Google Announces AMD Milan-based Cloud Instances - Out with SMT vCPUs?
by Andrei Frumusanu on June 17, 2021 11:00 AM EST- Posted in
- CPUs
- AMD
- Enterprise
- AWS
- Azure
- Milan
- Google Compute Cloud
Today, Google announced the planned introduction of their new set of “Tau” VMs, or T2D, in their Google Compute Engine VM offerings. The hardware consists of AMD’s new Milan processors – which is a welcome addition to Google’s offerings.
The biggest news of today’s announcement however was not Milan, but the fact of what Google is doing in terms of vCPUs, how this impacts performance, and the consequences it has in the cloud provider space – particularly in context of the new Arm server CPU competition.

Starting off with the most important data-point Google is presenting today, is that the new GCP Tau VMs showcase a staggering performance advantage over the competitor offerings from AWS and Azure. The comparison VM details are published here:
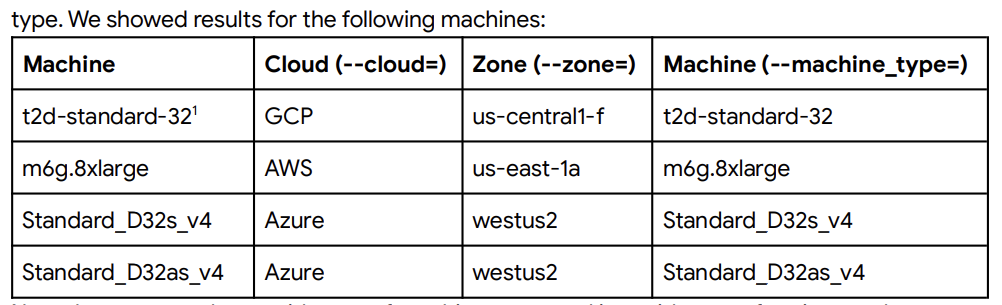
Google’s SPECrate2017_int methodology largely mimics our own internal usage of the test suite in terms of flags (A few differences like LTO and allocator linkage), but the most important figure comes down from the disclosure of the compilers, with Google stating that the +56% performance advantage over AWS’s Graviton2 comes from an AOCC run. They further disclose that a GCC run achieving a +25% performance advantage, which clarifies some aspects:
Note that we also tested with GCC using -O3, but we saw better performance with -Ofast on all machines tested. An interesting note is that while we saw a 56% estimated SPECrate®2017_int_base performance uplift on the t2d-standard-32 over the m6g.8xlarge when we used AMD's optimizing compiler, which could take advantage of the AMD architecture, we also saw a 25% performance uplift on the t2d-standard-32 over the m6g.8xlarge when using GCC 11.1 with the above flags for both machines.
