64 Cores of Rendering Madness: The AMD Threadripper Pro 3995WX Review
by Dr. Ian Cutress on February 9, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Lenovo
- ThinkStation
- Threadripper Pro
- WRX80
- 3995WX
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
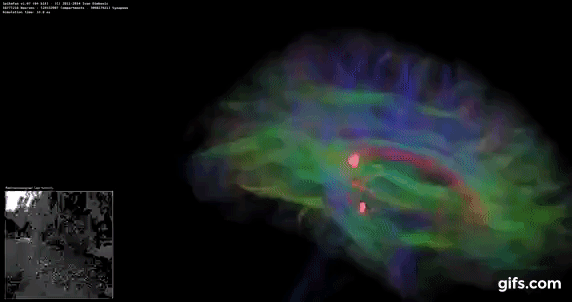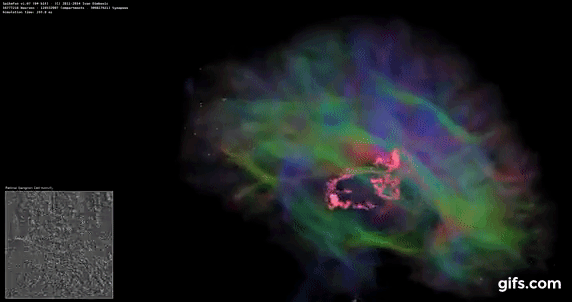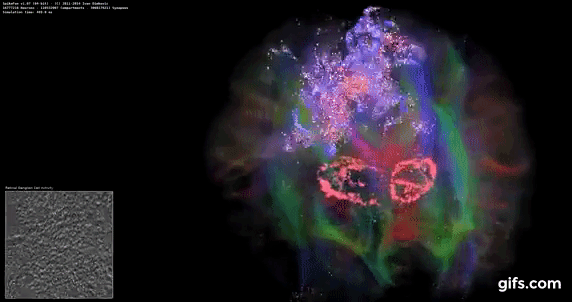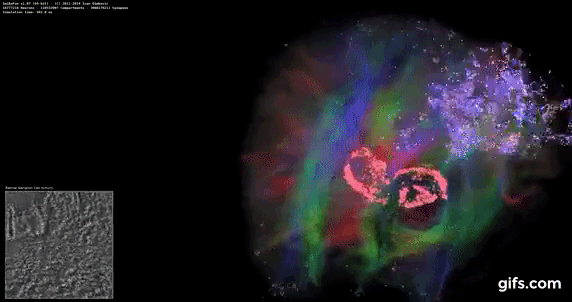
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.

This test prefers monolithic silicon with proportionally lots of memory bandwidth, which means that we get somewhat of an equalling of results here. The top result in our benchmark database is actually single chiplet Ryzen.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
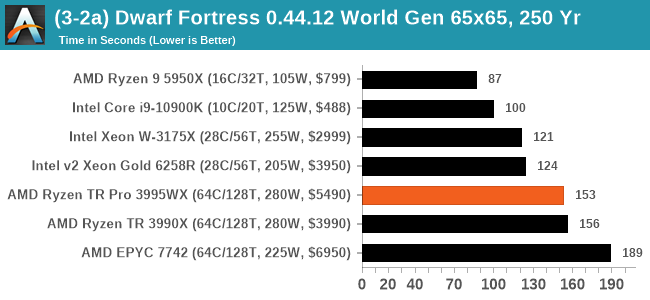


Dwarf Fortress is mainly single-thread limiting, hence the 64-core models at the back end of the queue. The TR parts are still a good bit faster than the EPYC.
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.

Similarly here, single thread performance matters.








