The Bulldozer Review: AMD FX-8150 Tested
by Anand Lal Shimpi on October 12, 2011 1:27 AM ESTThe Architecture
We'll start, logically, at the front end of a Bulldozer module. The fetch and decode logic in each module is shared by both integer cores. The role this logic plays is to fetch the next instruction in the thread being executed, decode the x86 instruction into AMD's own internal format, and pass the decoded instruction onto the scheduling hardware for execution.
AMD widened the K8 front end with Bulldozer. Each module is now able to fetch and decode up to four x86 instructions from a single thread in parallel. Each of the four decoders are equally capable. Remembering that each Bulldozer module appears as two cores, the front end can only pick 4 instructions to fetch and decode from a single thread at a time. A single Bulldozer module can switch between threads as often as every clock.
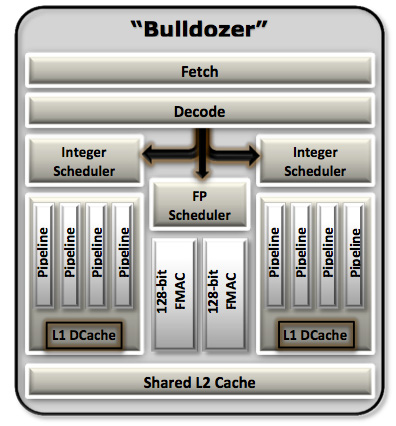
Decode hardware isn't very expensive on its own, but duplicating it four times across multiple cores quickly adds up. Although decode width has increased for a single core, multi-core Bulldozer configurations can actually be at a disadvantage compared to previous AMD architectures. Let's look at the table below to understand why:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
For a single instruction thread, Bulldozer offers more front end bandwidth than its predecessor. The front end is wider and just as capable so this makes sense. But note what happens when we scale up core count.
Since fetch and decode hardware is shared per module, and AMD counts each module as two cores, given an equivalent number of cores the old Phenom II actually offers a higher peak instruction fetch/decode rate than the FX. The theory is obviously that the situations where you're fetch/decode bound are infrequent enough to justify the sharing of hardware. AMD is correct for the most part. Many instructions can take multiple cycles to decode, and by switching between threads each cycle the pipelined front end hardware can be more efficiently utilized. It's only in unusually bursty situations where the front end can become a limit.
Compared to Intel's Core architecture however, AMD is at a disadvantage here. In the high-end offerings where Intel enables Hyper Threading, AMD has zero advantage as Intel can weave in instructions from two threads every clock. It's compared to the non-HT enabled Core CPUs that the advantage isn't so clear. Intel maintains a higher instantaneous decode bandwidth per clock, however overall decoder utilization could go down as a result of only being able to fill each fetch queue from a single thread.
After the decoders AMD enables certain operations to be fused together and treated as a single operation down the rest of the pipeline. This is similar to what Intel calls micro-ops fusion, a technology first introduced in its Banias CPU in 2003. Compare + branch, test + branch and some other operations can be fused together after decode in Bulldozer—effectively widening the execution back end of the CPU. This wasn't previously possible in Phenom II and obviously helps increase IPC.
A Decoupled Branch Predictor
AMD didn't disclose too much about the configuration of the branch predictor hardware in Bulldozer, but it is quick to point out one significant improvement: the branch predictor is now significantly decoupled from the processor's front end.
