AMD Zen 4 Ryzen 9 7950X and Ryzen 5 7600X Review: Retaking The High-End
by Ryan Smith & Gavin Bonshor on September 26, 2022 9:00 AM ESTZen 4 Architecture: Power Efficiency, Performance, & New Instructions
Now that we’ve had a chance to take a look at the AM5 platform surrounding the new Ryzen 7000 chips, as well as the new IOD that completes the high-end Ryzen chips, let’s dive into the heart of matters: the Zen 4 CPU cores.
As laid out in previous pages, a big element in AMD’s design goals for the Ryzen 7000 platform was to modernize it, adding support for things like PCIe 5.0 and DDR5, as well as integrating more fine-grained power controls. And while this attention meant that AMD’s collective attention was split between the CPU cores and the rest of the platform, AMD’s CPU cores are far from being ignored here. Still, it’s fair to say that AMD’s goal for the Zen 4 architecture has not been a radical overhaul of their core CPU architecture. For that, you’ll want to wait for Zen 5 in 2024.
Instead, Zen 4 is a further refinement of AMD’s Zen 3 architecture, with AMD taking advantage of things like the new AM5 platform and TSMC’s 5nm process to further boost performance. There are some important changes here that are allowing AMD to deliver an average IPC increase of 13%, and combined with improvements to enable higher clockspeeds and greater power efficiency for both single-threaded and multi-threaded workloads, no part of AMD’s CPU performance has gone untouched.

Zen 4 Power: More Efficient, More Power-Hungry
We’ll start with a look at power efficiency, since power consumption plays a huge part in the Zen 4 story at both ends of the curve.
By tapping TSMC’s current-generation 5nm, process, AMD is enjoying the advantage of a full node shrink for their CPU cores. Thus far TSMC 5nm (and its 4nm derivative) is proving to be the powerhouse process of its generation, as TSMC’s clients have seen some solid gains in power efficiency and transistor density moving from 7nm to 5nm. Meanwhile TSMC’s competitors are either struggling by delivering less efficient 4nm-class nodes (Samsung), or they’ve yet to deliver a 4nm-class node at all (Intel). In other words, for the moment TSMC’s 5nm-class nodes are as good as it gets, putting AMD in a great position to take advantage of the benefits.