Having this 25% figure in mind, we can fall back to our own internally tested data of the Graviton2 as well as the more recently tested AMD Milan flagship for a rough positioning of where things stand:
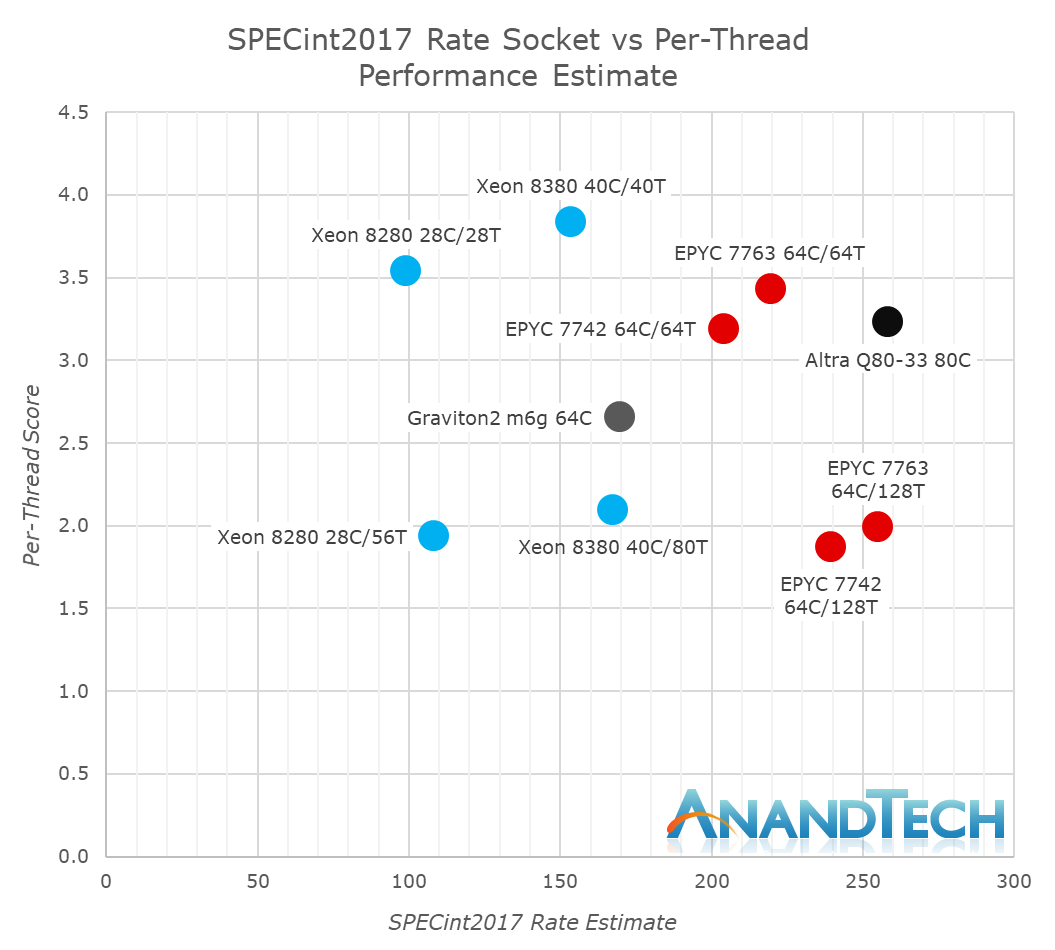
Google doesn’t disclose any details of what kind of SKU they are testing, however we do have 64-core and 32-core vCPU data on Graviton2, scoring estimated scores of 169.9 and 97.8 with per-thread scores of 2.65 and 2.16. Our internal numbers of an AMD EPYC 7763 (64 core 280W) CPU showcase an estimated score of 255 rate and 1.99 per thread with SMT, and 219 rate and 3.43 per thread for respectively 128 threads and 64 thread runs per socket. Scaling the scores down based on a thread count of 32 – based on what Google states here as vCPUs for the T2D instance, would get us to scores of either 63.8 with SMT, or 109.8 without SMT. The SMT run with 32 threads would be notably underperforming the Graviton2, however the non-SMT run would be +12 higher performance. We estimate that the actual scores in a 32-vCPU environment with less load on the rest of the SoC would be notably higher, and this would roughly match up with the company’s quoted +25 performance advantage.
And here lies the big surprise of today’s announcement: for Google's new Milan performance figures to make sense, it must mean that they are using instances with vCPU counts that actually match the physical core count – which has large implications on benchmarking and performance comparisons between instances of an equal vCPU count.
Notably, because Google is focusing on the Graviton2 comparison at AWS, I see this as a direct attack and response to Amazon’s and Arm’s cloud performance metric claims in regards to VMs with a given number of vCPUs. Indeed, even when we reviewed the Graviton2 last year, we made note of this discrepancy that when comparing cloud VM offerings to x86 cloud offerings which have SMT, and where a vCPU essentially just means you’re getting a logical core instead of a physical core, in contrast to the newer Arm-based Graviton2 instances. In effect, we had been benchmarking Arm CPUs with double the core counts vs the x86 incumbents at the same instance sizes. Actually, this is still what Google is doing today when comparing a 32vCPU Milan Tau VM against a Azure 32vCPU Cascade Lake VM – it’s a 32 core vs 16 core comparison, just the latter has SMT enabled.
