AMD Zen 4 Ryzen 9 7950X and Ryzen 5 7600X Review: Retaking The High-End
by Ryan Smith & Gavin Bonshor on September 26, 2022 9:00 AM ESTZen 4 Architecture: Power Efficiency, Performance, & New Instructions
Now that we’ve had a chance to take a look at the AM5 platform surrounding the new Ryzen 7000 chips, as well as the new IOD that completes the high-end Ryzen chips, let’s dive into the heart of matters: the Zen 4 CPU cores.
As laid out in previous pages, a big element in AMD’s design goals for the Ryzen 7000 platform was to modernize it, adding support for things like PCIe 5.0 and DDR5, as well as integrating more fine-grained power controls. And while this attention meant that AMD’s collective attention was split between the CPU cores and the rest of the platform, AMD’s CPU cores are far from being ignored here. Still, it’s fair to say that AMD’s goal for the Zen 4 architecture has not been a radical overhaul of their core CPU architecture. For that, you’ll want to wait for Zen 5 in 2024.
Instead, Zen 4 is a further refinement of AMD’s Zen 3 architecture, with AMD taking advantage of things like the new AM5 platform and TSMC’s 5nm process to further boost performance. There are some important changes here that are allowing AMD to deliver an average IPC increase of 13%, and combined with improvements to enable higher clockspeeds and greater power efficiency for both single-threaded and multi-threaded workloads, no part of AMD’s CPU performance has gone untouched.

Zen 4 Power: More Efficient, More Power-Hungry
We’ll start with a look at power efficiency, since power consumption plays a huge part in the Zen 4 story at both ends of the curve.
By tapping TSMC’s current-generation 5nm, process, AMD is enjoying the advantage of a full node shrink for their CPU cores. Thus far TSMC 5nm (and its 4nm derivative) is proving to be the powerhouse process of its generation, as TSMC’s clients have seen some solid gains in power efficiency and transistor density moving from 7nm to 5nm. Meanwhile TSMC’s competitors are either struggling by delivering less efficient 4nm-class nodes (Samsung), or they’ve yet to deliver a 4nm-class node at all (Intel). In other words, for the moment TSMC’s 5nm-class nodes are as good as it gets, putting AMD in a great position to take advantage of the benefits.