Coupled with this are all of the various platform power improvements that come with AM5 and the new 6nm IOD. These include the 3 variable power rails, SVI3 VRM monitoring, and AMD’s lower-power Infinity Fabric Links. As a result, the Ryzen 7000 chips enjoy a significant power efficiency advantage versus the Ryzen 5000 chips.
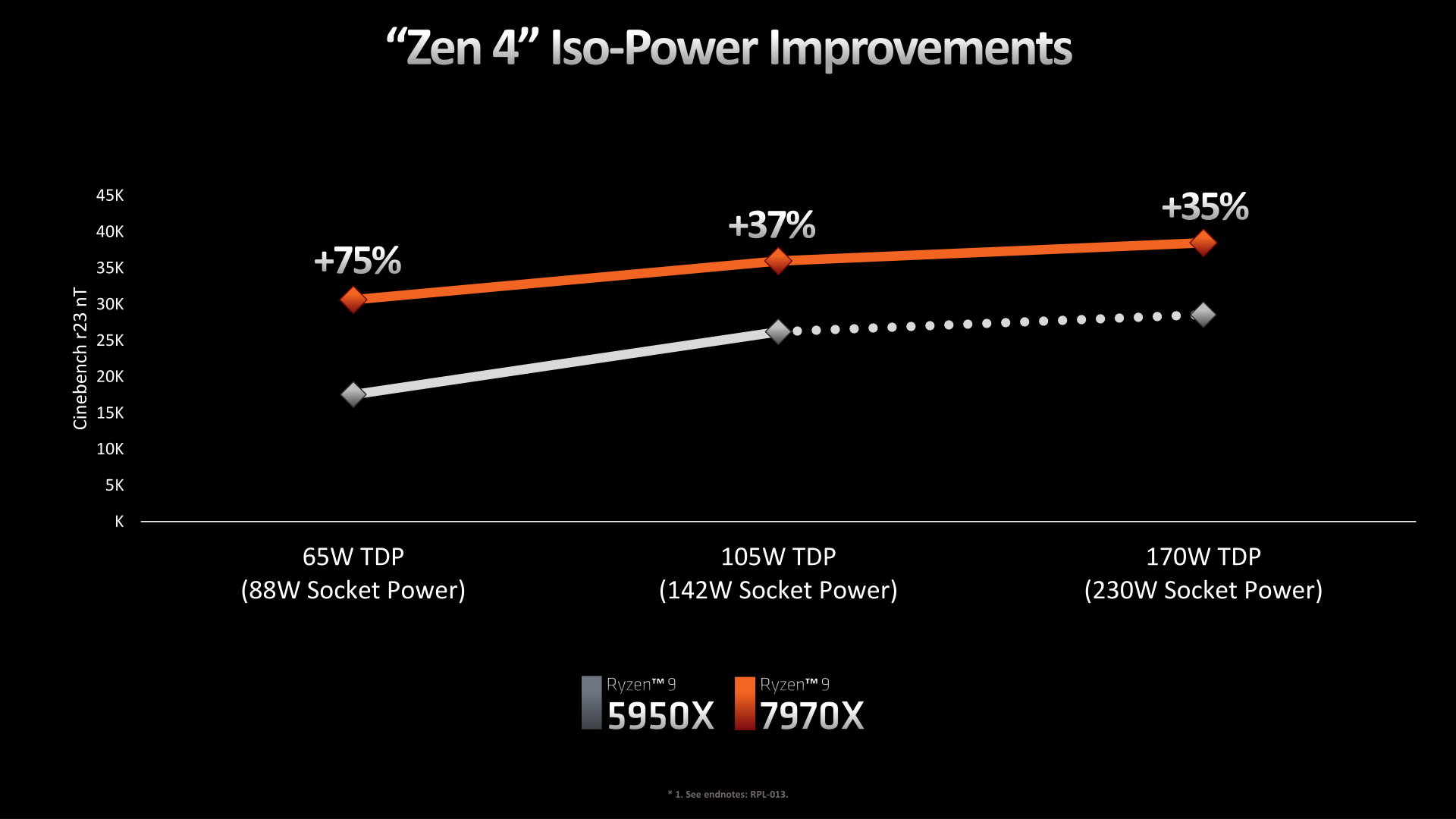
How much of an improvement, in turn, depends on where on the voltage/frequency curve you end up. As we alluded to earlier when talking about AM5, one of AMD’s design goals was to provide more power to Ryzen 7000 chips so that they could go farther into the vf curve and keep their cores running at a higher frequency in MT-heavy workloads.
The net result is that, according to AMD’s data, the company is seeing extensive power efficiency gains at lower TDPs. In this case, pitting a 5950X against a 7950X with a maximum socket power of 88 Watts, AMD is seeing a 75% increase in performance on Cinebench R23 nT. This is something of a worst-case scenario for the older Ryzen chip, as it tended to be TDP limited even at is native TDP, and the relatively high idle power draw of the IOD and the rest of the platform further ate into that. As a result, the 5950X needs to pull back on clockspeeds significantly at lower TDPs. For Ryzen 7000/Zen 4 on the other hand, AMD’s newer architecture fairs much better; it still takes a hit from the TDP drop, but not by nearly as much.
Meanwhile, increasing the socket power to 142 (5950X’s stock power) and then to 230W (7950X’s stock power) still produces a significant speed up in performance, but we’re certainly into the area of diminishing returns. In this case the 7950X has a 37% lead and 35% lead at 142W and 230W respectively.
We’ll take a look at more power data for the new Ryzen 7000 chips a bit later in our review, but the basic pattern is clear: Zen 4 can be a very power efficient architecture. But AMD is also discarding some of that efficiency advantage in the name of improving raw performance. Especially in multi-threaded workloads, for high-end chips like the 7950X the performance gains we’re seeing are as much from higher TDPs as they are higher IPCs and improved power efficiency.
