Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed
by Dr. Ian Cutress & Andrei Frumusanu on August 19, 2021 9:00 AM EST
This week Intel held its annual Architecture Day event for select press and partners. As with previous iterations, the company disclosed details about its next generation architectures set to come to the market over the next twelve months. Intel has promised the release of its next-generation consumer and mobile processor family, Alder Lake, to come by the end of the year and today the company is sharing a good number of details about the holistic design of the chips as well as some good detail about the microarchitectures that form this hybrid design: Golden Cove and Gracemont. Here is our analysis of Intel’s disclosure.
Alder Lake: Intel 12th Gen Core
As mentioned in previous announcements, Intel will launch its Alder Lake family of processors into both desktop and mobile platforms under the name of Intel’s 12th Gen Core Processors with Hybrid Technology later this year. This is Intel’s second generation hybrid architecture built on Intel 7 process node technology. The hybrid design follows Intel Lakefield designs for small notebooks launched last year. The nature of a hybrid design in Intel nomenclature involves having a series of high ‘Performance’ cores paired with a number of high ‘Efficiency’ cores. Intel has simplified this into P-core and E-core terminology.
For Alder Lake, the processor designs feature Performance cores based on a new Golden Cove microarchitecture, and Efficiency cores based on a new Gracemont architecture. We will cover both over the course of this article, however the idea is that the P-core is preferential for single threaded tasks that require low latency, and the E-core is better in power limited or multi-threaded scenarios. Each Alder Lake SoC will physically contain both, however Intel has not yet disclosed the end-user product configurations.

Each of the P-cores has the potential to offer multithreading, whereas the E-cores are one thread per core. This means there will be three physical designs based on Alder Lake:
- 8 P-core + 8 E-core (8C8c/24T) for desktop on a new LGA1700 socket
- 6 P-core + 8 E-core (6C8c/20T) for mobile UP3 designs
