AMD's Steamroller Detailed: 3rd Generation Bulldozer Core
by Anand Lal Shimpi on August 28, 2012 4:39 PM EST- Posted in
- CPUs
- Bulldozer
- AMD
- Steamroller
Cache Improvements
The shared L1 instruction cache grew in size with Steamroller, although AMD isn’t telling us by how much. Bulldozer featured a 2-way 64KB L1 instruction cache, with each “core” using one of the ways. This approach gave Bulldozer less cache per core than previous designs, so the increase here makes a lot of sense. AMD claims the larger L1 can reduce i-cache misses by up to 30%. There’s no word on any possible impact to L1 d-cache sizes.
Although AMD doesn’t like to call it a cache, Steamroller now features a decoded micro-op queue. As x86 instructions are decoded into micro-ops, the address and decoded op are both stored in this queue. Should a fetch come in for an address that appears in the queue, Steamroller’s front end will power down the decode hardware and simply service the fetch request out of the micro-op queue. This is similar in nature to Sandy Bridge’s decoded uop cache, however it is likely smaller. AMD wasn’t willing to disclose how many micro-ops could fit in the queue, other than to say that it’s big enough to get a decent hit rate.
The L1 to L2 interface has also been improved. Some queues have grown and logic is improved.
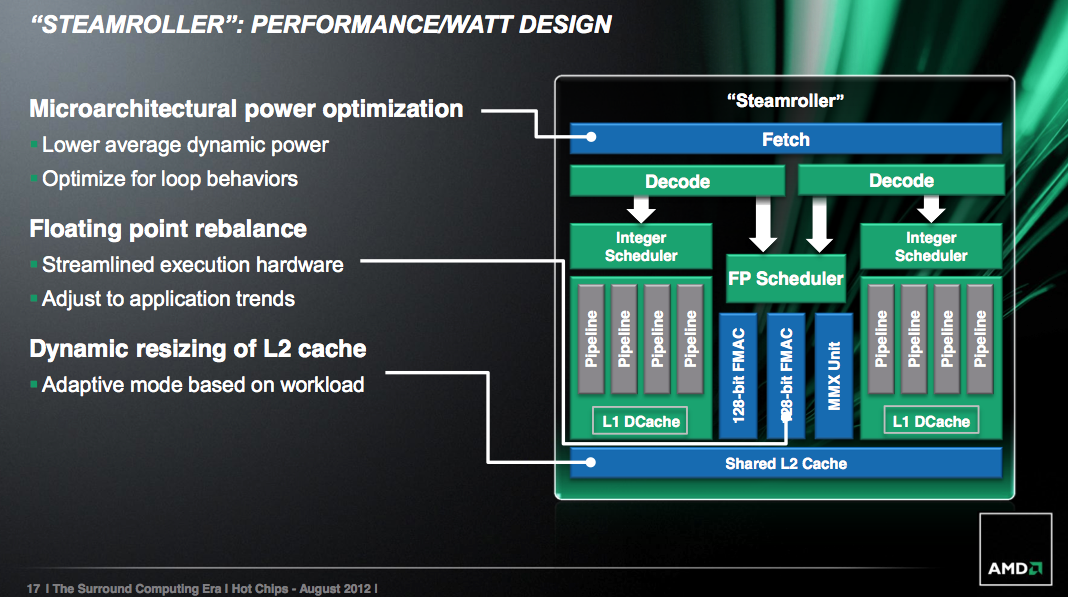
Finally on the caching front, Steamroller introduces a dynamically resizable L2 cache. Based on workload and hit rate in the cache, a Steamroller module can choose to resize its L2 cache (powering down the unused slices) in 1/4 intervals. AMD believes this is a huge power win for mobile client applications such as video decode (not so much for servers), where the CPU only has to wake up for short periods of time to run minor tasks that don’t have large L2 footprints. The L2 cache accounts for a large chunk of AMD’s core leakage, so shutting half or more of it down can definitely help with battery life. The resized cache is no faster (same access latency); it just consumes less power.
Steamroller brings no significant reduction in L2/L3 cache latencies. According to AMD, they’ve isolated the reason for the unusually high L3 latency in the Bulldozer architecture, however fixing it isn’t a top priority. Given that most consumers (read: notebooks) will only see L3-less processors (e.g. Llano, Trinity), and many server workloads are less sensitive to latency, AMD’s stance makes sense.
Looking Forward: High Density Libraries
This one falls into the reasons-we-bought-ATI column: future AMD CPU architectures will employ higher levels of design automation and new high density cell libraries, both heavily influenced by AMD’s GPU group. Automated place and route is already commonplace in AMD CPU designs, but AMD is going even further with this approach.
The methodology comes from AMD’s work in designing graphics cores, and we’ve already seen some of it used in AMD’s ‘cat cores (e.g. Bobcat). As an example, AMD demonstrated a 30% reduction in area and power consumption when these new automated procedures with high density libraries were applied to a 32nm Bulldozer FPU:

The power savings comes from not having to route clocks and signals as far, while the area savings are a result of the computer automated transistor placement/routing and higher density gate/logic libraries.