This will make AMD’s eventual Zen 4 mobile products (Phoenix Point) an especially interesting product to keep an eye on. The greater focus on power efficiency (and harder cap on top TDPs) means that we may not yet have seen Zen 4 put its best foot forward when it comes to power efficiency.
Clockspeeds: Going Faster Means Being Faster
One way that’s always a good method to improve your CPU performance is just to flat-out increase clockspeeds. Tried and true, this drove the x86 CPU industry for most of its first 30 years before the laws of physics (and specifically, the death of Dennard Scaling) put the brakes on massive generation-on-generation clockspeed gains. Still, AMD and Intel like to squeeze out higher frequencies when they can, and in the case of AMD’s CPU architecture, TSMC’s 5nm process has provided for some nice gains here, finally pushing AMD well over the (stubborn) 5GHz mark.

For AMD’s high-end Ryzen 7000 desktop processors, the top turbo frequencies are now as high as 5.7GHz for the Ryzen 9 7950X, and even the slowest Ryzen 5 7600X is rated to hit 5.3GHz. And in both cases, there is still a bit more headroom still when using Precision Boost Optimization 2 (PBO2), allowing chips to potentially eek out another 100MHz or so. For AMD’s top-end part then, we’re looking at a 16% increase in turbo clockspeeds, while the 7600X is clocked some 15% faster than its predecessor.
According to AMD’s engineers, there is no singular magic trick here that has allowed them to boost clockspeeds to the high 5GHz range on Zen 4, nor has the company sacrificed any IPC to allow for higher clockspeeds (e.g. lengthening pipelines). TSMC’s 5nm process sure helped a lot in this regard, but AMD’s technical relationship with TSMC also improved as the company’s CPU engineers became familiar with designing and optimizing