The Apple A15 SoC Performance Review: Faster & More Efficient
by Andrei Frumusanu on October 4, 2021 9:30 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- Apple A15

A few weeks ago, we’ve seen Apple announce their newest iPhone 13 series devices, a set of phones being powered by the newest Apple A15 SoC. Today, in advance of the full device review which we’ll cover in the near future, we’re taking a closer look at the new generation chipset, looking at what exactly Apple has changed in the new silicon, and whether it lives up to the hype.
This year’s announcement of the A15 was a bit odder on Apple’s PR side of things, notably because the company generally avoided making any generational comparisons between the new design to Apple’s own A14. Particularly notable was the fact that Apple preferred to describe the SoC in context of the competition; while that’s not unusual on the Mac side of things, it was something that this year stood out more than usual for the iPhone announcement.

The few concrete factoids about the A15 were that Apple is using new designs for their CPUs, a faster Neural engine, a new 4- or 5-core GPU depending on the iPhone variant, and a whole new display pipeline and media hardware block for video encoding and decoding, alongside new ISP improvements for camera quality advancements.
On the CPU side of things, improvements were very vague in that Apple quoted to be 50% faster than the competition, and the GPU performance metrics were also made in such a manner, describing the 4-core GPU A15 being +30% faster than the competition, and the 5-core variant being +50% faster. We’ve put the SoC through its initial paces, and in today’s article we’ll be focusing on the exact performance and efficiency metrics of the new chip.
Frequency Boosts; 3.24GHz Performance & 2.0GHz Efficiency Cores
Starting off with the CPU side of things, the new A15 is said to feature two new CPU microarchitectures, both for the performance cores as well as the efficiency cores. The first few reports about the performance of the new cores were focused around the frequencies, which we can now confirm in our measurements:
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A15 | 1 | 2 | 3 | 4 | ||
| Performance 1 | 3240 | 3180 | ||||
| Performance 2 | 3180 | |||||
| Efficiency 1 | 2016 | 2016 | 2016 | 2016 | ||
| Efficiency 2 | 2016 | 2016 | 2016 | |||
| Efficiency 3 | 2016 | 2016 | ||||
| Efficiency 4 | 2016 | |||||
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A14 | 1 | 2 | 3 | 4 | ||
| Performance 1 | 2998 | 2890 | ||||
| Performance 2 | 2890 | |||||
| Efficiency 1 | 1823 | 1823 | 1823 | 1823 | ||
| Efficiency 2 | 1823 | 1823 | 1823 | |||
| Efficiency 3 | 1823 | 1823 | ||||
| Efficiency 4 | 1823 | |||||
Compared to the A14, the new A15 increases the peak single-core frequency of the two-performance core cluster by 8%, now reaching up to 3240MHz compared to the 2998MHz of the previous generation. When both performance cores are active, their operating frequency actually goes up by 10%, both now running at an aggressive 3180MHz compared to the previous generation’s 2890MHz.
In general, Apple’s frequency increases here are quite aggressive given the fact that it’s quite hard to push this performance aspect of a design, especially when we’re not expecting major performance gains on the part of the new process node. The A15 should be made on an N5P node variant from TSMC, although neither company really discloses the exact details of the design. TSMC claims a +5% frequency increase over N5, so for Apple to have gone further beyond this would have indicated an increase in power consumption, something to keep in mind of when we dive deeper into the power characteristics of the CPUs.
The E-cores of the A15 are now able to clock up to 2016MHz, a 10.5% increase over the A14’s cores. The frequency here is independent of the performance cores, as in the number of threads in the cluster doesn’t affect the other cluster, or vice-versa. Apple has done some more interesting changes to the little cores this generation, which we’ll come to in a bit.
Giant Caches: Performance CPU L2 to 12MB, SLC to Massive 32MB
One more straightforward technical detail Apple revealed during its launch was that the A15 now features double the system cache compared to the A14. Two years ago we had detailed the A13’s new SLC which had grown from 8MB in the A12 to 16MB, a size that was also kept constant in the A14 generation. Apple claiming they’ve doubled this would consequently mean it’s 32MB now in the A15.