The tradeoff is peak frequency. These heavily automated designs won’t be able to clock as high as the older hand drawn designs. AMD believes the sacrifice is worth it however because in power constrained environments (e.g. a notebook) you won’t hit max frequency regardless, and you’ll instead see a 15 - 30% energy reduction per operation. AMD equates this with the power savings you’d get from a full process node improvement.
We won’t see these new libraries and automated designs in Steamroller, but rather its successor in 2014: Excavator.
Final Words
Steamroller seems like a good evolutionary improvement to AMD’s Bulldozer and Piledriver architectures. While Piledriver focused more on improving power efficiency, Steamroller should make a bigger impact on performance.
The architecture is still slated to debut in 2013 on GlobalFoundries' 28nm bulk process. The improvements look good on paper, but the real question remains whether or not Steamroller will be enough to go up against Haswell.








126 Comments
View All Comments
AssBall - Wednesday, August 29, 2012 - link
You can run a 3.0 card on a 2.0 lane just fine. Dunno what you are talking about. And you can't even saturare a 2.0 x16 with a top end card, so what's the big deal?CeriseCogburn - Wednesday, August 29, 2012 - link
The big deal is amd is such an assball.Kiijibari - Tuesday, August 28, 2012 - link
Hi,I dont see how this:
"Now each core has its own 4-wide instruction decoder,"
and the statement of "+25% max-width dispatches per thread"
fit together. Seems a bit strange to have +100% Decode power if there is only +25% dispatch improvement.
DanNeely - Wednesday, August 29, 2012 - link
Read the footnote on the slide. The amount of hardware went up by 100%; the 25% number is the actual average throughput gain AMD saw in their testing. IOW ~25% of the time Bulldozer/Piledriver's shared decode maxed out in cases where a wider decode could have done more instructions at the same time.Southernsharky - Tuesday, August 28, 2012 - link
Well its not a great processor, but it does sound like AMD is putting some thought into it.They really need to hyper-evolve this Bulldozer junk and get something that is competitive out.
I'm still rolling along with my Phenom II 6 core, and it ain't bad really, even in basic gaming like League of Legends. But I imagine I'd be better off going Intel on my next rig. I'll still take a look at Excavator when it comes out though. I plan to keep my current system at least that long. Then maybe I'll go one way or the other.
Angrybird - Tuesday, August 28, 2012 - link
at low end, AMD has been a very competitive solution for internet cafe's here in the Philippines for the past years but now (2012), 8 out of 10 internet cafe's switches to Intel (its a fact, try and make a survey).. sandy bridge pentiums and celerons kick AMD in the lowend where AMD used to shine. Athlon II is very old, Llano is still a good option but who wants a dead end road?Death666Angel - Wednesday, August 29, 2012 - link
If it's a fact, you should have the survey you base that fact on.iwod - Tuesday, August 28, 2012 - link
Just from reading the improvement it is obvious the design is for Server workload. And that is great because that is where the money are heading. Consumer market is shrinking with ARM Tablet / Smartphones, as well as their Fusion APU to handle those needs.But will that be enough? I will have to wait and see the benchmarks on servers software loads. 15% performance is surely not enough, If they could do 15% performance increase while giving a 15% less power usage it may be good enough for now.
elerick - Wednesday, August 29, 2012 - link
Well I am rooting for AMD but this release to me feels like they are pulling their punch. I will not pretend to understand all the tweaks and how it will address their previous design flaws.But there was no mention of memory controller enhancements, the previous buzz was that AMD was potentially going to introduce quad channel memory controller support much like their servers. Don't quote me but I know I've read it somewhere. I do not see any mention of anything other than they are focusing on latency which is fantastic for power efficiency and mobile platforms however they have no focus on any major improvements to the desktop cpu (referring to the L3 cache reference in the article)
Where is the desktop CPU love? I know myself and many people have desktop computers which are good enough for the here and now, but by 2013/2014 we would love a healthy upgrade from AMD but it looks like 15% year after year is all that is planned but to make matters worse those numbers are completely focused on mobile platforms.
meloz - Wednesday, August 29, 2012 - link
> The improvements look good on paper, but the real question remains whether or not Steamroller will be enough to go up against Haswell.Why even *pretend* that this is a two horse race anymore?
We _all_ know it will be no match to Haswell. Even with a generous 20% improvement on CPU side, the Steamroller will at best match IVB, let alone IVB-E or whatever the large socket version of IVB will be eventually called. Forget Haswell, which will add another 10-15% over IVB.
And all that is in pure performance per $ metric; Intel will absolutely kill whatever AMD has to offer in the performance / watt.
At best, we will get some good Steamroller based APUs, but those also have limited benefit to users like me since AMD's linux graphic support is virtually non-existant when compared to Intel (http://intellinuxgraphics.org/), and Intel is steadily improving its weak iGPU...