AMD's Steamroller Detailed: 3rd Generation Bulldozer Core
by Anand Lal Shimpi on August 28, 2012 4:39 PM EST- Posted in
- CPUs
- Bulldozer
- AMD
- Steamroller
Today at the annual Hot Chips conference, AMD’s new CTO Mark Papermaster unveiled the first details about the Steamroller x86 CPU core.
Steamroller is the third instantiation of AMD’s Bulldozer architecture, first conceived in the mid-2000s and finally brought to market in late 2011. Committed to this architecture for at least one more design after Steamroller, AMD has settled on roughly yearly updates to the architecture. For 2012 we have the introduction of Piledriver, the optimized Bulldozer derivative that formed the CPU foundation for AMD’s Trinity APU. By the end of the year we’ll also see a high-end desktop CPU without processor graphics based on Piledriver.
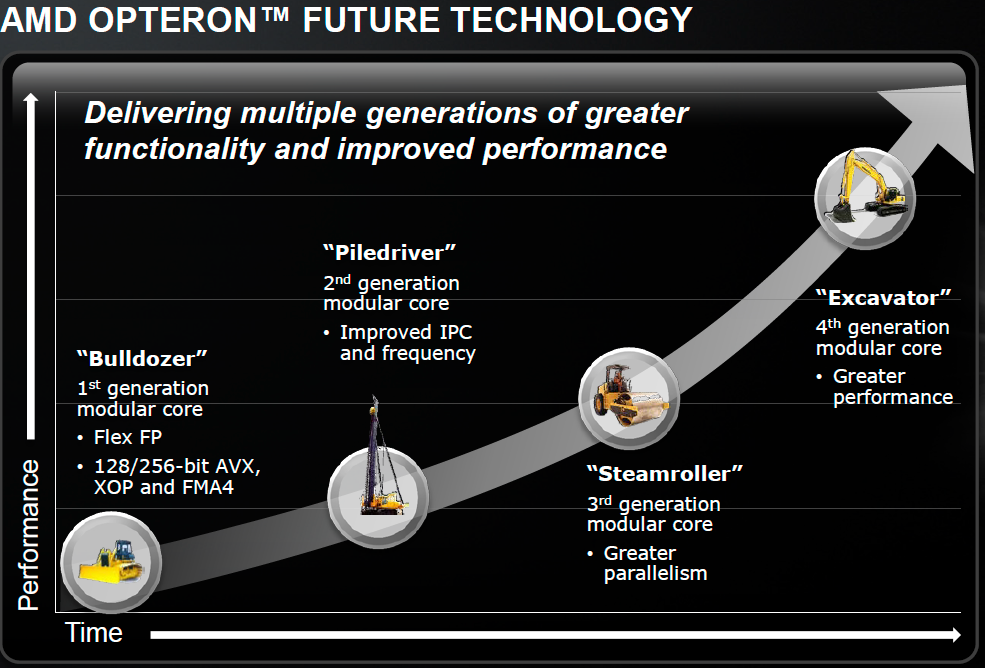
Piledriver saw a switch to hard edge flip flops, which allowed for a considerable decrease in power consumption at the expense of careful design and validation work. Performance didn’t change, but AMD saw a 10% - 20% reduction in active power. Piledriver also brought some scheduling efficiency improvements, but prefetching and branch prediction were the two other major design improvements in Piledriver.