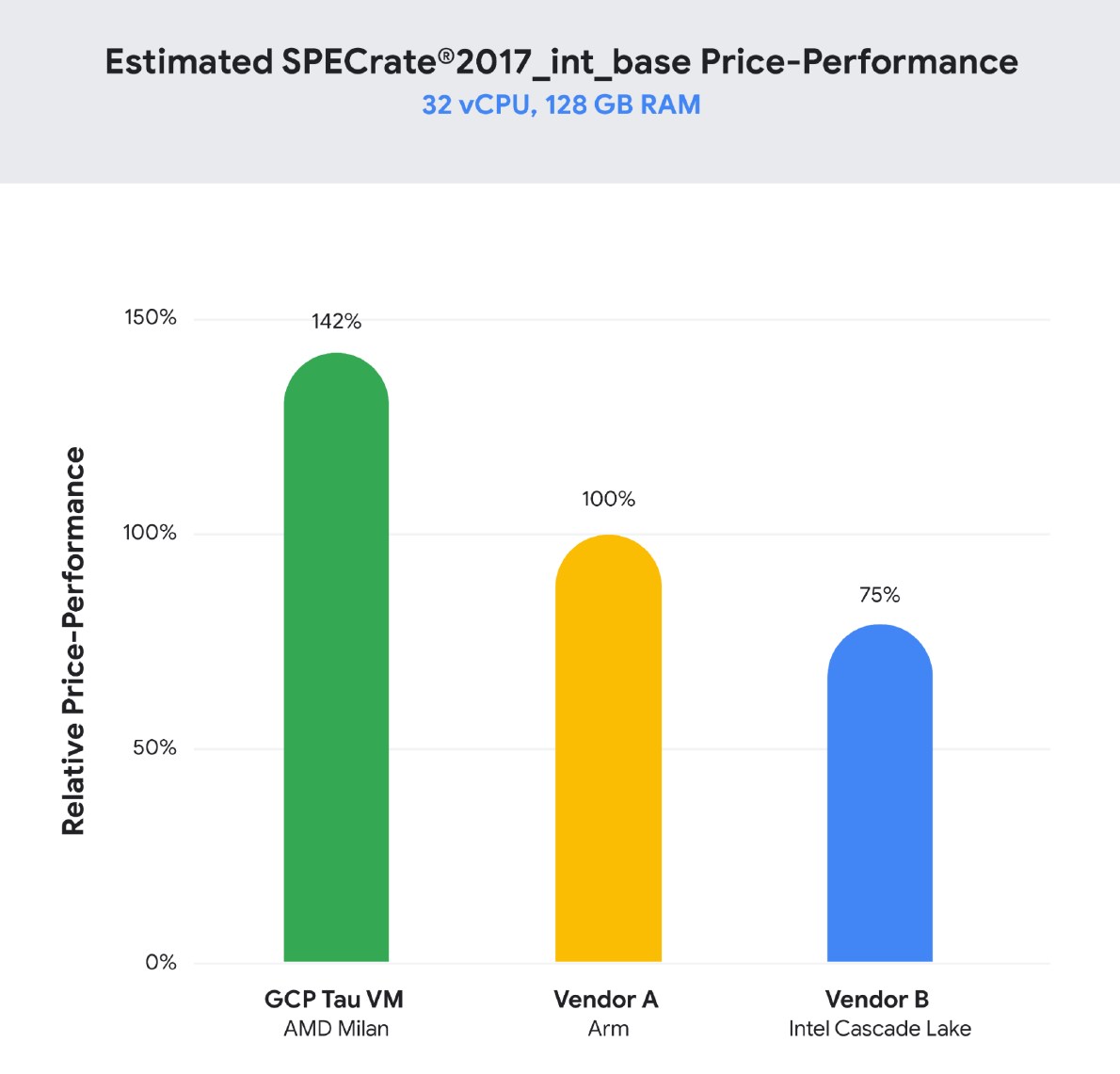
Because Google is now essentially levelling the playing field against the Arm-based Graviton2 VM instances at equal vCPU count, by actually having the same number of physical cores available, it means that it has no issues to compete in terms of performance with the Arm competitor, and naturally it also outperforms other cloud provider options where a vCPU is still only a logical SMT CPU.