Coupled with this are all of the various platform power improvements that come with AM5 and the new 6nm IOD. These include the 3 variable power rails, SVI3 VRM monitoring, and AMD’s lower-power Infinity Fabric Links. As a result, the Ryzen 7000 chips enjoy a significant power efficiency advantage versus the Ryzen 5000 chips.
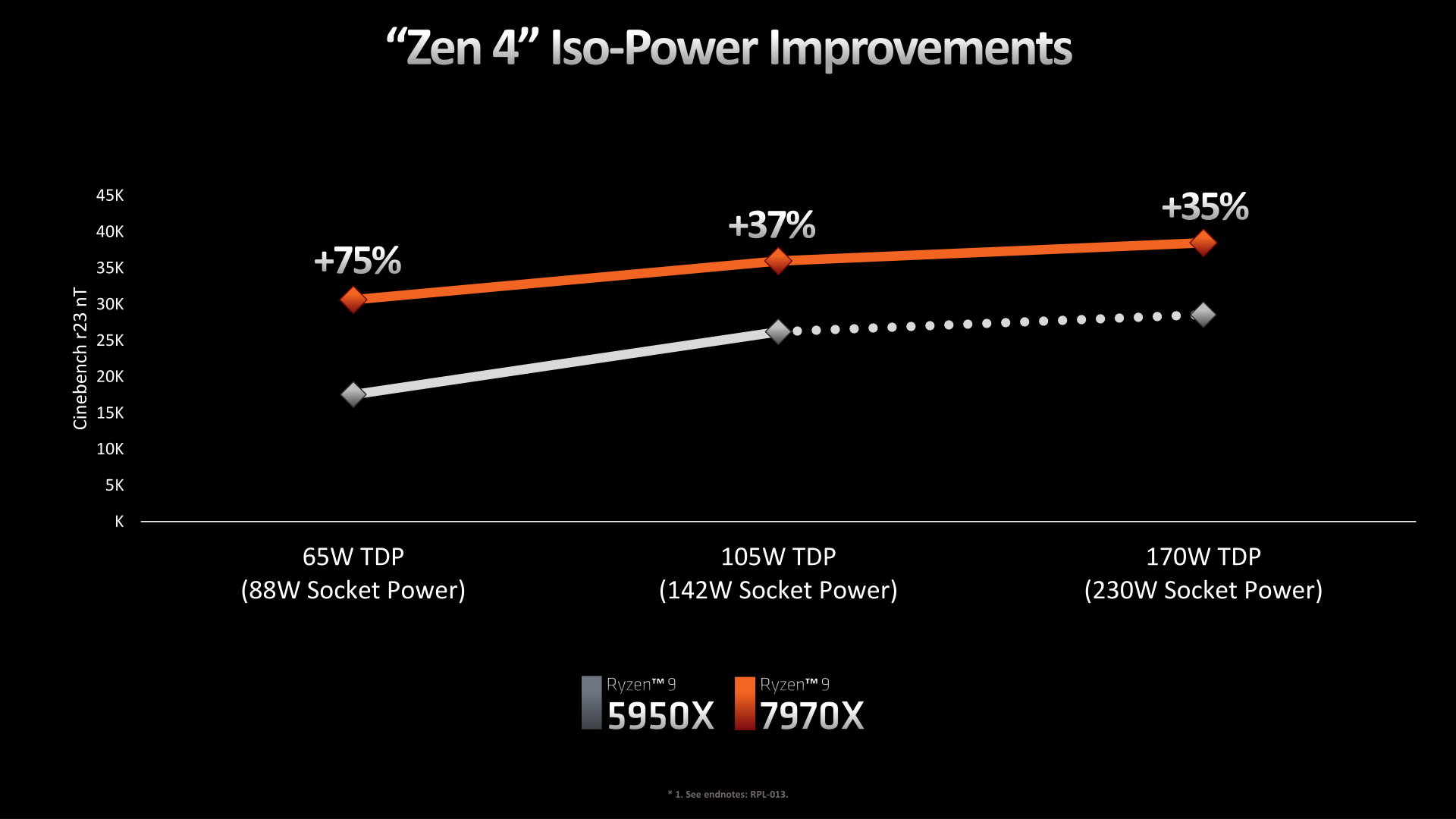
How much of an improvement, in turn, depends on where on the voltage/frequency curve you end up. As we alluded to earlier when talking about AM5, one of AMD’s design goals was to provide more power to Ryzen 7000 chips so that they could go farther into the vf curve and keep their cores running at a higher frequency in MT-heavy workloads.
The net result is that, according to AMD’s data, the company is seeing extensive power efficiency gains at lower TDPs. In this case, pitting a 5950X against a 7950X with a maximum socket power of 88 Watts, AMD is seeing a 75% increase in performance on Cinebench R23 nT. This is something of a worst-case scenario for the older Ryzen chip, as it tended to be TDP limited even at is native TDP, and the relatively high idle power draw of the IOD and the rest of the platform further ate into that. As a result, the 5950X needs to pull back on clockspeeds significantly at lower TDPs. For Ryzen 7000/Zen 4 on the other hand, AMD’s newer architecture fairs much better; it still takes a hit from the TDP drop, but not by nearly as much.
Meanwhile, increasing the socket power to 142 (5950X’s stock power) and then to 230W (7950X’s stock power) still produces a significant speed up in performance, but we’re certainly into the area of diminishing returns. In this case the 7950X has a 37% lead and 35% lead at 142W and 230W respectively.