- 2 P-core + 8 E-core (2C8c/12T) for mobile UP4 designs
Intel typically highlights UP4 mobile designs for very low power installs, down to 9 W, whereas UP3 can cover anything from 12 W to 35 W (or perhaps higher), but when asked about the power budgets for these processors, Intel stated that more detail will follow when product announcements are made. Intel did confirm that the highest client power, presumably on the desktop processor, will be 125 W.
Highlighted in our discussions is how modular Intel has made Alder Lake. From a range of base component options, the company mixed and matched what it felt were the best combination of parts for each market.
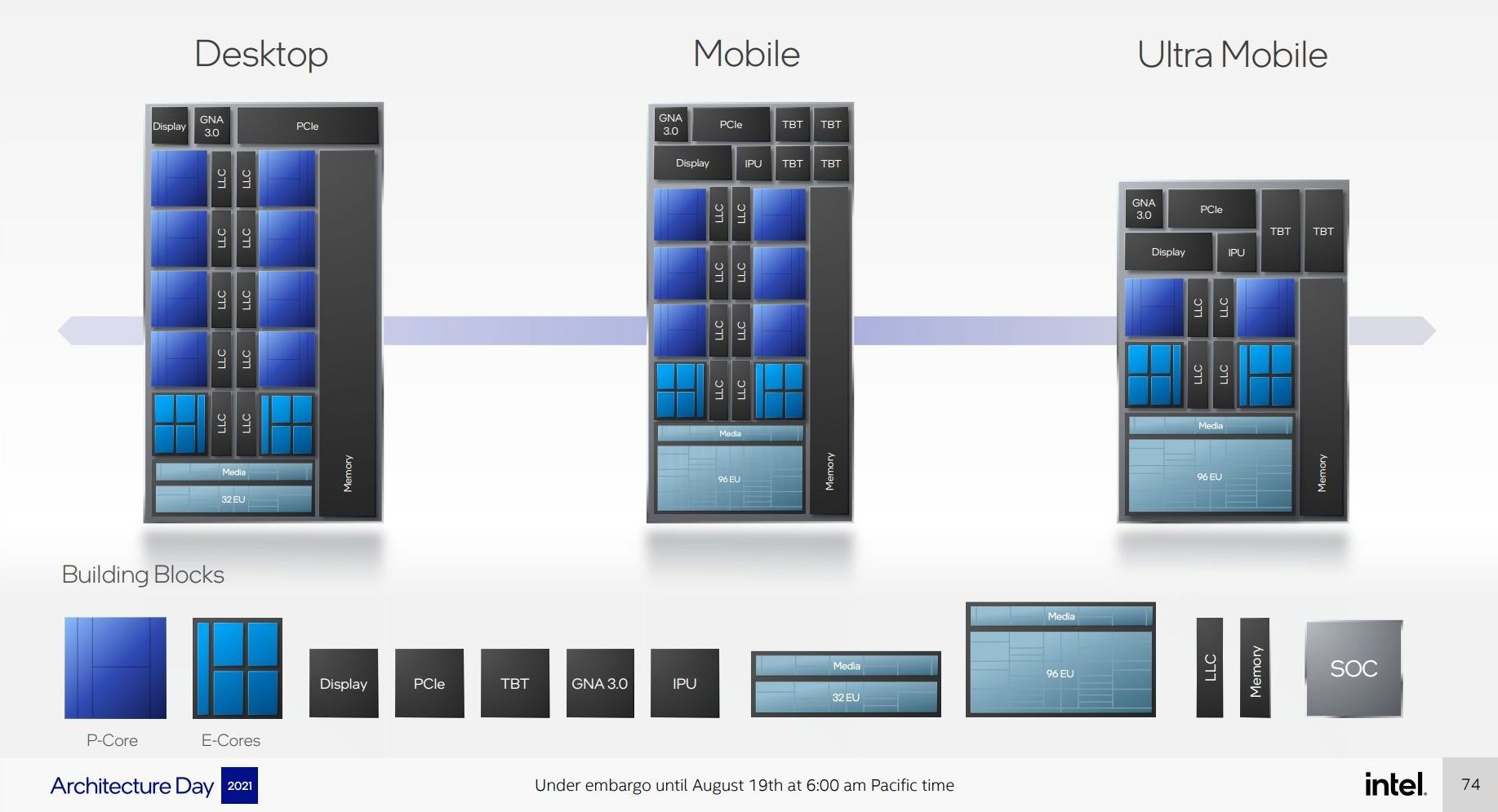
Here it shows that four E-cores takes up the same physical space as one P-core, but also that the desktop hardware will at most have 32 EUs (Execution Units) for Xe-LP graphics (same as the previous generation), while both of the mobile processors will offer 96 physical EUs that may be disabled down based on the specific line item in the product stack.
All three processors will feature Intel’s next generation Gaussian Neural Accelerator (GNA 3.0) for minor low power AI tasks, a display engine, and some level of PCIe, however the desktop processor will have more. Only the mobile processors will get an Image Processing Unit (IPU), and Thunderbolt 4 (TBT), and here the big UP3 mobile processor gets four ports of Thunderbolt whereas the smaller UP4 will only get two. The desktop processor will not have any native Thunderbolt connectivity.
A bit more info on the Desktop Processor IO and Interconnect
We’ll cover a bit more detail about the core designs later in this article, but Intel did showcase some of the information on the desktop processor. It confirmed explicitly that there would be 16 total cores and 24 threads, with up to 30 MB of non-inclusive last level/L3 cache.

In contrast to previous iterations of Intel’s processors, the desktop processor will support all modern standards: DDR5 at 4800 MT/s, DDR4-3200, LPDDR5-5200, and LPDDR4X-4266. Alongside this the processor will enable dynamic voltage-frequency scaling (aka turbo) and offer enhanced overclocking support. What exactly that last element means we’re unclear of at this point.