118 Comments
View All Comments
avb122 - Tuesday, February 9, 2021 - link
Those cases do not matter unless you are checking that the result is the same as a golden reference. Otherwise the image it creates is just as if the object it was rendering moved 10 micrometers. To our brain it not doesn't matter.Being off by one bit with FP32 for geometry is about the same magnitude as modeling light as a partial instead of a wave. For color intensity, one bit of FP32 is less than one photon in real world cases.
But, CPUs and GPUs all get the same answer when doing the same FP32 arithmetic. The programmer can choose to do something else like use lossy texture compression or goofy rounding modes.
avb122 - Tuesday, February 9, 2021 - link
It's not because of the hardware. AMD and NVIDIA's GPUs have IEEE complient FPUs. So, they get the same answer as the CPU when using the same algorithm.With CUDA, the same C or C++ code doing computations can run on the CPU and GPU and get the same answer.
The REAL reasons to not use a GPU are that the non-compete parts (threading, memory management, synchronization, etc.) are different on the GPU and not all GPUs support CUDA. Those are very good reasons. But it is not about the hardware. It is about the software ecosystem.
Also GPUs do not have a tiny amount of cache. They have more total cache than a CPU. The ratio of "threads" to cache is lower. That requires changing the size of the block that each "thread" operates on. Ultimately, GPUs have so much more internal and external bandwidth than a CPU that only extreme cases where everything fits in the CPUs' L1 caches buy not in the GPU's register file can a CPU have more bandwidth.
Ian's statement about wanting 36 bits so that it can do 12-bit color is way off. I only know CUDA and NVIDIA's OpenGL. For those, each color channel is represented by a non-SIMD register. Each color channel is then either an FP16 or FP32 value (before neural networks GPUs were not faster at FP16, it was just for memory capacity and bandwidth). Both cover 12-bit color space. Remember, games have had HDR for almost two decades.
Dug - Tuesday, February 9, 2021 - link
It's software.But sometimes you don't want perfect. It can work in your benefit depending on what end results you view and interpret.
Smell This - Tuesday, February 9, 2021 - link
Page 4
Cinebench R20
Paragraph below the first image
**Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. **
I do like my code clean ...
alpha754293 - Tuesday, February 9, 2021 - link
It's a pity that the processor and as a platform, you can buy a used dual EPYC 7702 server and still reap the multithreaded performance of 128-cores/256-threads moreso than you would be able to get out of this processor.I'd wished that this review actually included the results of a dual EPYC 7702/7742 system for the purposes of comparing the two, as I think that the dual EPYC 7702/7742 would still outperform this Threadripper Pro 3995WX.
Duncan Macdonald - Tuesday, February 9, 2021 - link
Given the benchmarks and the prices, the main reason for using the Threadripper Pro rather than the plain Threadripper is likely to be the higher memory capacity (2TB vs 256GB) .Even a small overclock on a standard Threadripper would allow it to be faster than a non-overclocked Threadripper Pro for any application that fits into 256GB.
twtech - Tuesday, February 9, 2021 - link
There are a couple other pretty significant differences that matter perf-wise in some scenarios - the Pro has 8-channel memory support, and more PCIE lanes.Significant differences not directly tied to performance include registered ECC support, and management tools for corporate security, which actually matters quite a bit with everyone working remotely.
WaltC - Tuesday, February 9, 2021 - link
On the whole, a nice review...;)Yes, it's fairly obvious that one CPU core does not equal one GPU core, as comparatively, the latter is wide and shallow and handles fewer instructions, IPC, etc. GPU cores are designed for a specific, narrow use case, whereas CPU cores are much deeper (in several ways) and designed for a much wider use case. It's nice that companies are designing programming languages to utilize GPUs as untapped computing resources, but the bottom line is that GPUs are designed primarily to accelerate 3d graphics and CPUs are designed for heavy, multi-use, multithreaded computation with a much deeper pipeline, etc. While it might make sense to use both GPUs and CPUs together in a more general computing case once the specific-case programming goals for each kind of processing hardware are reached, it makes no sense to use GPUs in place of CPUs or CPUs in place of GPUs. AMD has recently made no secret it is divulging its GPU line to provide more 3d-acceleration circuitry and less compute circuitry for gaming, and another branch that will include more CU circuitry and less gaming-use 3d-acceleration circuitry. 'bout time.
The software rendering of Crysis is a great example--an old, relatively slow 3d GPU accelerator with a CPU can bust the chops of even WX3995 CPUs *if* the 3995WX is tasked to rendering Crysis sans a 3d accelerator. When the Crysis-engine talks about how many cores and so on it will support, it's talking about using a 3d accelerator *with* a general-purpose CPU. That's what the engine is designed to do, actually. Take the CPU out and the engine won't run at all--trying to use the CPU as the API renderer and it's a crawl that no one wants...;) Most of all, using the CPU to "render" Crysis in software has no comparison to a CPU rendering a ray-traced scene, for instance. Whereas the CPU is rendering to a software D3d API in Crysis, ray-tracing is done by far more complex programming that will not be found in the Crysis engine (of course.)
I was surprised to read that Ian didn't think that 8-channel memory would add much of anything to performance beyond 4-channel support....;) Eh? It's the same principle as expecting 4-channel to outperform 2 channel, everything else being equal. Of course, it makes a difference--if it didn't there would be no sense in having 3995WX support 8 channels. No point at all...;)
Oxford Guy - Tuesday, February 9, 2021 - link
Yes, the same principle of expecting a dual core to outperform a single core — which is why single/core CPUs are still dominant.(Or, we could recognize that diminishing returns only begin to matter at a certain point.)
tyger11 - Tuesday, February 9, 2021 - link
Definitely waiting for the Zen 3 version of the 3955X. I'm fine with 16 cores.