We’ll take a look at more power data for the new Ryzen 7000 chips a bit later in our review, but the basic pattern is clear: Zen 4 can be a very power efficient architecture. But AMD is also discarding some of that efficiency advantage in the name of improving raw performance. Especially in multi-threaded workloads, for high-end chips like the 7950X the performance gains we’re seeing are as much from higher TDPs as they are higher IPCs and improved power efficiency.
This will make AMD’s eventual Zen 4 mobile products (Phoenix Point) an especially interesting product to keep an eye on. The greater focus on power efficiency (and harder cap on top TDPs) means that we may not yet have seen Zen 4 put its best foot forward when it comes to power efficiency.
Clockspeeds: Going Faster Means Being Faster
One way that’s always a good method to improve your CPU performance is just to flat-out increase clockspeeds. Tried and true, this drove the x86 CPU industry for most of its first 30 years before the laws of physics (and specifically, the death of Dennard Scaling) put the brakes on massive generation-on-generation clockspeed gains. Still, AMD and Intel like to squeeze out higher frequencies when they can, and in the case of AMD’s CPU architecture, TSMC’s 5nm process has provided for some nice gains here, finally pushing AMD well over the (stubborn) 5GHz mark.

For AMD’s high-end Ryzen 7000 desktop processors, the top turbo frequencies are now as high as 5.7GHz for the Ryzen 9 7950X, and even the slowest Ryzen 5 7600X is rated to hit 5.3GHz. And in both cases, there is still a bit more headroom still when using Precision Boost Optimization 2 (PBO2), allowing chips to potentially eek out another 100MHz or so. For AMD’s top-end part then, we’re looking at a 16% increase in turbo clockspeeds, while the 7600X is clocked some 15% faster than its predecessor.
According to AMD’s engineers, there is no singular magic trick here that has allowed them to boost clockspeeds to the high 5GHz range on Zen 4, nor has the company sacrificed any IPC to allow for higher clockspeeds (e.g. lengthening pipelines). TSMC’s 5nm process sure helped a lot in this regard, but AMD’s technical relationship with TSMC also improved as the company’s CPU engineers became familiar with designing and optimizing CPUs for TSMC’s 7nm and 6nm process nodes. As a result, the two companies were able to better work together to reliably get higher frequencies out of AMD’s CPU cores, with AMD going as far as to integrating some TSMC IP instead of relying on more traditional design partners.
Even with that, Zen 4 actually came in a bit below AMD’s expectations, if you can believe that. According to the company’s engineers, they were hoping to hit 6GHz on this part, something that didn’t quite come to fruition. So AMD’s users will have to settle for just 5.7GHz, instead.
Zen 4 IPC: Getting 13% More
On the other side of the performance equation we have IPC improvements. AMD’s broader focus on platform design for the Ryzen 7000 generation means that the IPC gains aren’t quite as great as what we saw on Zen 3 or Zen 2, but they’re not to be ignored, either. Even without a massive overhaul of AMD’s execution back-end – and with only a moderate update to the front-end – AMD was still able to squeeze out an average IPC gain of 13% across a couple of dozen benchmarks, only 2 percentage points lower than the 15% gains AMD delivered with the Zen 2 architecture in 2019.