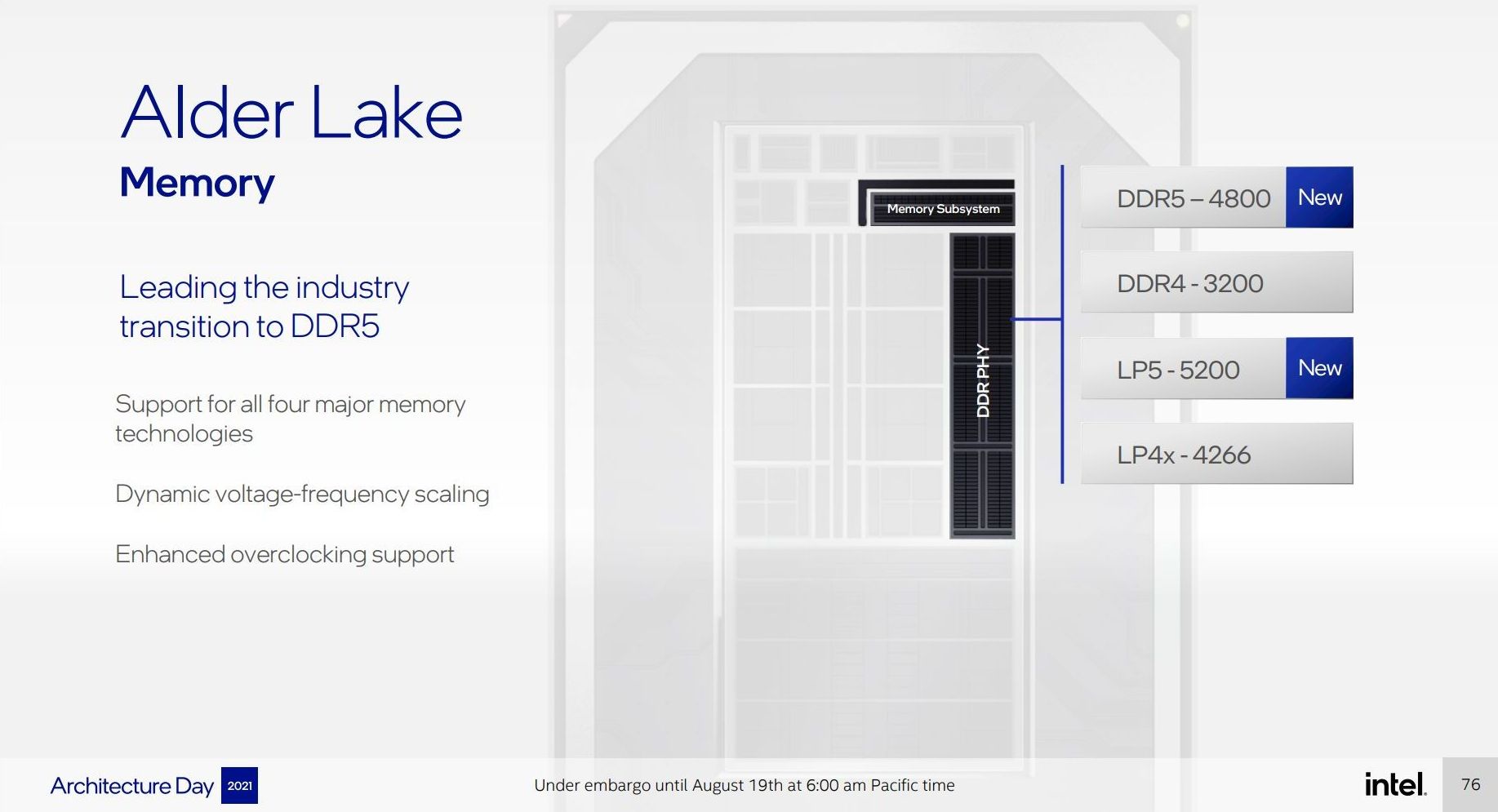
Intel confirmed that there will not be separate core designs with different memory support – all desktop processors will have a memory controller that can do all four standards. What this means is that we may see motherboards with built-in LPDDR5 or LPDDR4X rather than memory slots if a vendor wants to use LP memory, mostly likely in integrated small form factor designs but I wouldn’t put it past someone like ASRock to offer a mini-ITX board with built in LPDDR5. It was not disclosed what memory architectures the mobile processors will support, although we do expect almost identical support.