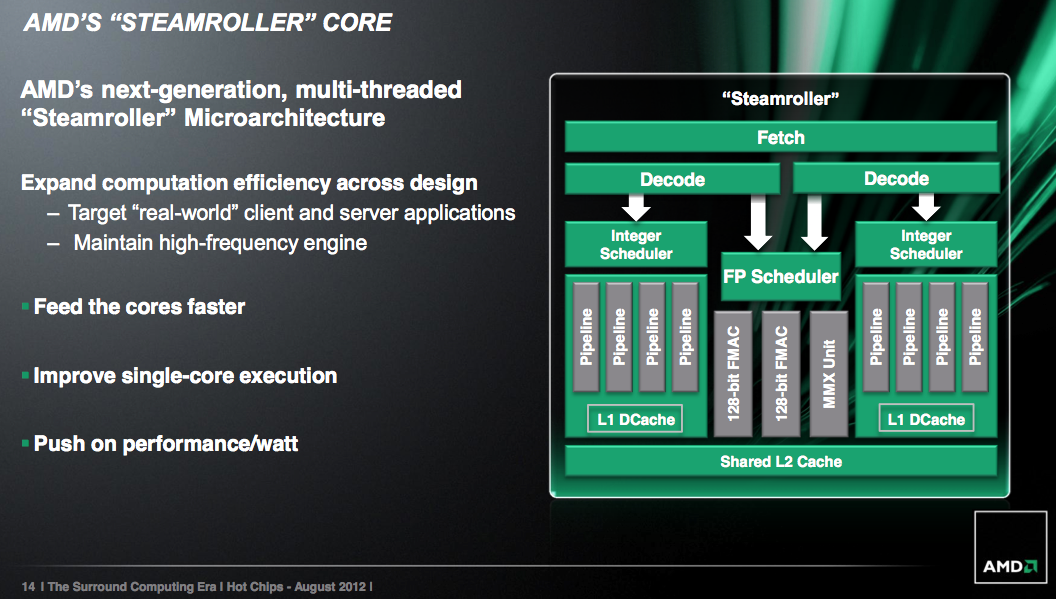
Steamroller is designed to keep the ball rolling. It takes fundamentals from the Bulldozer/Piledriver architectures and offers a healthy set of evolutionary improvements on top of them. In Intel speak Steamroller wouldn’t be a tick as it isn’t accompanied by a significant process change (28nm bulk is pretty close to 32nm SOI), but it’s not a tock as the architecture is mostly enhanced but largely unchanged. Steamroller fits somewhere in between those two extremes when it comes to changes.
Front End Improvements
One of the biggest issues with the front end of Bulldozer and Piledriver is the shared fetch and decode hardware. This table from our original Bulldozer review helps illustrate the problem:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
Steamroller addresses this by duplicating the decode hardware in each module. Now each core has its own 4-wide instruction decoder, and both decoders can operate in parallel rather than alternating every other cycle. Don’t expect a doubling of performance since it’s rare that a 4-issue front end sees anywhere near full utilization, but this is easily the single largest performance improvement from all of the changes in Steamroller.
The penalties are pretty obvious: area goes up as does power consumption. However the tradeoff is likely worth it, and both of these downsides can be offset in other areas of the design as you’ll soon see.

Steamroller inherits the perceptron branch predictor from Piledriver, but in an improved form for better performance (mostly in server workloads). The branch target buffer is also larger, which contributes to a reduction in mispredicted branches by up to 20%.
Execution Improvements
AMD streamlined the large, shared floating point unit in each Steamroller module. There’s no change in the execution capabilities of the FPU, but there’s a reduction in overall area. The MMX unit now shares some hardware with the 128-bit FMAC pipes. AMD wouldn’t offer too many specifics, just to say that the shared hardware only really applied for mutually exclusive MMX/FMA/FP operations and thus wouldn’t result in a performance penalty.
The reduction of pipeline resources is supposed to deliver the same throughput at lower power and area, basically a smarter implementation of the Bulldozer/Piledriver FPU.
