64 Cores of Rendering Madness: The AMD Threadripper Pro 3995WX Review
by Dr. Ian Cutress on February 9, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Lenovo
- ThinkStation
- Threadripper Pro
- WRX80
- 3995WX
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
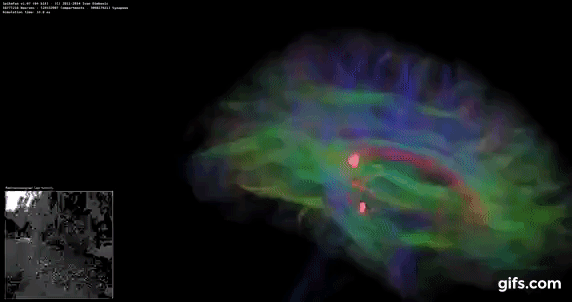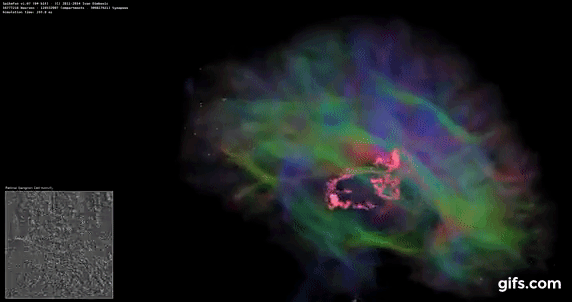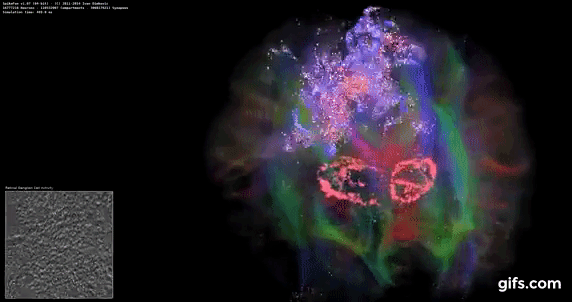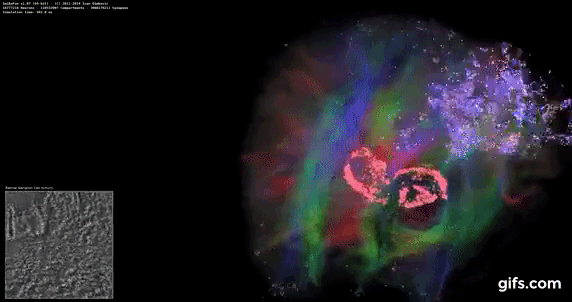
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.

This test prefers monolithic silicon with proportionally lots of memory bandwidth, which means that we get somewhat of an equalling of results here. The top result in our benchmark database is actually single chiplet Ryzen.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
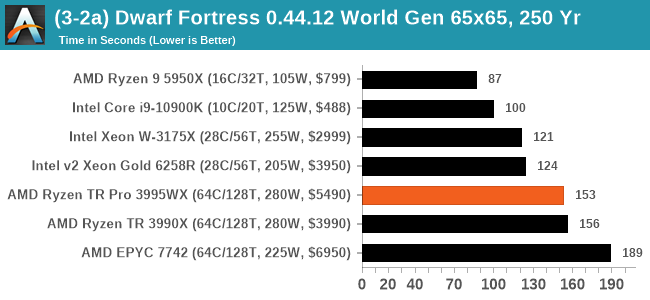


Dwarf Fortress is mainly single-thread limiting, hence the 64-core models at the back end of the queue. The TR parts are still a good bit faster than the EPYC.
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.

Similarly here, single thread performance matters.








118 Comments
View All Comments
brucethemoose - Tuesday, February 9, 2021 - link
There are large efforts in various communities, from Rust and C++ to Linux distros and game engines, to improve autovectorization.This means that more software should support AVXwhatever with minimal or no support from devs as time goes on.
Also, one can"t always just "go to the GPU." Video encoding is a great example where this won't work.
RSAUser - Wednesday, February 10, 2021 - link
NVENC seems to work pretty well.eastcoast_pete - Wednesday, February 10, 2021 - link
The newest generation of NVENC (since Turing) is indeed quite capable at encoding and transcoding to AVC and h265. That ASIC has come a long way, and is really fast. However, for customized encoding situations, the story shifts; that's where CPU-based encoding comes into its own. Also, if you want AV1 encoding, we're still OOL on GPUs; if that has changed, I'd love to know. Lastly, a lot of the work these workstations are used for is CGI and editing, and for those, a combination of lots of RAM, many-core CPUs like these here and 1-2 higher end GPUs is generally what people use who do this for a living.GeoffreyA - Friday, February 12, 2021 - link
NVENC, VCE, etc., work brilliantly when it comes to speed, but if one is aiming for best quality or size, it's best to go for software encoding. x264 does support a bit of OpenCL acceleration but there's hardly any gain, and it's not enabled by default. Also, even when AV1 ASICs are added, I've got a feeling it'll fall well below software encoding.phoenix_rizzen - Tuesday, February 9, 2021 - link
More like, unless you absolutely NEED AVX-512 support, there's absolutely no reason to use an Intel setup.Pick a Ryzen, Threadripper, or EPYC depending on your needs, they'll all be a better value/performer than anything Intel currently has on the market.
twtech - Tuesday, February 9, 2021 - link
It's workload-dependent, and what you're looking for. While regular TR supports ECC, it doesn't support registered ECC, which is 99% of ECC memory. The 8 memory channels also make a big difference in some workloads, such as compiling code. Also the TR Pro has a lot more PCIE lanes, as well as better support for business/corporate management.So I agree with your statement if you are a solo operator with a workload that is not only not very memory dependent, but not very memory-bandwidth dependent either.
eastcoast_pete - Wednesday, February 10, 2021 - link
For the use case covered here (customized CPU rendering), those many cores are hard to beat. In that scenario, the main competitors for the TR pros are the upcoming, Zen 3-based Epyc and non-pro TRs. Unfortunately, Intel is still way behind. What I wonder about also is whether some of these rendering suites are also available for ARM's Neoverse arch; some of those 128+ core CPUs might be quite competitive, if the software exists.wumpus - Wednesday, February 10, 2021 - link
I'm guessing that a lot of the times that feature will be ECC. How many tasks worth doing on a 5-figure workstation are worth having botched bytes thanks to a memory error?Granted, a lot of the times that ECC is needed are also going to be the >256GB cases, but ECC is pretty important (if only to known that there *wasn't* a memory error).
The Hardcard - Tuesday, February 9, 2021 - link
While the EPYC name is epic, it doesn’t scream “for heavyweight computational workloads” like Threadripper does. Both names are candidates for bonuses, but whoever thought up Threadriipper should get the bigger one.If the same person is responsible for both names, then the title AMD Marketing Fellow was earned.
Oxford Guy - Tuesday, February 9, 2021 - link
Threadripper is even more corny than EPYC. Neither inspire much confidence from a professional standpoint, sounding like gamer speak.