On the PCIe side of things, Alder Lake’s desktop processor will be supporting 20 lanes of PCIe, and this is split between PCIe 4.0 and PCIe 5.0.
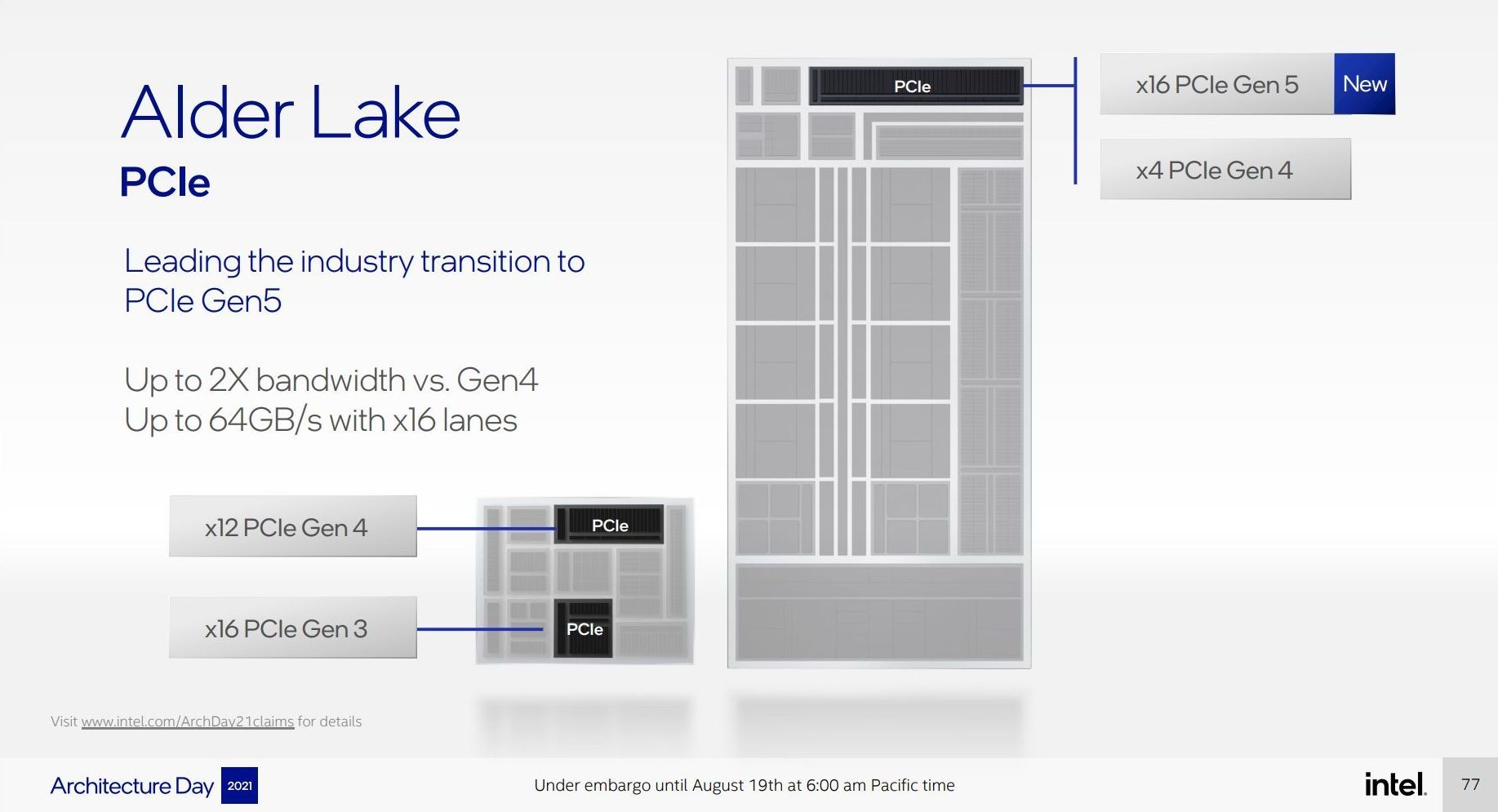
The desktop processor will have sixteen lanes of PCIe 5.0, which we expect to be split as x16 for graphics or as x8 for graphics and x4/x4 for storage. This will enable a full 64 GB/s bandwidth. Above and beyond this are another four PCIe 4.0 lanes for more storage. As PCIe 5.0 NVMe drives come to market, users may have to decide if they want the full PCIe 5.0 to the discrete graphics card or not
Intel also let it be known that the top chipset for Alder Lake on desktop now supports 12 lanes of PCIe 4.0 and 16 lanes of PCIe 3.0. This will allow for additional PCIe 4.0 devices to use the chipset, reducing the number of lanes needed for items like 10 gigabit Ethernet controllers or anything a bit spicier. If you ever thought your RGB controller could use more bandwidth, Intel is only happy to provide.