CPUs for TSMC’s 7nm and 6nm process nodes. As a result, the two companies were able to better work together to reliably get higher frequencies out of AMD’s CPU cores, with AMD going as far as to integrating some TSMC IP instead of relying on more traditional design partners.
Even with that, Zen 4 actually came in a bit below AMD’s expectations, if you can believe that. According to the company’s engineers, they were hoping to hit 6GHz on this part, something that didn’t quite come to fruition. So AMD’s users will have to settle for just 5.7GHz, instead.
Zen 4 IPC: Getting 13% More
On the other side of the performance equation we have IPC improvements. AMD’s broader focus on platform design for the Ryzen 7000 generation means that the IPC gains aren’t quite as great as what we saw on Zen 3 or Zen 2, but they’re not to be ignored, either. Even without a massive overhaul of AMD’s execution back-end – and with only a moderate update to the front-end – AMD was still able to squeeze out an average IPC gain of 13% across a couple of dozen benchmarks, only 2 percentage points lower than the 15% gains AMD delivered with the Zen 2 architecture in 2019.
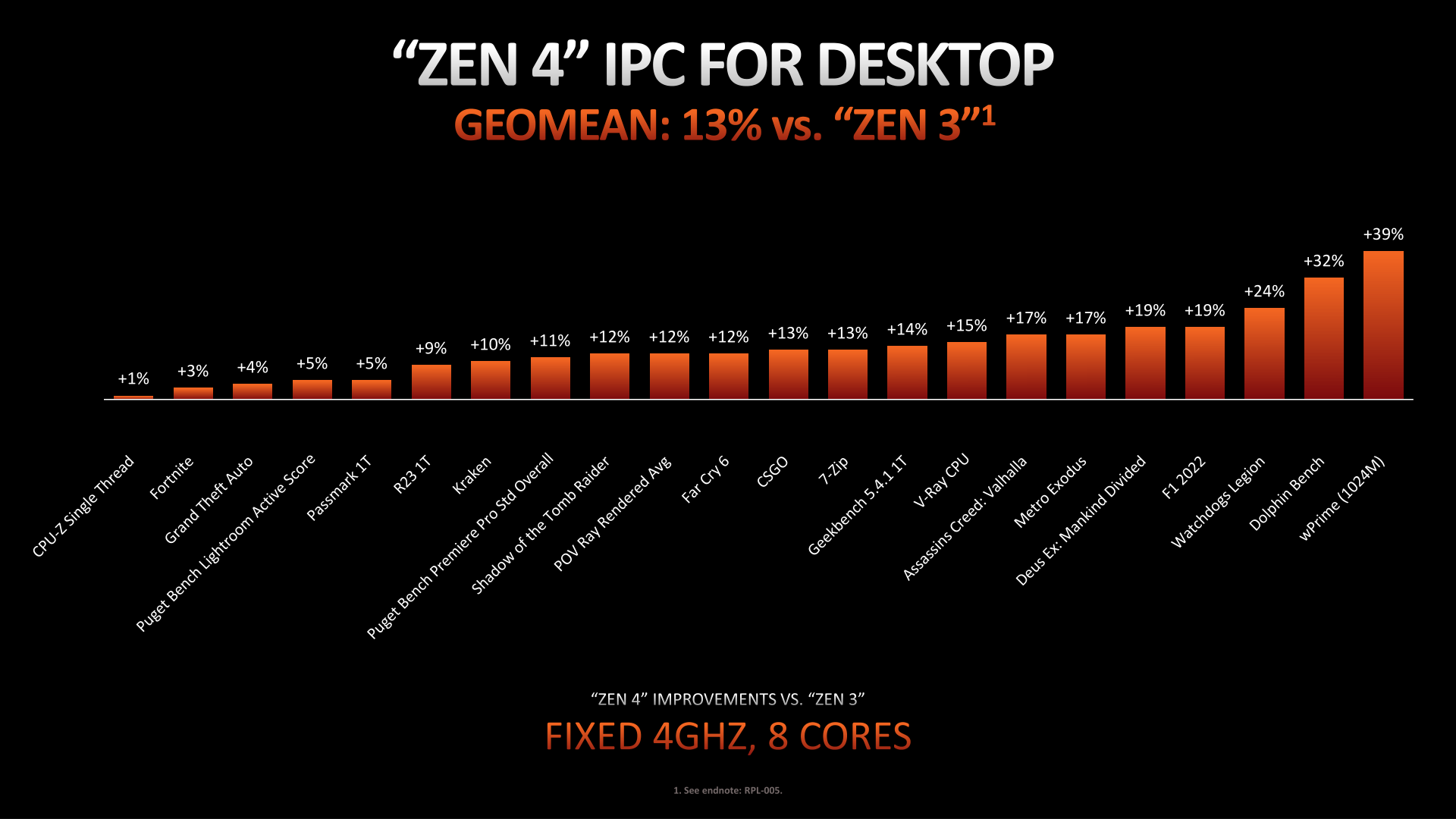
We won’t fixate on any one workload here, but it does run the gamut. At an iso-frequency of 4GHz, Zen 4 delivers anything from a tiny increase to 39% at the top end. In traditional PC performance fashion, the gains from one generation to the next are workload-dependent. So a 13% average does leave plenty of wiggle-room for either greater or lesser gains, as we’ll see in our full benchmark results.
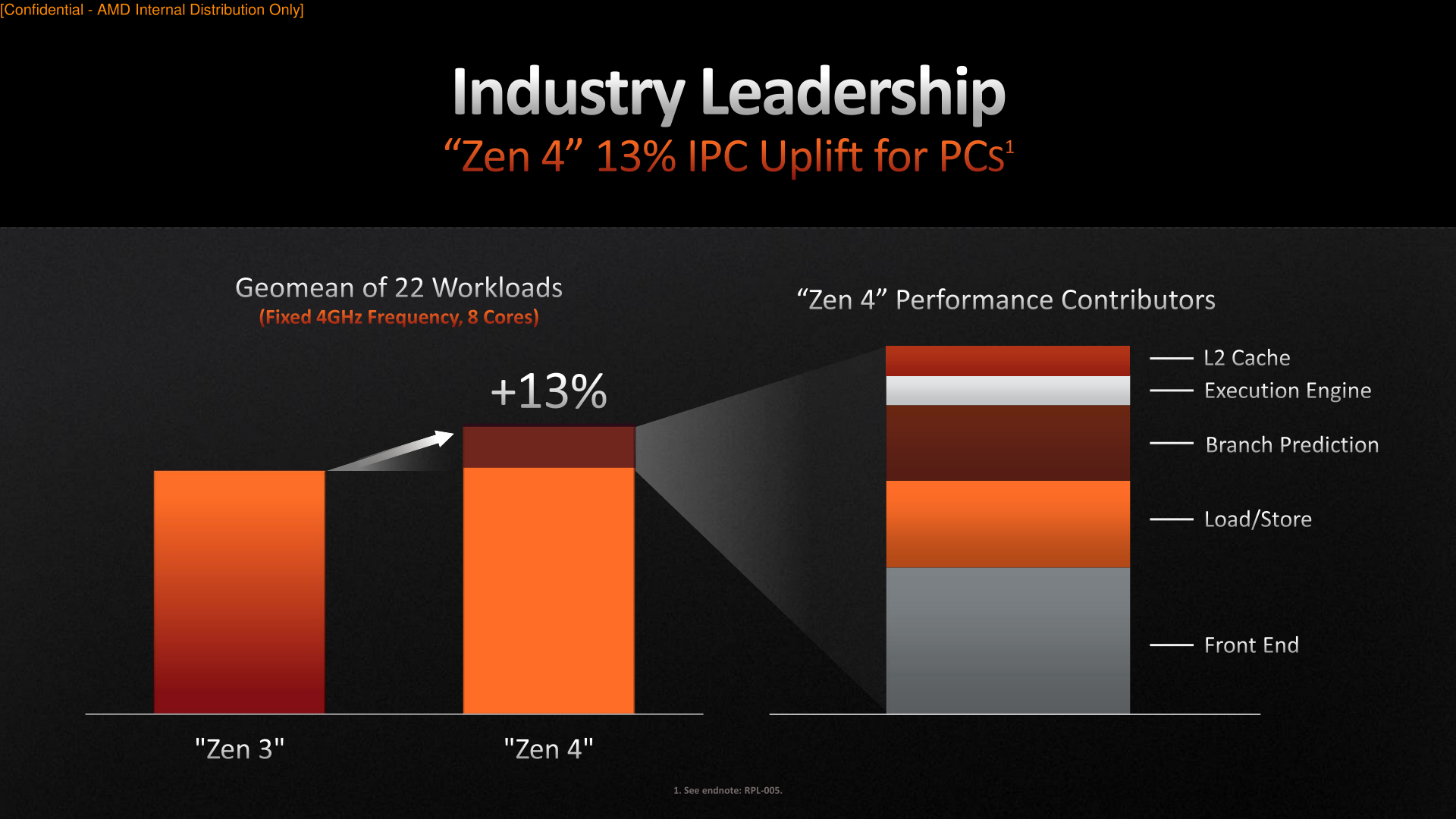
AMD has also provided a handy IPC contributor breakdown, showing where those 13% average gains come from. The single biggest contributor here was Zen 4’s front-end changes, followed by load/store improvements, and then branch prediction improvements.
