 - Tuesday, January 15, 2019 - link
Very true