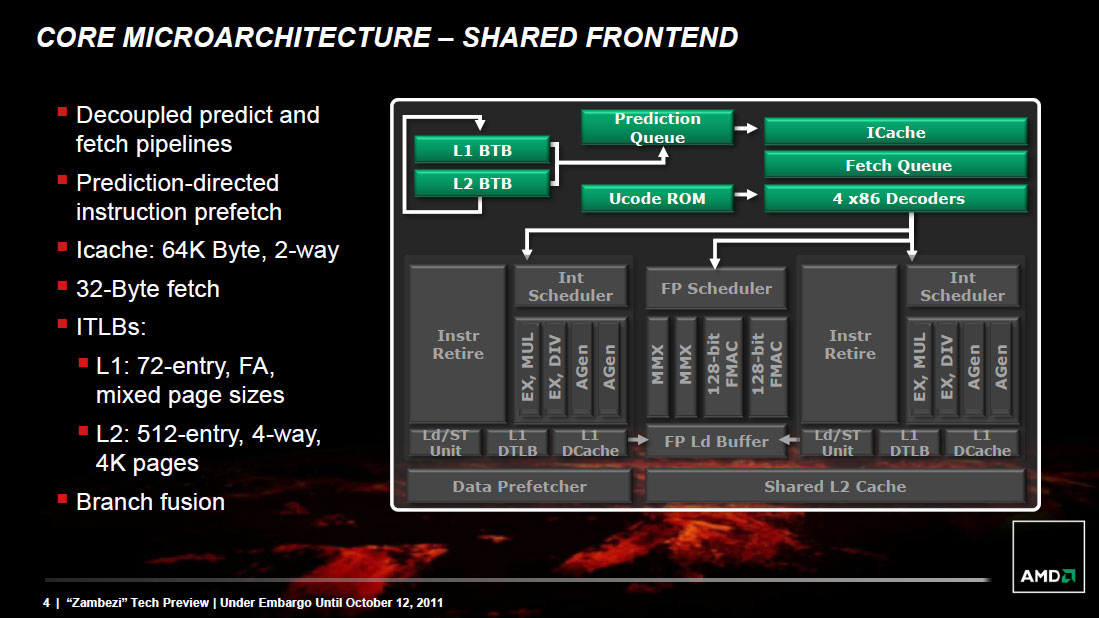
The role of the branch predictor is to intercept branch instructions and predict their target address, rather than allowing for tons of cycles to go by until the branch target is known for sure. Branches are predicted based on historical data. The more data you have, and the better your branch predictors are tuned to your workload, the more accurate your predictions can be. Accurate branch prediction is particularly important in architectures with deep pipelines as a mispredict causes more instructions to be flushed out of the pipe. Bulldozer introduces a significantly deeper pipeline than its predecessor (more on this later), and thus branch prediction improvements are necessary.
In both Phenom II and Bulldozer, branches are predicted in the front end of the pipe alongside the fetch hardware. In Phenom II however, any stall in the fetch pipeline (e.g. fetching an instruction that wasn't in cache) would stop the whole pipeline including future branch predictions. Bulldozer decouples the branch prediction hardware from the fetch pipeline by way of a prediction queue. If there's a stall in the fetch pipeline, Bulldozer's branch prediction hardware is allowed to run ahead and continue making future predictions until the prediction queue is full.
We'll get to the effectiveness of this approach shortly.
Scheduling and Execution Improvements
As with Sandy Bridge, AMD migrated to a physical register file architecture with Bulldozer. Data is now only stored in one location (the physical register file) and is tracked via pointers back to the PRF as operations make their way through the execution engine. This is a move to save power as copying data around a chip is hardly power efficient.
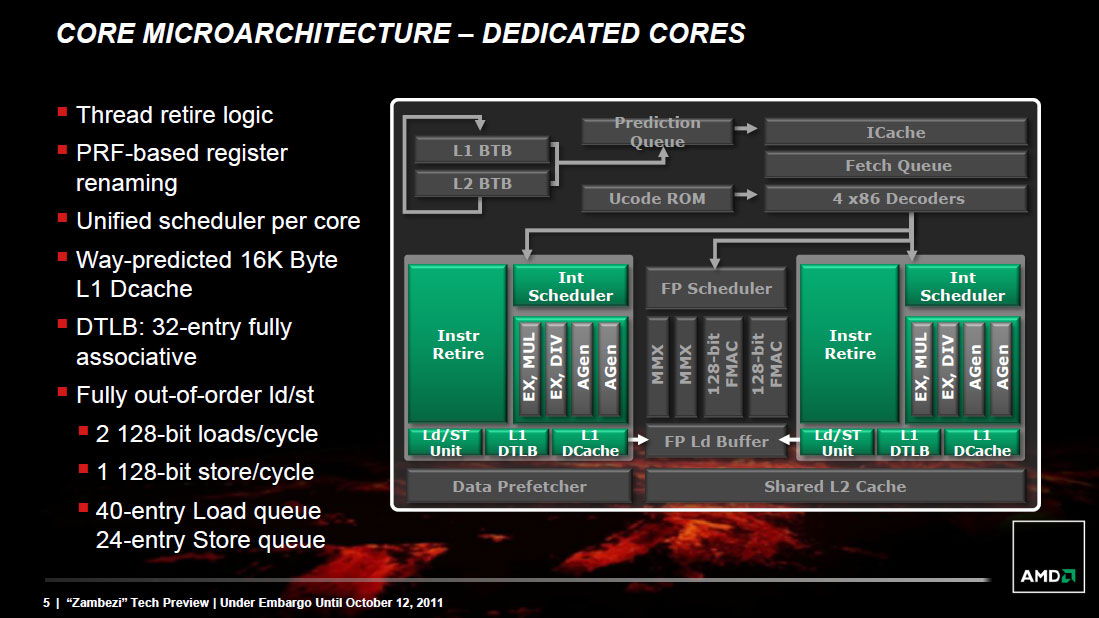
The buffers and queues that feed into the execution engines of the chip are all larger on Bulldozer than they were on Phenom II. Larger data structures allows for better instruction level parallelism when trying to execute operations out of order. In other words, the issue hardware in Bulldozer is beefier than its predecessor.