New Instructions: AVX-512, Automatic IBRS
Although Zen 4 is a more modest update to AMD’s CPU architecture, the company still managed to work in a fairly significant update to their instruction set support, with the addition of AVX-512 support.
The latest iteration of the Intel-developed Advanced Vector Extensions (AVX), AVX-512 is a fairly major addition to the AVX suite. Besides increasing the native vector width to 512-bits, AVX also improves the AVX instruction set with a number of new features and data types – a collection of features that keeps growing as Intel continues to add further extensions to AVX-512 itself.
Of particular interest for client CPUs and workloads, AVX-512 adds per-lane masking capabilities – allowing for individual lanes to be masked off rather than breaking up a vector for multiple passes – as well as new data manipulation instructions. This includes additional scatter/gather instructions, and instructions that are useful for neural network processing, such as bfloat16 support and a whole instruction sub-set (VNNI) for deep learning.

AVX-512 has an interesting history that, while we won’t cover in complete details, has left a patchwork of support across the client CPU landscape. While Intel added support in its client CPUs starting with Ice Lake and Rocket Lake (11th Gen Core), Intel also removed support for AVX-512 from their client CPUs starting with Alder Lake (13th Gen Core), owing to the fact that Alder Lake’s mixed-core strategy required that the only instructions used were supported by both the P-cores and E-cores. Which, in the case of the Atom-based Gracemont E-cores, was not available, leading to Intel disabling AVX-512 on Alder Lake parts even though the P-cores did support the new instructions.