Intel did not disclose the bandwidth connectivity between the CPU and the chipset, though we believe this to be at least PCIe 4.0 x4 equivalent, if not higher.
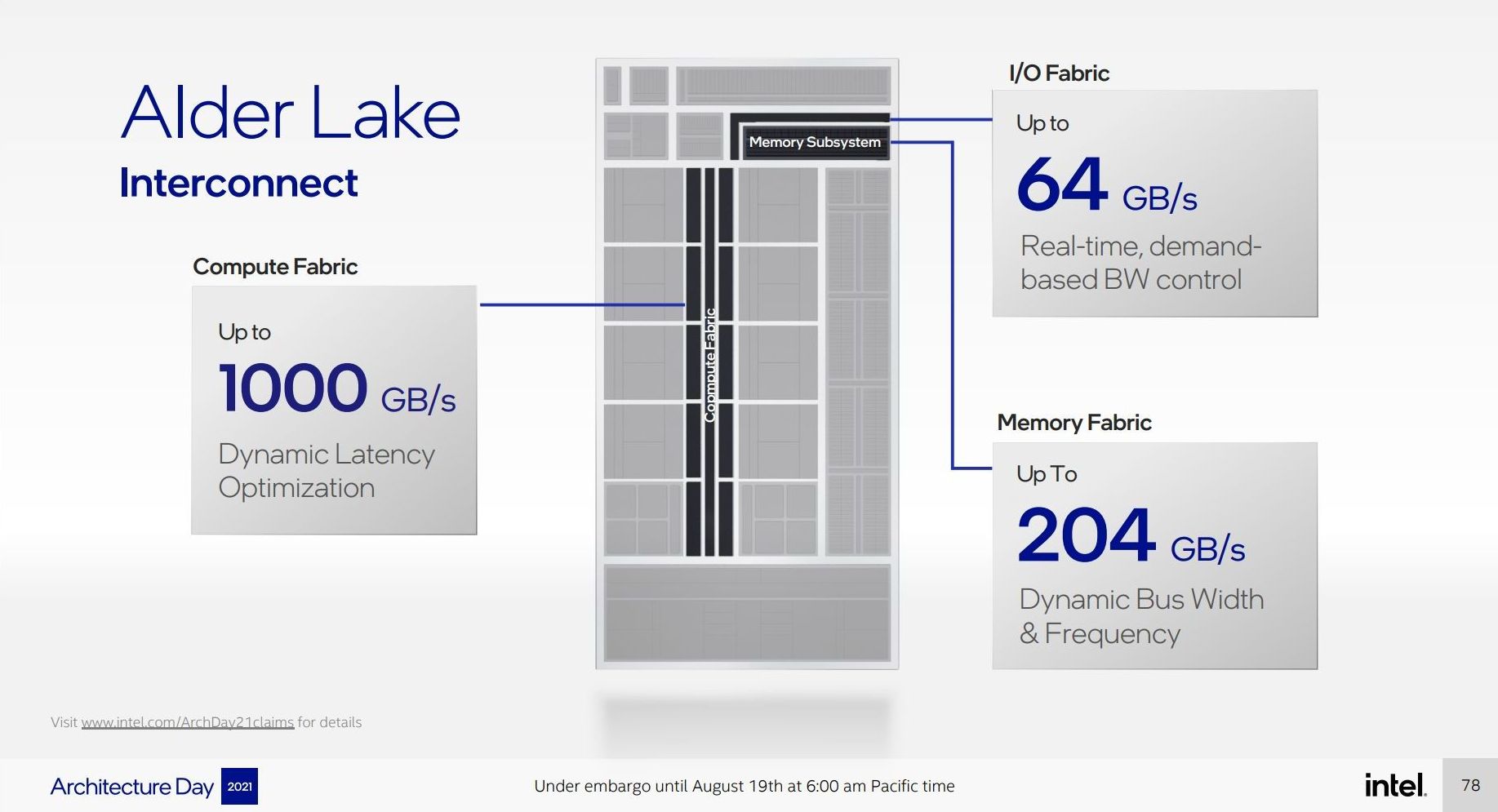
The Alder Lake processor retains the dual-bandwidth ring we saw implemented in Tiger Lake, enabling 1000 GB/s of bandwidth. We learned from asking Intel in our Q&A that this ring is fully enabled regardless of whether the P-cores or E-cores are being used – Intel can disable one of the two rings when less bandwidth is needed, which would save power, however based on previous testing this single ring could end up drawing substantial power compared to the E-cores in low power operation. (This may be true in the mobile processors as well, which would have knock on effects for mobile battery life.)
The 64 GB/s of IO fabric is in line with the PCIe 5.0 x16 numbers we saw above, however the 204 GB/s of memory fabric bandwidth is a confusing number. Alder Lake features a 128-bit memory bus, which allows for 4x 32-bit DDR5 channels (DDR5 has two 32-bit channels per module, so 2 modules still), however in order to reach 204 GB/s in that configuration requires DDR5-12750; Intel has rated the processor only at DDR5-4800, less than half that, so it is unclear where this 204 GB/s number comes from. For perspective, Intel’s Ice Lake does 204.8 GB/s, and that’s a high-power server platform with 8 channels of DDR4-3200.

This final slide mentions TB4 and Wi-Fi 6E, however as with previous desktop processors, these are derived from controllers attached to the chipset, and not in the silicon itself. The mobile processors will have TBT integrated, but the desktop processor does not.
This slide also mentions Intel Thread Director, which we want to address on the next page before we get to the microarchitecture analysis.








223 Comments
View All Comments
mode_13h - Friday, August 20, 2021 - link