Unfortunately where AMD took one step forward in issue hardware, it does a bit of a shuffle when it comes to execution resources themselves. Let's start with the positive: Bulldozer's integer execution cores.
Integer Execution
Each Bulldozer module features two fully independent integer cores. Each core has its own integer scheduler, register file and 16KB L1 data cache. The integer schedulers are both larger than their counterparts in the Phenom II.
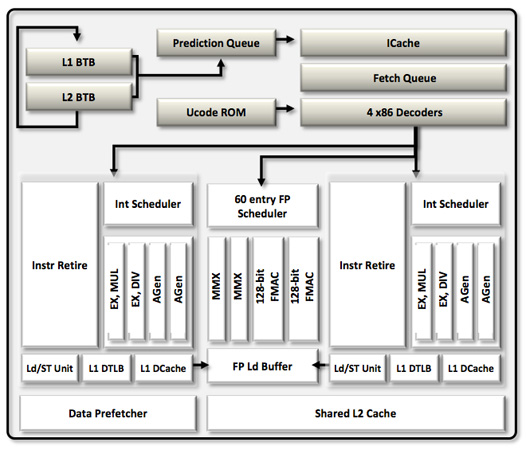
The biggest change here is each integer core now has two ports instead of three. A single integer core features two AGU/ALU ports, compared to three in the previous design. AMD claims the third ALU/AGU pair went mostly unused in Phenom II, and as a result it's been removed from Bulldozer.
With larger structures feeding into the integer cores, AMD should be able to have an easier time of making use of the integer units than in previous designs. AMD could, in theory, execute more integer operations per core in Phenom II however AMD claims the architecture was typically bound elsewhere.
The Shared FP Core
A single Bulldozer module has a single shared FP core for use by up to two threads. If there's only a single FP thread available, it is given full access to the FP execution hardware, otherwise the resources are shared between the two threads.
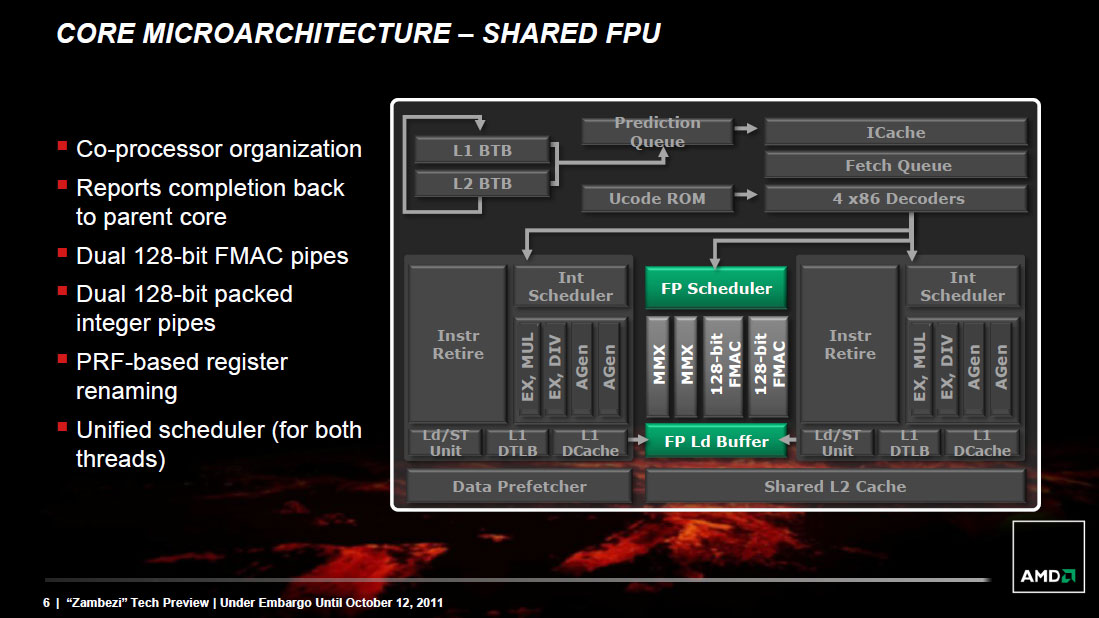
Compared to a quad-core Phenom II, AMD's eight-core (quad-module) FX sees no drop in floating point execution resources. AMD's architecture has always had independent scheduling for integer and floating point instructions, and we see the same number of execution ports between Phenom II cores and FX modules. Just as is the case with the integer cores, the shared FP core in a Bulldozer module has larger scheduling hardware in front of it than the FPU in Phenom II.