As a result, the introduction of AVX-512 support actually gives AMD an edge over Intel right now. While AMD’s new CPUs can use the newer instruction set, Intel’s cannot, with Alder Lake limited to AVX2 and below.
But the situation is not a slam-dunk for AMD, either. In order to avoid the significant die space and power costs of actually implementing and operating a 512-bit wide SIMD, AMD has made the interesting decision to implement AVX-512 on top of a 256-bit SIMD, which happens to be the same width as Zen 3’s AVX2 SIMD. This means that while AMD can execute AVX-512 instructions, they have to do so over 2 cycles of their 256-bit SIMD. Which means that, on paper, AMD’s vector throughput per cycle per core has not improved from one generation to the next.
None the less, it’s a situation that benefits AMD for a couple of reasons. The first is the performance unlocked by the AVX-512 instructions. AVX-512 instructions are denser (there’s less fetching and control overhead), and some of these additions are instructions that manipulate data in ways that would take several cycles (or more) if implemented using AVX2 instructions. So AMD is still getting performance gains by supporting AVX-512, even without the doubled vector width.
The second benefit is that by keeping their SIMD narrower, AMD isn’t lighting up a billion dense, power-hungry transistors all at once. This is an ongoing challenge for 512-bit native SIMD designs that in Intel’s chips required them to back off on their clockspeeds to stay within their power budgets. So while a wider SIMD would technically be more efficient on pure AVX-512 throughput, the narrower SIMD allows AMD to keep their clockspeeds higher, something that’s particularly useful in mixed workloads where the bottleneck shifts between vector throughput and more traditional serial instructions.
Ultimately, for client CPUs, this is a nice feature to have, but it admittedly wasn’t a huge, market-shifting feature advantage with Rocket Lake. And it’s unlikely to be that way for AMD, either. Instead, the biggest utility for AVX-512 is going to be in the server space, where AMD’s Genoa processors will be going up against Intel Ice Lake (and eventually, Sapphire Rapids) parts with full AVX-512 implementations.

Finally, AMD is also adding/changing a handful of instructions related to security and virtualization. I won’t parrot AMD’s own slide on the matter, but for general desktop users, the most notable of these changes is how AMD is handling speculation control to prevent side-channel attacks. The Indirect Branch Restricted Speculation (IBRS) instruction, which is used on critical code paths to restrict the speculation of indirect branches, is now automatic. Any time a CPU core goes to CPL0/Ring 0 – the kernel ring and thus the most privileged ring – IBRS is automatically turned on, and similarly turned off when the CPU core exits CPL0.
Previously, software would need to specifically invoke IRBS using a model specific register, which although not a deal-breaker, was one more thing for an application (and application programmers) to keep track of in an already complex security landscape. Thus this change doesn’t directly add any new security features, but it makes it much easier to take advantage of an existing one.








205 Comments
View All Comments
emn13 - Monday, September 26, 2022 - link
The geekbench 4 ST results for the 7600x seem very low - is that benchmark result borked, or is there really something weird going on? Replyemn13 - Monday, September 26, 2022 - link
Sorry, I meant the geekbench 4 MT not ST results. The score trails way behind even the 3600xt. ReplySilver5urfer - Monday, September 26, 2022 - link
Good write up.First I would humbly request you to please include older Intel processors in your suite, it will be easier to understand the relative gains for eg the old 9th gen, 10th gen as a reliable place I see things all over on other sites, AT is at-least consistent so would be better if we have a ton of CPUs in one spot. Thanks
Now speaking about this launch.
The IOD is now improved by a huge factor so no more of that IF clock messing with the I/O controller and high voltage on the Zen 3 likes it's all improved so I think the USB fallout issues are fixed on this platform now. Plus the DP2.0 on iGPU is a dead giveaway on RDNA3 with DP2.0 as well.