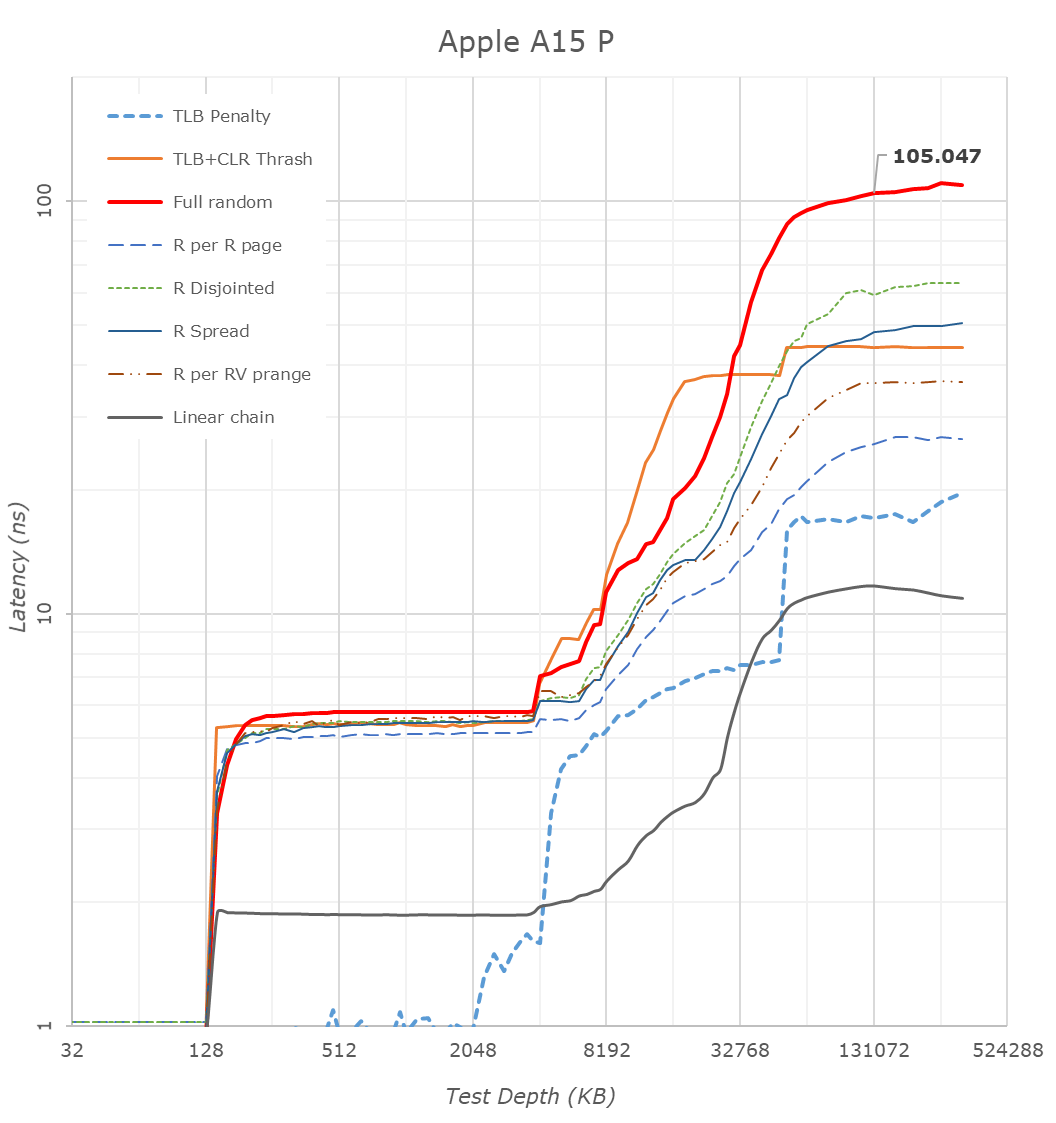
Looking at our latency tests on the new A15, we can indeed now confirm that the SLC has now doubled up to 32MB, further pushing the memory depth to reach DRAM. Apple’s SLC is likely to be a key factor in the power efficiency of the chip, being able to keep memory accesses on the same silicon rather than going out to slower, and more power inefficient DRAM. We’ve seen these types of last-level caches being employed by more SoC vendors, but at 32MB, the new A15 dwarfs the competition’s implementations, such as the 3MB SLC on the Snapdragon 888 or the estimated 6-8MB SLC on the Exynos 2100.
What Apple didn’t divulge, is also changes to the L2 cache of the performance cores, which has now grown by 50% from 8MB to 12MB. This was actually the same L2 size as on the Apple M1, only this time around it’s serving only two performance cores rather than four. The access latency appears to have risen from 16 cycles on the A14 to 18 cycles on the A15.
A 12MB L2 is again humongous, over double compared to the combined L3+L2 (4+1+3x0.5 = 6.5MB) of other designs such as the Snapdragon 888. It very much appears Apple has invested a lot of SRAM into this year’s SoC generation.