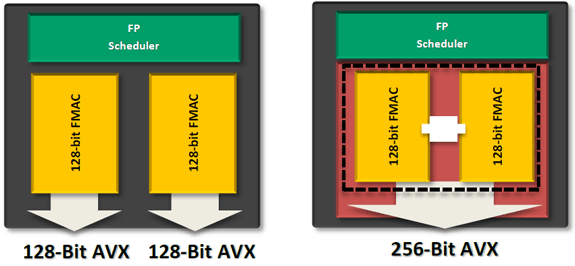
The problem is AMD had to increase the functionality of its FPU with the move to Bulldozer. The Phenom II architecture lacks SSE4 and AVX support, both of which were added in Bulldozer. Furthermore, AMD chose Bulldozer as the architecture to include support for fused multiply-add instructions (FMA). Enabling FMA support also increases the relative die area of the FPU. So while the throughput of Bulldozer's FPU hasn't increased over K8, its capabilities have. Unfortunately this means that peak FP throughput running x87/SSE2/3 workloads remains unchanged compared to the previous generation. Bulldozer will only be faster if newer SSE, AVX or FMA instructions are used, or if its clock speed is significantly higher than Phenom II.
Looking at our Cinebench 11.5 multithreaded workload we see the perfect example of this performance shuffle:

Despite a 9% higher base clock speed (more if you include turbo core), a 3.6GHz 8-core Bulldozer is only able to outperform a 3.3GHz 6-core Phenom II by less than 2%. Heavily threaded floating point workloads may not see huge gains on Bulldozer compared to their 6-core predecessors.
There's another issue. Bulldozer, at least at launch, won't have to simply outperform its quad-core predecessor. It will need to do better than a six-core Phenom II. In this comparison unfortunately, the Phenom II has the definite throughput advantage. The Phenom II X6 can execute 50% more SSE2/3 and x87 FP instructions than a Bulldozer based FX.
Since the release of the Phenom II X6, AMD's major advantage has been in heavily threaded workloads—particularly floating point workloads thanks to the sheer number of resources available per chip. Bulldozer actually takes a step back in this regard and as a result, you will see some of those same workloads perform worse, if not the same as the outgoing Phenom II X6.
Compared to Sandy Bridge, Bulldozer only has two advantages in FP performance: FMA support and higher 128-bit AVX throughput. There's very little code available today that uses AMD's FMA instruction, while the 128-bit AVX advantage is tangible.
Cache Hierarchy and Memory Subsystem
Each integer core features its own dedicated L1 data cache. The shared FP core sends loads/stores through either of the integer cores, similar to how it works in Phenom II although there are two integer cores to deal with now instead of just one. Bulldozer enables fully out-of-order loads and stores, an improvement over Phenom II putting it on parity with current Intel architectures. The L1 instruction cache is shared by the entire bulldozer module, as is the L2 cache.
The instruction cache is a large 64KB 2-way set associative cache, similar in size to the Phenom II's L1 cache but obviously shared by more "cores". A four-core Phenom II would have 256KB of total L1 I-Cache, while a four core Bulldozer will have half of that. The L1 data caches are also significantly smaller than Bulldozer's predecessor. While Phenom II offered a 64KB L1 D-Cache per core, Bulldozer only offers 16KB per integer core.