IMC is also improved looking at it AMD operated with synchronized clocks with DRAM now they can do it without that since IF is now at 2000MHz and the IMC and DRAM are higher at 3000MHz to match the DDR5 data rates. Plus the EXPO is also lower latency, however the MCM design causes the AIDA benchmark to have high latency vs Intel even though Intel is operating at Gear 2 ratio with similar Uncore decoupled. Surprisingly the inter core latencies did not change much, maybe that's one of the key to improving more on AMD side gotta see what they will do for Zen 5.
The CPU clocks are insane, 5GHz on all 16C32T is a huge thing, plus even the 7600X is hitting 5.4GHz. Massive boost from AMD improving their design, plus the TSMC5N High Performance node is too good. However AMD did axed their temps and power. It's a very good move to not castrate the CPU with power limits and clocks now that's out it gets to spread it's wings. But the downside is, unlike Intel i7 series Ryzen 6 also gets hot meaning the budget buyers need to invest money in AIO vs older Zen 3 being fine on Air. That's a negative effect for AMD when they removed the Power Limits like Intel and let these rip to 250W.
Chipset downlink capping at PCIe4.0x4 was the biggest negative I can think of it, because Intel DMI is now 4.0x8 on ADL and RPL, RKL had it at 3.0x8 CML at 3.0x4. AMD is stuck to 4.0x4 from X570. Many will not even care, but it is a disadvantage when you pay top money for X670E they should have given us the PCIe5.0x4, AMD will give that in 2024 with Zen 5 X770 chipset that's my guess.
The ILM backplate engineering is solid that alone and the LGA1718 AM5 longevity itself is a major PLUS for AMD over LGA1700's bending ILM and EOL by 13th gen. Yes the 12th gen is a better purchase given how the Cooling requirement for i7 and i5 is not this high like R6 and R7 and the cheaper board costs plus 13th gen is coming and AMD's platform is new as well you would be a guinea pig. Depends on what people want and how much they can spend and what they want in longevity.
Performance is top notch for 7600X and 7950X absolute sheer dominance but the pricing is higher when you see the % variance vs Zen 3 and Intel 12th gen parts, and added AIO mandatory because they are hot. The gaming performance is as expected not much to see here and the 5800X3D still is a contender there but to me that chip is worthless as it cannot match any processor in high core count workloads. Although 7600X is a champion 6C12T and it beats 12C24T in many things and the 10C20T 10th gen Intel too. IPC is massive in ST and MT workloads as expected. AMD Zen 4 will decimate ARM, Apple has only one thing lol muh efficiency all that BGA baggage, locked down ecosystem is free.
RPSC3 perf at TPU's Red Dead Redemption is weird as I do not see any gains over Intel, given how much of a beast this AVX512 is on Zen 4 with 2x256Bit without AVX offset that too maybe they are not using AVX512. Plus their AMD Zen 3 gauging is also bad because they do not work well vs Intel 9th gen even, I wish you guys cover Dolphin emu, PCSX2, RPCS3 and Switch Emulators.
I think best option is to wait for next year and buy these parts as they will drop, right now no PCIe5.0 SSD in high capacity. no PCIe5.0 GPU even that Nvidia skimped on it. No use of the new platform unless one is running a super damn old CPU and GPU setups.
Shame that OC is totally dead, Zen 3 was hamfisted with its Curve Optimizer and Memory tuning becoming a head ache due to how AGESA was handled and the 1.4v high voltage and lack of documentation. Zen 4 it's even 1.0-1.2v still no OC because AMD's design basically is now pushed to maximum with it's Core TJMax temps and how it works on the basis of Core temperatures over everything else. There's no room here, AIO is saturated with 90C here. Too high heat density on AMD side similar to Intel 11th and 12th gen. Although Intel can go upto 350W and hit all cores at higher vs AMD 250W max. Well OC was on life support, only Intel is basically keeping it alive at this point after 10th gen it became worse and 12th very hot and high heat and now 13th gotta see if that DLVR regulator helps or not.