> - treat all-zero lines as special cases that are tagged in L2/SLC but don't require> transferring data on the NoC. Intel had something like this in IceLake that, after
> some time, they switched off with microcode update.
I heard about that. Sad to see it go, but certainly one of those micro-optimizations that's barely measurable.
name99 - Thursday, August 19, 2021 - link
" This is over double that of AMD’s Zen3 µarch, and really only second to Apple’s core microarchitecture which we’ve measured in at around 630 instructions. "Apple's ROB is in fact around 2300 entries in size. But because it is put together differently than the traditional ROB, you will get very different numbers depending on exactly what you test.
The essential points are
(a)
- the ROB proper consists of about 330 "rows" where each row holds 7 instructions.
- one of these instructions can be a "failable", ie something that can force a flush. In other words branches or load/stores
- so if you simply count NOPs, you'll get a count of ~2300 entries. Anything else will hit earlier limits.
(b) The most important of these limits, for most purposes, is the History File which tracks changes in the logical to physical register mapping. THIS entity has ~630 entries and is what you will bump into first if you test somewhat varied code.
Earlier limits are ~380 int physical registers, ~420 or so FP registers, ~128 flag registers. But if you balance code across fp and int you will hit the 630 History File limit first.
(c) If you carefully balance that against code that does not touch the History File (mainly stores and branches) than you can get to almost but not quite 1000 ROB entries.
The primary reason Apple looks so different from x86 is that (this is a common pattern throughout Apple's design)
- what has traditionally been one object (eg a ROB that tracks instruction retirement AND tracks register mappings) is split into two objects each handling a single task.
