Supermicro Shows Off Intel Nervana NNP-T Servers: 8-Way PCIe and OAM
by Dr. Ian Cutress on December 4, 2019 3:00 PM EST
One of the key elements to deep learning and training is lots of very dense compute, as well as the dense servers to go through the computation. Intel’s Nervana NNP-T Spring Crest silicon, which we saw at Hot Chips earlier this year, is the ‘big training silicon’ that came out of the acquisition with Nervana: a 680 mm2 built on TSMC 16nm with CoWoS with four stacks of HBM2. The servers using this silicon are now starting to appear, and we caught sight of two at the Supermicro booth at Supercomputing.


To start the week, Supermicro showed off its first server using the NNP-T hardware, all based on PCIe cards. As one might imagine, these fit into any server that was previously designed to accommodate GPUs, and so Supermicro’s system is a very typical 2P unit with 8 cards in a 4U design. The cards talk to each other, with 3.58 Tbps total bi-directional bandwidth per chip, and off-chip connections supporting scalability up to 1024 nodes. As noted by the single 8-pin PCIe power per card, it means that each card has a peak power of 225W as per PCIe standards.


Later in the week, we were told by Supermicro that they had been given permission to show off the 8-way OAM (OCP Accelerator Module) version of the server, which keeps the chip-to-chip communications through the PCB of the baseboard, rather than using PCIe card-to-card like connectors. This also allows for substantial air cooling implementations, and compatibility with the OCP standards, as well as modularization.

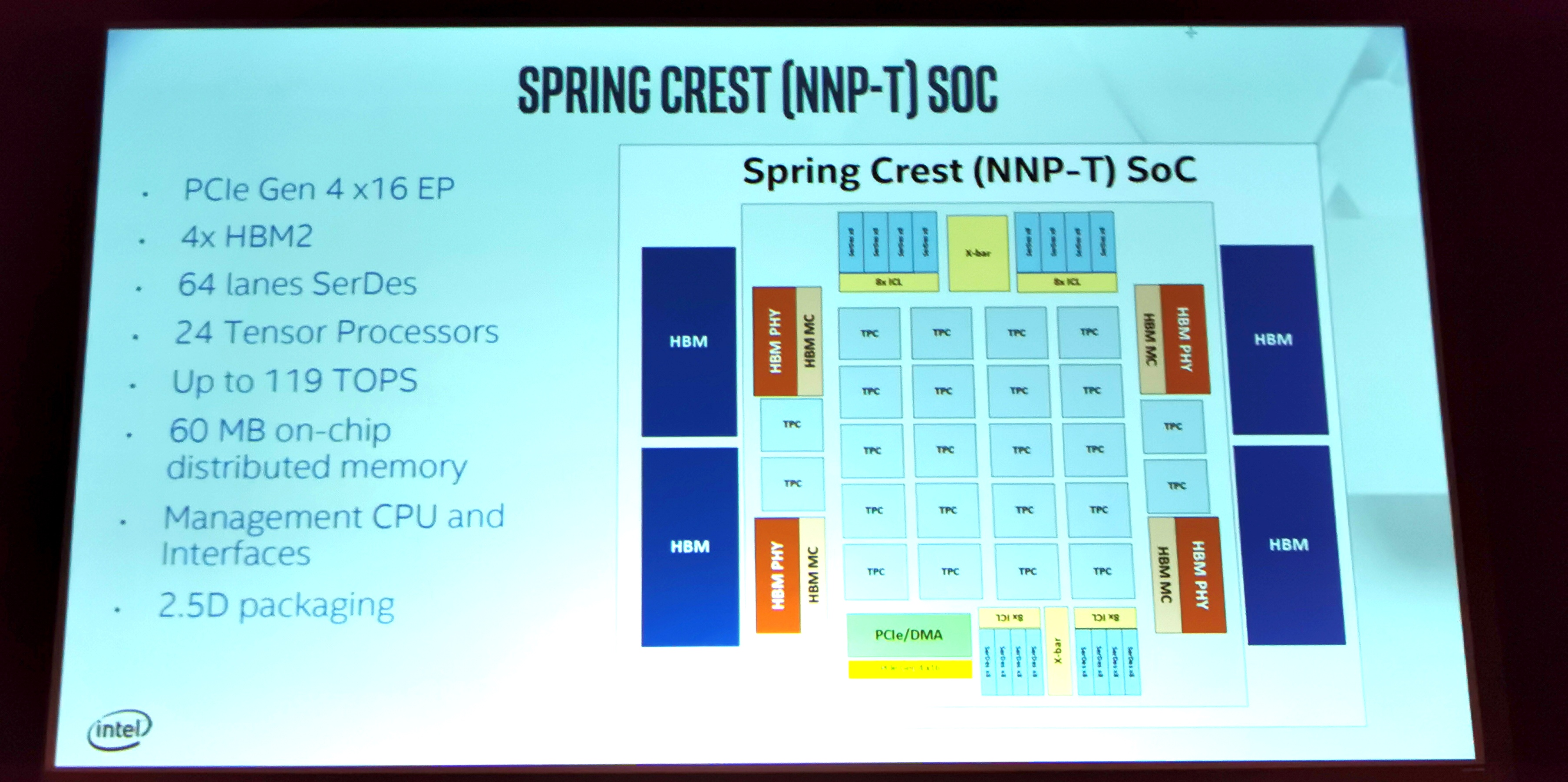
The chip is Intel’s first to support bfloat16 numerics for training in deep learning. Each chip supports up to 119 TOPs, with 60 MB of on-chip memory and 24 dedicated ‘tensor’ processing clusters which have dual 32x32 matrix multiply arrays. The chip has a total of 27 billion transistors, and the cores run at 1.1 GHz. This is supported by 32 GB of HBM2-2400 memory, and technically the PCIe connection is a PCIe 4.0 x16 connection, however Intel does not have CPUs to support this yet.
We were told that for this sort of compute, in order to drive it all, some training customers are moving up from 2P per head node up to 4P, and bigger installations such as Facebook are already using 8P systems to drive their deep learning and training hardware.
Supermicro states that their NNP-T systems are ready for deployment.








15 Comments
View All Comments
Ian Cutress - Thursday, December 5, 2019 - link
Correct.Gondalf - Thursday, December 5, 2019 - link
You are right. In last few years most advanced Intel server cpus are at big farms first (two quarters first) then common mortal volume shipment.Not surprised Facebook already has Ice lake SP on racks with PCIe4 running and Cooper Lake 56 cores from a long time for other applications.
The_Assimilator - Thursday, December 5, 2019 - link
"acquisition with Nervana"I believe you meant "of".
name99 - Friday, December 6, 2019 - link
Ian, how do you square all this happy talk of Nervana (and the more specialized Movidius and Mobileye) with the acquisition of Habana?What does Habana bring to the table that INTC doesn't already have? (For example, is Habana known to provide much better support for Transformer type architectures compared to anything Intel currently has?)
nn68 - Friday, December 13, 2019 - link
My guess is, software. Habana Labs seem to have a pretty solid portfolio of libraries and whatnot.