All in all a good CPU but has some downsides to it. Not much worth for existing 2020 class HW folks at all. Better wait when DDR5 matures even further and more PCIe5.0 becomes prevalent. Reply
Threska - Monday, September 26, 2022 - link
Maybe people will start delidding.https://youtu.be/y_jaS_FZcjI Reply
Silver5urfer - Tuesday, September 27, 2022 - link
That Delid is a direct die, it will 100% ruin the AM5 socket for longevity and the whole CPU too. That guy runs HWBot, ofc he will make a video on his bs delid kits. Nobody should run any CPU completely blowing the IHS off. You will have a ton of issues with that. Water leak, CPU silicon die crack due to Thermodynamics and the pressure differences over the time, Liquid Metal leak. Total bust of Warranty on any parts once that LM drops on your machine game over for $5000 worth rig there.AMD should have done some more improvements and reduced the max TJ Max to say 90 at-least but it's what it is unfortunately (for high temps and cooling requirements) and fortunately (to have super high performance) Reply
Threska - Tuesday, September 27, 2022 - link
There are some in the comments both wondering if lapping would achieve the same and the thicker lid was giving some room for future additions like 3D cache, etc. Replyabufrejoval - Wednesday, September 28, 2022 - link
I'm not sure that PCIe 4.0 "DMI" downlink capping is a hard cap per se by the SoC, but really the result of negotiations with the ASmedia chipset, which can't do better. I'd assume once someone comes up with a PCI 5.0 chipset/switch, there is no reason it won't do PCIe 5.0. It's just a bunch of 4 lanes, that happen to be connected to ASmedia PCIe 4.0 chips on all currrent mainboards.Likewise I don't see why you couldn't add the second chipset/switch to the "NVMe" port of the SoC or any of the bifurcated slots: what you see is motherboard design choices not Ryzen 7000 limitations. That just has 24 PCIe 5.0 lanes to offer in many bundle variants. It's the mainboard that straps all that flexibility to slots and ports.
I don't see that you have to invest into AIO coolers, *unless* you want/need top clocks on all cores. E.g. if your workloads are mixed, e.g. a few threads that profit from top clocks for interactive workloads (including games) and others that are more batch oriented like large compiles or renders, you may get maximum personal value even from an air cooler that only handles 150 Watts.
Because the interactive stuff will rev to 5.crazy clocks on say 4-8 cores, while for the batch stuff you may not wait in front of the screen anyway (or do other stuff while it's chugging in the background). So if it spends 2 extra hours on a job that might take 8 hours on AIO, that may be acceptable if it saves you from putting fluids into your computer.
In a way AMD is now giving you a clear choice: The performance you can obtain from the high-end variants is mostly limited by the amount of cooling you want to provide. And as a side effect it also steers the power consumption: you provide 150 Watts worth of cooling, it won't consume more except for short bursts.
In that regard it's much like a 5800U laptop, that you configure between say 15/28/35 Watts of TDP for distinct working points in terms of power vs. cooling/noise (and battery endurance).
Hopefully AMD will provide integration tools on both Windows and Linux to check/measure/adjust the various power settings at run-time, so you can adjust your machine to your own noise/heat/performance bias, depending on the job it's running. Reply
Dug - Monday, September 26, 2022 - link
"While these comments make sense, ultimately very few users apply memory profiles (either XMP or other) as they require interaction with the BIOS"This is getting so old. Your assumption is incorrect which should be obvious by the millions of articles and youtube videos on building computers. Not to mention your entire article is not even directed to "general public" but to enthusiasts. Otherwise why write out this entire article? Just say you put a cpu in a motherboard and it works. Say it's fast. Article done.
Why not test with Curve Optimizer? Reply
Oxford Guy - Tuesday, September 27, 2022 - link
This text appears again and again for the same reason Galileo was placed under house arrest. Replysocket420 - Monday, September 26, 2022 - link
Could someone, preferably Ryan or Gavin, please elaborate on what this sentence - "the new chip is compliant with Microsoft’s Pluton initiative as well" - actually means? This is the only review I could find that mentions Pluton in conjunction with desktop Zen 4 at all, but merely saying it's "compliant" is a weird way of wording it. Is Pluton on-die and enabled by default in Ryzen 7000 desktop CPUs? Reply