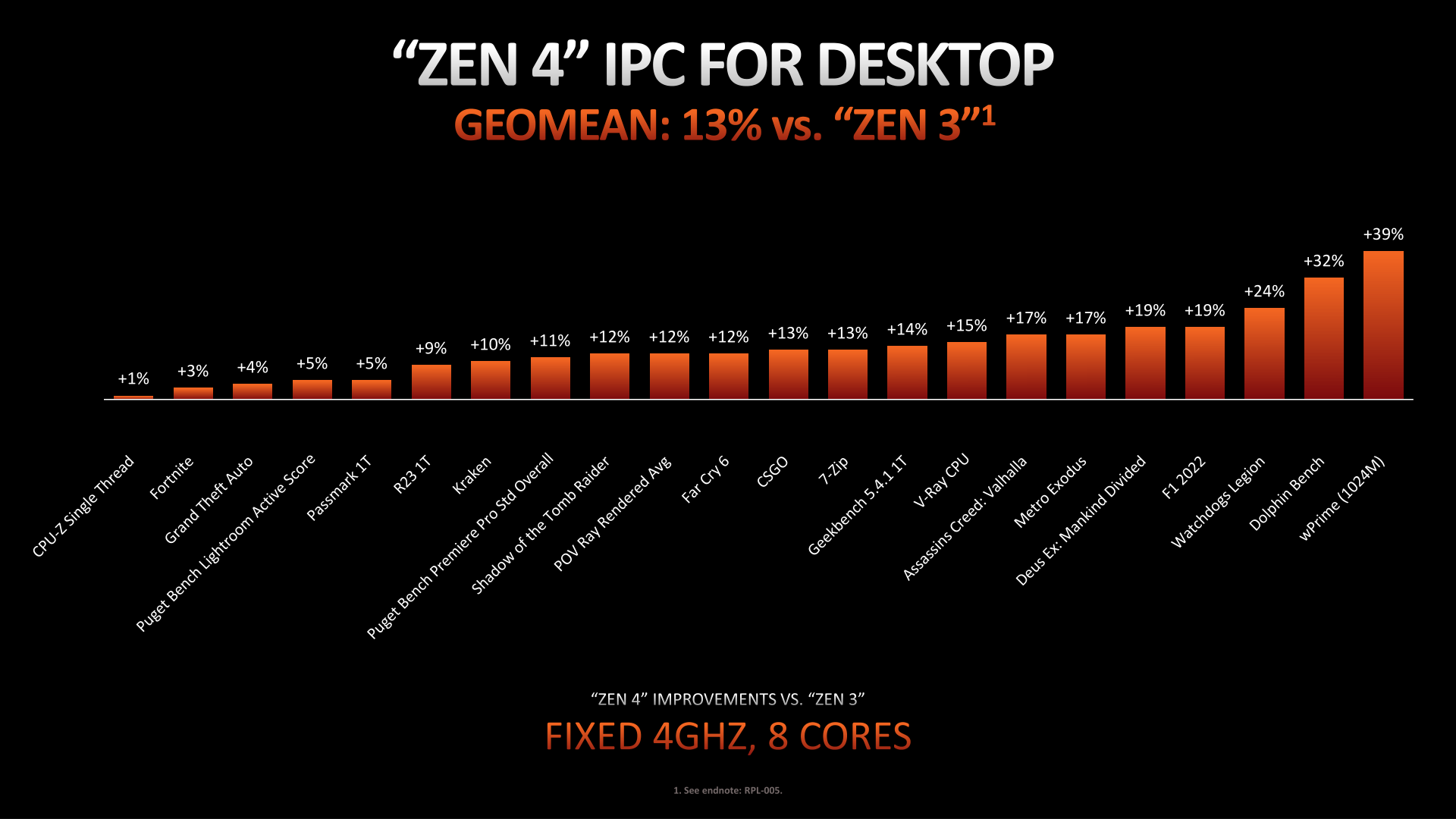
We won’t fixate on any one workload here, but it does run the gamut. At an iso-frequency of 4GHz, Zen 4 delivers anything from a tiny increase to 39% at the top end. In traditional PC performance fashion, the gains from one generation to the next are workload-dependent. So a 13% average does leave plenty of wiggle-room for either greater or lesser gains, as we’ll see in our full benchmark results.