The ROB handles in-order retiring, including flush. The History File handles register mapping (in case of flush and revert to an earlier state) and marking registers as free after retire.
This design style is everywhere. Another, very different, example, is the traditional Load part of the Load/Store queue is split into two parts, one tracking overlap with pending/unresolved stores, the second part tracking whether Replay might be required (eg because of missing in TLB or in the L1).
- even a single object is split into multiple what Apple calls "slices", but essentially a way to share rare cases with common cases, so the ROB needs to track some extra state for "failable" instructions that may cause a flush, but not every instruction needs that state. So you get this structure where you have up to six "lightweight" instructions with small ROB slots, and a "heavyweight" instruction with a larger ROB slot. Again with see this sort of thing everywhere, eg in the structures that hold branches waiting to retire which are carefully laid out to cover lots of branches, but with less storage for various special cases (taken branches need to preserve the history/path vectors, none-taken branches don't; indirect branches need to store a target, etc etc)
GeoffreyA - Friday, August 20, 2021 - link
Thanks for all the brilliant comments on CPU design!mode_13h - Friday, August 20, 2021 - link
Go go go!GeoffreyA - Thursday, August 19, 2021 - link
I think Intel did a great job at last. Golden Cove, impressive. But the real star's going to be Gracemont. Atom's come of age at last. Better than Skylake, while using less power, means it's somewhere in the region of Zen 2. Got a feeling it'll become Intel's chief design in the future, the competitor to Zen.As for Intel Thread Director, interesting and impressive; but the closer tying of hardware and scheduler, not too sure about that. Name reminded me of the G-Man, strangely enough. AVX512, good riddance. And Intel Marketing, good job on the slides. They look quite nice. All in all, glad to see Intel's on the right track. Keep it up. And thanks for the coverage, Ian and Andrei.
Silver5urfer - Friday, August 20, 2021 - link
Lol. That is no star. The small puny SKL cores are not going to render your high FPS nor the Zip compression. They are admitting themselves these are efficiency. Why ? Because 10SF is busted in power consumption and Intel cannot really make any more big cores on their Desktop platform without getting power throttled. On top their Ring bus cannot scale like SKL anymore.GeoffreyA - Friday, August 20, 2021 - link
Not as it stands, but mark my words, the Atom design is going to end up the main branch, on the heels of Zen in p/w. Interesting ideas are getting poured into this thing, whereas the bigger cores, they're just making it wider for the most part.ifThenError - Friday, August 20, 2021 - link
Totally understand your point and I'd personally welcome such a development!Anyway, the past years have shown a rather opposite way. Just take ARM as an example. There once was an efficiency line of cores that got the last update years ago with the A35. Now it's labelled as "super efficient" and hardly has any implementations aside from devices sitting idle most of the time. You can practically consider it abandoned.
The former mid tier with the A55 is now marketed as efficient cores, while the former top tier A7x more and more turns into the new midrange. Meanwhile people go all crazy about the new X1 top tier processors even though the growth of power consumption and heat is disproportionate to the performance. Does this sound reasonable in a power and heat constraint environment? Yeah, I don't think so either! ;-)
For that reason I perfectly understand Ian's demand for a 64 core Gracemont CPU. Heck, even a 16 core would still be #1 on my wishlist.
GeoffreyA - Saturday, August 21, 2021 - link
Yes, performance/watt is the way to go, and I reckon a couple more rounds of iteration will get Atom running at the competition's level. The designs are similar enough. It's ironic, because Atom had a reputation for being so slow.mode_13h - Saturday, August 21, 2021 - link
> Atom had a reputation for being so slow.With Tremont, Intel really upped their Atom game. It added a lot of complexity and grew significantly wider.
However, it's not until Gracemont's addition of AVX/AVX2 that Intel is clearly indicating it wants these cores to be taken seriously.
I wonder if Intel will promote their Atom line of SoCs as the new replacement for Xeon D. Currently, I think they're just being marketed for embedded servers and 5G Basestations, but they seem to have the nous to taken the markets Xeon D was targeting.