Google is offering a 32vCPU T2D instance with 128GB of RAM at USD 1.35 per hour, compared to a comparable AWS instance of m6g.8xlarge with also 32vCPUs and 128GB of RAM at USD 1.23 per hour. While Google’s usage of AOCC to get to the higher performance figures compared to our GCC numbers play some role, and Milan’s performance is great, it’s really the fact that we seem to now be comparing physical cores to physical cores that really makes the new Tau VM instances special compared to the AWS and Azure offerings (physical to logical in the latter case).
In general, I applaud Google for the initiative here, as being offered only part of a core as a vCPU until now was a complete rip-off. In a sense, we also have to thank the new Arm competition in finally moving the ecosystem into bringing about what appears to be the beginning of the end of such questionable vCPU practices and VM offerings. It also wouldn’t have been possible without AMD’s new large core count CPU offerings. It will be interesting to see how AWS and Azure will respond in the future, as I feel Google is up-ending the cloud market in terms of pricing and value.








24 Comments
View All Comments
Kamen Rider Blade - Thursday, June 17, 2021 - link
I wonder how Intel's Server team feels that their Cascade Lake is placed @ a distant 3rd placeFunBunny2 - Thursday, June 17, 2021 - link
"Stop the steal!!""Stop the steal!!"
"Stop the steal!!"
drothgery - Thursday, June 17, 2021 - link
Seems odd to be comparing Milan vs Cascade Lake rather than Ice Lake, tbh, even if availability is still quite limited for Ice Lake - SP.kgardas - Friday, June 18, 2021 - link
Exactly! And even more odd is comparing X amd cores versus X/2 intel cores.Spunjji - Friday, June 18, 2021 - link
If you need more than one Intel server / socket to get that many cores then it's a relevant comparison, because the provider's costs will be tightly linked to how many servers they can fit into a given datacenter.Andrei Frumusanu - Friday, June 18, 2021 - link
There are no ICL-X deployments in the cloud as of yet. I have our own data in the custom chart if that helps.drexnx - Thursday, June 17, 2021 - link
I wonder if part of this uplift is enabled by the constraints of the current IO die on Milan, remove SMT, remove some pressure on IO resources?brucethemoose - Friday, June 18, 2021 - link
Phoronix just did a GCC compiler flag comparison, and found that -0fast is actually slower than -O3 in some tests. But they also experienced a regression with -flto, which doesn't seem quite right.Anyway, AOCC is pretty cool, but I'm not sure how much faster it actually is than the LLVM build its based on. LLVM vs AOCC would be a more apples to apples comparison.
DanNeely - Friday, June 18, 2021 - link
@Andrei Posting here because I don't have a twitter. It's sadly overpriced vs the US listing, but the phone stand you weren't able to find is available on amazon.de (found by searching for "Prosumer's+Choice")https://www.amazon.de/Prosumers-Choice-Universal-S...
eastcoast_pete - Saturday, June 19, 2021 - link
I believe this move by Google also reflects the curious fact that Google, a pioneer in cloud computing and services, has managed to only play third fiddle to AWS and Microsoft's Azure. Google needs to up their game to stay competitive, and this is one of the ways to start doing so.