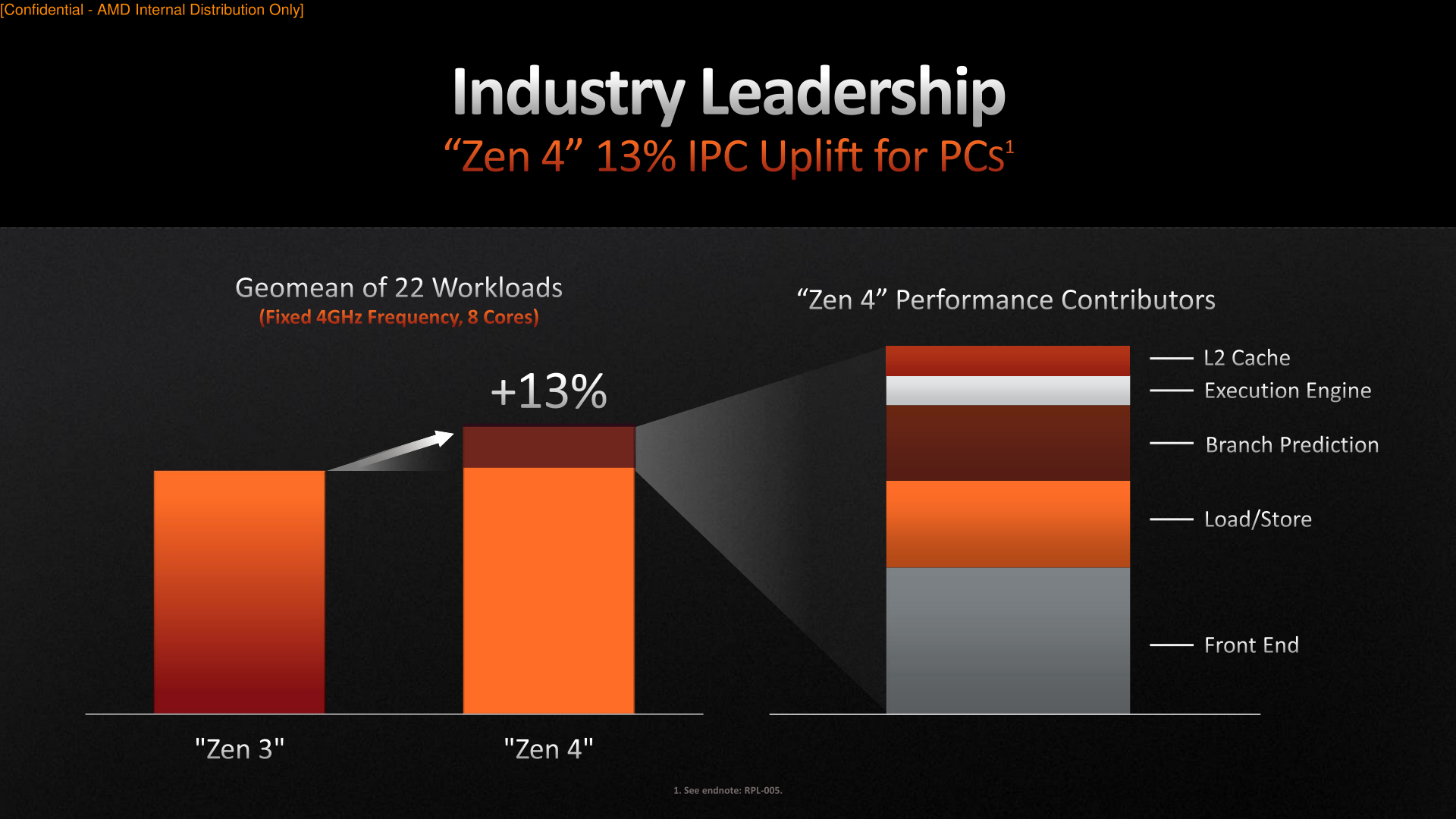
AMD has also provided a handy IPC contributor breakdown, showing where those 13% average gains come from. The single biggest contributor here was Zen 4’s front-end changes, followed by load/store improvements, and then branch prediction improvements.