The efficiency cores this year don’t seem to have changed their cache sizes, remaining at 64KB L1D’s and 4MB shared L2’s, however we see Apple has increased the L2 TLB to 2048 entries, now covering up to 32MB, likely to facilitate better SLC access latencies. Interestingly, Apple this year now allows the efficiency cores to have faster DRAM access, with latencies now at around 130ns versus the +215ns on the A14, again something to keep in mind of in the next performance section of the article.
CPU Microarchitecture Changes: A Slow(er) Year?
This year’s CPU microarchitectures were a bit of a wildcard. Earlier this year, Arm had announced the new Armv9 ISA, predominantly defined by the new SVE2 SIMD instruction set, as well as the company’s new Cortex series CPU IP which employs the new architecture. Back in 2013, Apple was notorious for being the first on the market with an Armv8 CPU, the first 64-bit capable mobile design. Given that context, I had generally expected this year’s generation to introduce v9 as well, but however that doesn’t seem to be the case for the A15.
Microarchitecturally, the new performance cores on the A15 doesn’t seem to differ much from last year’s designs. I haven’t invested the time yet to look at every nook and cranny of the design, but at least the back-end of the processor is identical in throughput and latencies compared to the A14 performance cores.
The efficiency cores have had more changes, alongside some of the memory subsystem TLB changes, the new E-core now gains an extra integer ALU, bringing the total up to 4, up from the previous 3. The core for some time no longer could be called “little” by any means, and it seems to have grown even more this year, again, something we’ll showcase in the performance section.
The possible reason for Apple’s more moderate micro-architectural changes this year might be a storm of a few factors – Apple had notably lost their lead architect on the big performance cores, as well as parts of the design teams, to Nuvia back in 2019 (later acquired by Qualcomm earlier this year). The shift towards Armv9 might also imply some more work done on the design, and the pandemic situation might also have contributed to some non-ideal execution. We’ll have to examine next year’s A16 to really determine if Apple’s design cadence has slowed down, or whether this was merely just a slippage, or simply a lull before a much larger change in the next microarchitecture.
Of course, the tone here paints rather conservative improvement of the A15’s CPUs, which when looking at performance and efficiency, are anything but that.








204 Comments
View All Comments
unclevagz - Monday, October 4, 2021 - link
Thanks, since Anandtech does have data on Spec 2017 subtests with various x86 processors it may also be helpful to show these results for selected x86 CPUs in the displayed graphs for ease of comparisions.Andrei Frumusanu - Monday, October 4, 2021 - link
I thought about it but didn't want to complicate it too much given the power disparity.Andrei Frumusanu - Monday, October 4, 2021 - link
I added in performance marks for the x86 folks. Obviously no power data.Kangal - Tuesday, October 5, 2021 - link
Hey Andrei,The graphs for Spec-2017 Efficiency looks quiet off. It's showing the Cortex-A55 cores consuming considerable more energy than Apple's E-cores, and sometimes even more than the Cortex-A78 cores too. Whilst performance seems as expected.
The worst offender seems to be the 544.nab_r, with the a discrepancy of 0.60 perf / 682 J = ~0.001 p/J compared to the 2.70 perf / 280 J = ~0.01 p/J. So that's an efficiency difference of ~x10 which is massive. And the best case for the A55 seems to be in the 541.leela_r test. Here we have 1.00 perf / 295 J = ~0.003 p/J compared to the 2.49 perf / 264 J = ~0.009 p/J. So in this best-case scenario the efficiency difference is ~x3 which is still huge.
I mean, I remember when Apple's E-cores were running slightly slower than the Cortex-A73 whilst using slightly more power than the Cortex-A53. But what we have here is just ridiculous. We have even less power draw than the Cortex-A55 or even the Cortex-A53, but performance is somewhere above the legendary Cortex-A76.
I can't wrap my head around it. It feels like an impossibility. Is my maths checking out? Or does there seem to be an issue someplace in the data?
Andrei Frumusanu - Tuesday, October 5, 2021 - link
Perf per joule is a bit of a weird metric that is superfluous, you want either perf/W or simply just Joules consumed for energy efficiency, so either 0.60 / 0.24W = 2.5ppW & 2.7 / 0.45W = 6ppW. You can argue about power curves and ISO-perf or ISO-power.In any case, the other thing to consider is that we're not just measuring the core, we're measuring the efficiency of the whole SoC, power delivery, DRAM as well. Some vendors aren't running things as efficiently as they should be, that's how you end up with those Exynos A55 results, contrasted for example to the MediaTek A55 results.