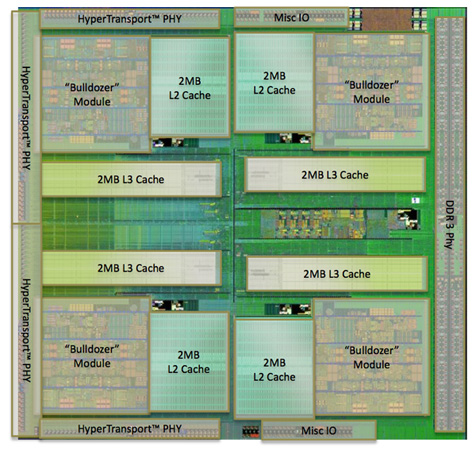
The L2 cache is much larger than what we saw in multi-core Phenom II designs however. Each Bulldozer module has a private 2MB L2 cache.
There's a single 8MB L3 cache that's shared among all Bulldozer modules on a chip. In its first incarnation, AMD has no plans to offer a desktop part without an L3 cache. However AMD indicated that the L3 cache was only really useful in server workloads and we might expect future Bulldozer derivatives (ahem, Trinity?) to forgo the L3 cache entirely as a result.
Cache accesses require more clocks in Bulldozer, due to a combination of size and AMD's desire to make Bulldozer a very high clock speed part...








430 Comments
View All Comments
Elric42 - Thursday, December 1, 2011 - link
I wanted to say one thing i dont have one but a friend of mine does and he showed me somthing my i5 cant do he was playing a game called crissis if thats how u spell it and running a video editting program at he same time well i cant do that with my i5 if i did the game would start to lag crissis takes alot out of your cpu bad programing even video cards have trouble with the game but bd seems to muti task better then what my i5 can do just wondering if its more for peeps who do alot of stuff at one time.ZyferXY - Monday, January 2, 2012 - link
Thanks for pointing that out because not so long ago i saw a video on amd's web site where they were showing of a amd Llano notebook vs a intel sandy bridge core i7 notebook they started the same benchmark on both notebooks and the intel was quite fast but as they open more and more programs at the same time the intel starts to drop in performance where the amd is running stable. So my suggestion would be to run all benchmark on the bulldozer and i7 2600k again but this time open about 10 or 20 other programs a the same time then u will truly see the bulldozer shine. I am not a amd fanboy my current build a intel Pentium G860 and i am very dissapointed in myself i shouldve gone with the amd q640 it was around the same price when i bought it. My next build will be a Amd FX4100. HAmakaira - Thursday, December 8, 2011 - link
Well I very excitedly bought a 8150 based system for number crunching as the performance/$ looked very good. I could buy a "quiet" system for Aus $ 1130 with SSD and only 8Gb RAM.I had previously purchased a Intel i7 2600K, but could never get it to overclock and run 64 bit Java app (Napoleon Spike from DUG) 24/7, it fell over after 6 hrs or 12 or 23 or 47, it always fell over despite water cooling.
Now the bulk of my work is done by Xeons in the rack, with a couple of dual 5680's systems doing the heavy lifting (2 x 6 core + hyperthreading looks like 24 CPU's to OS). These are good stable systems with 96Gb RAM, but high overall system cost.
I wanted a few cheap and moveable fast CPU's. Boy did the Bulldozer fail to deliver
More is Better measure in Bytes inversion throughput/minute
BD 8150 115-123k in 8/8 threads i.e. flat out
i7 2600 237-268k in 8/8 threads i.e. flat out
Xeon dual 5680 333-356k in 12/24 threads i.e.half loaded
i7-870 166k in 8/8 threads i.e flat out
Xeon Dual E5520 190k 12/16 threads
Xeon Dual 5430 132k 8/8 threads
The Bulldozer is the slowest and the newest....very poor performance. Eclipsed by Intel at similiar price point. I might as well replace the MB and CPU and go with i73960 or 3930...