New Instructions: AVX-512, Automatic IBRS
Although Zen 4 is a more modest update to AMD’s CPU architecture, the company still managed to work in a fairly significant update to their instruction set support, with the addition of AVX-512 support.
The latest iteration of the Intel-developed Advanced Vector Extensions (AVX), AVX-512 is a fairly major addition to the AVX suite. Besides increasing the native vector width to 512-bits, AVX also improves the AVX instruction set with a number of new features and data types – a collection of features that keeps growing as Intel continues to add further extensions to AVX-512 itself.
Of particular interest for client CPUs and workloads, AVX-512 adds per-lane masking capabilities – allowing for individual lanes to be masked off rather than breaking up a vector for multiple passes – as well as new data manipulation instructions. This includes additional scatter/gather instructions, and instructions that are useful for neural network processing, such as bfloat16 support and a whole instruction sub-set (VNNI) for deep learning.

AVX-512 has an interesting history that, while we won’t cover in complete details, has left a patchwork of support across the client CPU landscape. While Intel added support in its client CPUs starting with Ice Lake and Rocket Lake (11th Gen Core), Intel also removed support for AVX-512 from their client CPUs starting with Alder Lake (13th Gen Core), owing to the fact that Alder Lake’s mixed-core strategy required that the only instructions used were supported by both the P-cores and E-cores. Which, in the case of the Atom-based Gracemont E-cores, was not available, leading to Intel disabling AVX-512 on Alder Lake parts even though the P-cores did support the new instructions.

As a result, the introduction of AVX-512 support actually gives AMD an edge over Intel right now. While AMD’s new CPUs can use the newer instruction set, Intel’s cannot, with Alder Lake limited to AVX2 and below.
But the situation is not a slam-dunk for AMD, either. In order to avoid the significant die space and power costs of actually implementing and operating a 512-bit wide SIMD, AMD has made the interesting decision to implement AVX-512 on top of a 256-bit SIMD, which happens to be the same width as Zen 3’s AVX2 SIMD. This means that while AMD can execute AVX-512 instructions, they have to do so over 2 cycles of their 256-bit SIMD. Which means that, on paper, AMD’s vector throughput per cycle per core has not improved from one generation to the next.
None the less, it’s a situation that benefits AMD for a couple of reasons. The first is the performance unlocked by the AVX-512 instructions. AVX-512 instructions are denser (there’s less fetching and control overhead), and some of these additions are instructions that manipulate data in ways that would take several cycles (or more) if implemented using AVX2 instructions. So AMD is still getting performance gains by supporting AVX-512, even without the doubled vector width.
The second benefit is that by keeping their SIMD narrower, AMD isn’t lighting up a billion dense, power-hungry transistors all at once. This is an ongoing challenge for 512-bit native SIMD designs that in Intel’s chips required them to back off on their clockspeeds to stay within their power budgets. So while a wider SIMD would technically be more efficient on pure AVX-512 throughput, the narrower SIMD allows AMD to keep their clockspeeds higher, something that’s particularly useful in mixed workloads where the bottleneck shifts between vector throughput and more traditional serial instructions.
Ultimately, for client CPUs, this is a nice feature to have, but it admittedly wasn’t a huge, market-shifting feature advantage with Rocket Lake. And it’s unlikely to be that way for AMD, either. Instead, the biggest utility for AVX-512 is going to be in the server space, where AMD’s Genoa processors will be going up against Intel Ice Lake (and eventually, Sapphire Rapids) parts with full AVX-512 implementations.

Finally, AMD is also adding/changing a handful of instructions related to security and virtualization. I won’t parrot AMD’s own slide on the matter, but for general desktop users, the most notable of these changes is how AMD is handling speculation control to prevent side-channel attacks. The Indirect Branch Restricted Speculation (IBRS) instruction, which is used on critical code paths to restrict the speculation of indirect branches, is now automatic. Any time a CPU core goes to CPL0/Ring 0 – the kernel ring and thus the most privileged ring – IBRS is automatically turned on, and similarly turned off when the CPU core exits CPL0.