Kangal - Wednesday, October 6, 2021 - link
I didn't know that, I thought we had the software just churn out how much power the module was using on its own. With that said, I don't think it would be a factor. Apple doesn't have anything special in the makeup of their silicon to make it more efficient than competitors. And even if they did have a notable advantage in the make-up of their silicon, this would be against something like a RockChip SoC, and not against a flagship Qualcomm SoC. The more feasible explanation would be that the QSD chip might be activating other co-processors like it's NPU, and the task isn't actually being hardware-accelerated by it, but "software-encoded" by its targeted CPU (eg A55). Thus its still running slow, but now its wasting power by having other co-processors become active and not actually compute anything......Would something like this be a cause for concern, for future testing?
Secondly, I used the Joules as that's what the graph was visually showing. I basically used it to find the best-case and worst-case scenario. I didn't really think hard about it. Since you've graphed it, and since you've recorded it, I figured you knew something that I didn't and prioritised Joules over Watts.
Converting them to Watts, we instead get:
(nab_r) 2.70/0.45 = 6.00 vs 2.50 = 0.6/0.24 ---> a difference of x2.4
(leela_r) 2.49/0.40 = 6.23 vs 5.56 = 1.00/0.18 ----> a difference of x1.1
But now, the graphs themselves need to be switched. For instance, the New Worst-case scenario is now: 520.omnetpp_r (~x3.4) from what I can see. Maybe I'll go through these benchmark figures properly on a weekend or something, unless you guys plan on doing something of the sort.
So yes, these ranges do seem more reasonable. For starters, here we see the "IceStorm v2" cores are actually using about double the power of the "Cortex-A55" on half of the tests. This shatters my previous impression, that Apple's small cores were faster-than Cortex-A73 and used less-power than Cortex-A53. And that fits much neater into our general understanding about them, comparing small in-order cores, versus medium out-of-order cores.
Can we change how the graphs are displayed from now on? Plot the Watts on the Right/Second x-axis instead of Joules. Or better yet, let's just strip out Joules entirely. I mean the third graph, the Energy-Axis should probably be deleted, and just keep the Power-Axis there instead? No?
Ppietra - Wednesday, October 6, 2021 - link
Kangal,Joules will always be the most correct parameter to assess efficiency, since it is the actual energy expended to do all the work.
Power, on the other hand, can fluctuate through time while doing the work, so the Power value can be very deceiving, firstly because it might not be the actual average power usage, secondly because you need to do another calculation to actually measure efficiency.
Kangal - Wednesday, October 6, 2021 - link
Do you know how they calculated the Watts? And how they calculated the Joules?To me, Watts makes much more sense in this context/comparison. Joules is more "universal" measurement, and it might be useful in a niche, but I feel like it could me mis-used/abused easily when put out of context.
How do we explain the HUGE discrepancy in the measurements between Watts and Joules? There is something else here I am not understanding.
Ppietra - Wednesday, October 6, 2021 - link
For that you need to understand what is Power and what is Energy.If there is one parameter that can be misused to assess efficiency while doing a task it’s Power not Energy. What you don’t seem to account for it’s the Time variable that affects how you can interpret Power.
michael2k - Wednesday, October 6, 2021 - link
I wanted to specifically bring something up:Apple doesn't have anything special in the makeup of their silicon to make it more efficient than competitors.
A14: TSMC 5nm (N5)
A15: TSMC 5nm (N5P)
D1200: TSMC 6nm (N6)
SD888: TSMC 5nm (N5)
Technically Apple is one year ahead of Qualcomm and two or so ahead of MediaTek in terms of process.
Looking at the SPECin2017 Power Axis graph we see on average that the A15 IceStorm v2 consumes 0.44W/2349J to achieve a 2.42 score, which puts them on par with the D1200 A78 with it's 2.57 score, but at far higher power cost of 1.13W/6048J
In other words the A78 and A15 have very similar performance, which makes sense since there are many similarities in terms of number of execution units, width, etc. If you look at the older style charts you can see that the efficiency cores were far closer in performance to the A76 'performance' cores on the Kirin 990:
https://www.anandtech.com/show/14892/the-apple-iph...
https://www.anandtech.com/show/14892/the-apple-iph...
Long story short, there doesn't seem to be any surprises. Apple has a process advantage, uses cores similar to ARM's performance cores for efficiency purposes, and does so by clocking them at 3/4 the speed to dramatically reduce the power draw. The A15e only hits 2.016GHz and the A14e maxed at 1.823GHz, and the A13e at 1.728GHz