wepexpert117 - Thursday, December 8, 2011 - link
I dunno if anyone noticed, but if u study the architectures carefully, then what AMD calls as a 'module' is comparable to a 'core' of Intels. Intels Hyperthreading allows two logical thread executions per core. But AMD's TruCore theory, only allows one thread per core. The Intel i5-2500K has 4 physical cores and 8 logical threads. Compared to that the most powerful of the AMD, the FX-8170, contains 4 modules which can execute 8 threads, with 2 cores per module, each core executing 1 thread. On the other hand the i7-2600K contains 6 physical cores and 12 logical threads. Hence by no chance, can the FX-8150, can match the capability of the 2600K, as the latter as 2 more cores to add to the power. As for the results of the benchmarking, it also agrees with the fact that the FX-8150 is comparable albeit a little less powerful than the i5-2500K, because of the architecture difference between Intels core and AMD's Bulldozer.If AMD ever brings out (according to them) a 12 core FX processor (Prob. FX-12XXX), then it would be really interesting to see how that matches with the i7-2600K. Altough the shared L2 cache architecture, is what may be detrimental to the performance of these processors.Jondenmark - Saturday, December 24, 2011 - link
Something is wrong. If I look at a die shot of Llano then the core is about 1½ times the size of the 1 MB L2 cache. If I look at a Bulldozer module, it is about 1½ times the 2 MB L2 cache. To me this indicates, that a Buldozer module is about 100% larger than a phenom II core which is far from the 12% more core size, which AMD has previously indicated was the cost of adding another core to form a module. The 12% was expected to allow AMD to add nearly double the core count on a given process node to convince the server market and give plenty of die space for the GPU on the Llano APU. Where am I wrong and what is right?8 core cpu - Friday, January 6, 2012 - link
This <a herf="http://8corecpu.com/">8 Core Cpu</a> is high spreed CPU. It is best than other CPU8 core cpu - Friday, January 6, 2012 - link
This 8 Core Cpu is high spreed CPU. It is best than other CPU. For more info please ....http://8corecpu.com/
Raven0628 - Saturday, January 14, 2012 - link
I beleive amd realy missed it shoot badly, but it is still the right social choice caus what will happen if intel get x86 monopol and they are still resonably priced and whene you have to live with it in every day life will you realy notice the diferance in perfomance. Unless you realy to go for all the top of the line in every part of your system you will got for the top of intel i7.But i'v never did and alway ended up with reliable good perfomance amd sys for less than 800$ counting with the power supply i had to replace. this year. my point unless you want a death machine go for amd and you will feel better with your self ;).
PS. sry for the terible english.
Ernst0 - Sunday, February 5, 2012 - link
Hey guys.There is no doubt that whatever critiques have been posted are valid but I skimmed a few pages and saw no "Consumer" comments.
I have purchased an 8150 with a AMD3+ motherboard and will be putting the unit together.
In my days since the Z80 and 48k this represents the nicest cpu ever for me.
That it was affordable and that I will have 8 cores to task with my hobby programming such as trying to factor RSA-numbers or the ilk the AMD 8=core is a dream system for the price.
I picked up case, mother board power supply, 1.5 TB drive DVD, 1 gb video, 16 gb ram, 28 inch monitor, wall mount for monitor so I can have two 28's with one the long way for source code and perhaps something else.. Anyway $1200 is the cost.
Now this is my first bare-bones experience too so all in all it is exciting to get such a dream machine and I am happy to step forward and support AMD
I don't know what awaits when the memory arrives and I boot up but it feels like Starship already and I have vowed to learn OpenMP under GCC to advance into multi-core programming.
So perhaps there will be issues. perhaps this is not all that nor is it wat will come but from where I am at I am still on the AMD home team and my money is flowing in the economy.
I went from trs 80 to Amiga then to twin AMD single core chips on one Motherboard, Moved to the early quad cores dreaming of dual quad cores when a system with 8 cores of that day would have cost $4900 and now picked up a system that as a boy in 1973 I would have considered Alien-ufo technology for about what I paid for dual single core chips just a few years ago.
So BullDozer can't be all that bad. The price is good! I will see how she runs. I often peg cores at 100% for days when searching for RSA factors.. Looks like I get more bang for the same bucks this time and I am all for that.
Thank you AMD for such a wonderful cpu. I plan to make use and thanks to the motherboard I can watch out for heat issues much easier than ever,
Not to mention it looks like the sound system is way advanced over the last computer as well.
So from a consumer / hobby programmer point of view this is very cool indeed.
Ernst
mumbles - Sunday, February 12, 2012 - link
Thank you for being the first to actually contribute some real world response to this architecture. So many trolls on this thread that are intel fanboys.Also, if your using xen with this thing, I would be interested in seeing some feedback on how multiple guests(like more than 4) act when trying to fight for floating point processor time. Be interesting also to see if 4 floating point threads and 4 integer threads can all run at the same time with no waiting. That might be asking too much for now tho.