Previously, software would need to specifically invoke IRBS using a model specific register, which although not a deal-breaker, was one more thing for an application (and application programmers) to keep track of in an already complex security landscape. Thus this change doesn’t directly add any new security features, but it makes it much easier to take advantage of an existing one.








205 Comments
View All Comments
vortmax2 - Sunday, October 16, 2022 - link
Some people don't want to limit TDP themselves. Nothing wrong with that. ReplyTechie2 - Tuesday, September 27, 2022 - link
What a screwed up launch of Ryzen 7000 CPUs and AM5 mobos by e-tailers. DDR5 EXPO DRAM showed up online a few days ago. On 9-27-22 it looks like e-tailers are actually hiding the four Ryzen 7000 CPUs to sell older stock. The AM5 mobos which have been sitting in inventory for weeks were not posted online until early morning instead of at midnight as in the past. You'd think by now they could figure out how to do a proper launch of a new CPU or platform but evidently not when it's AMD.No consumer grade Gen 5 SSDs listed by e-tailers that I could find. Are PC builders suppose to just wait until Nov. to see if they actually show up? AMD's partners may be cooperating with AMD but the purchasing experience is a piss poor sales methodology being employed IMNHO.
YMMV Reply
nandnandnand - Tuesday, September 27, 2022 - link
AMD said weeks ago that PCIe 5.0 SSDs would be coming in November.Nobody should be buying this stuff on day 1 unless they like being findom'd by corporations. Reply
yhselp - Tuesday, September 27, 2022 - link
First-draft-copy issues aside, this article is written exceptionally well. The information is excellent and extensive as usual, but I feel like there's been a step-up in the way its presented/explained. Kudos and thank you. Replyyhselp - Tuesday, September 27, 2022 - link
it's* goddamit Replyvortmax2 - Sunday, October 16, 2022 - link
Great post. So many grammar police on here that can't help but criticize and take away from the actual purpose of the article. ReplyHardwareDufus - Tuesday, September 27, 2022 - link
Clearly both manufacturers are producing vey compelling products this time around. At the $600-$700 mark we have two CPUs trading blows; R9-7950X (Zen4) & just announced i9-13900K (RaptorLake) We will have updates of both lines, with AMD adding 3D Cache and Intel increasing Boost Speeds. Probably can't go wrong with either choice, neither one dominates the other completely.I think I'll bite this time around. Yeah I know Zen5 will be a new architecture and Intel will adopt chiplets and all of the benefits that accompany them... But, I think either one of these chips, probably available in volume in 1st quarter 2023, will serve most folks well.
In the case of Intel, you can continue to use DD4 and 600 series chipsets. However really take advantage of the capabilities of the chip, DDR5 and motherboards featureing 700 series chipsets will be available, on par with Zen 4 requiring a DDR5 and otherboards featuring the new AM5 socket and 600 series chipsets. Apples to Apples when comparing the requirements to go ALL In on performance. Reply
HardwareDufus - Tuesday, September 27, 2022 - link
Dang, that was some awesome typing I just did there... Replynandnandnand - Tuesday, September 27, 2022 - link
3D cache will dominate over a couple hundred extra MHz in frequency (13900KS). ReplyHifihedgehog - Tuesday, September 27, 2022 - link
@nandnandnand: That may well be true, but that's the future and months out yet. Ryzen 7000 non X3D has to sell between then and now or AMD is not going to be posting a pretty quarter. The 13900K is far cheaper in platform and unit price and will meet or exceed the 7950X for now. DDR5 and AM5 motherboards coupled with a higher price will be Ryzen 7000 series undoing, and good too. AMD needs to realize people purchase because of intrinsic quality, not brand loyalty. Reply