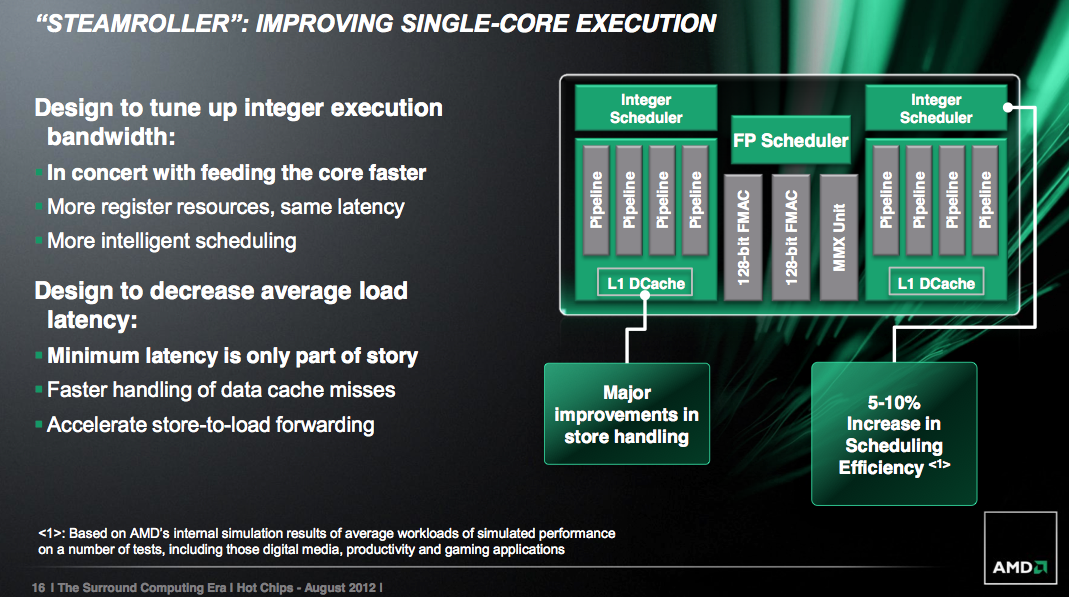
There’s no change to the integer execution units themselves, but there are other improvements that improve integer performance.
The integer and floating point register files are bigger in Steamroller, although AMD isn’t being specific about how much they’ve grown. Load operations (two operands) are also compressed so that they only take a single entry in the physical register file, which helps increase the effective size of each RF.
The scheduling windows also increased in size, which should enable greater utilization of existing execution resources.
Store to load forwarding sees an improvement. AMD is better at detecting interlocks, cancelling the load and getting data from the store in Steamroller than before.








126 Comments
View All Comments
rocketbuddha - Tuesday, August 28, 2012 - link
Thanks.. With STM licensing FDSOI 28nm to GF , which AMD can use for a path towards atleast improving Vishera series with a die-shrink it makes little sense for AMD to move to TSMC now. Easier would it be for AMD to chose from the multiple IBM bulk consortium members for fabbing rather than TSMC which is all by itself and go to for any 28nm manufacturing today.freezervv - Tuesday, August 28, 2012 - link
"Load operations (two operands) are also compressed so that they only take a single entry in the physical register file, which helps increase the effective SIDE of each RF."alpha754293 - Tuesday, August 28, 2012 - link
It still only has a single FPU unit (and no matter how you divde up the 128-bits); in the real-world, it probably means that it'll only use half of it at any given time.So, it's still gonna suck.
Don't forget that computers are really just really BIG, glorified calculators. And without the FPU; it won't be able to do much of what it's intended/designed to do in the first place.
cotak - Tuesday, August 28, 2012 - link
For FPU related work maybe. AMD's stated before their vision is to move FPU work off onto the GPU side of things. If their plans are still in place the FPU is just a place holder for the time being.I am not saying it's the right choice but it's what they have said they wanted to do.
At any rate a fast integer processing rate already goes a long way towards making a computer feel fast for most users. And for a lot of server tasks it would be good enough.
HPC-Top10 - Wednesday, August 29, 2012 - link
You are correct. With only a single FPU unit, it will only be in use half the time. We have 40,000+ AMD Interlagos cores, yet tell our users to run on only half of them to get better performance. We have 32 cores per node, yet if a user runs on all 32, their HPC codes run slower. By running on 16 cores, thus wasting the other 16 cores, their HPC codes run faster. This is not true for every single code, but it is true for many of them.Beenthere - Tuesday, August 28, 2012 - link
It really doesn't matter to most folks if Steamroller is as good or better than Haswell. The real question is does Steamroller continue to up performance and meet the needs of Mainstream consumers. That is where money is made, not in the 5% of the market that buys over-hyped, over-priced, top-of-the-line CPUs (or GPUs). If Steamroller continues AMD's 15% performance bumps it will be a sales hit just as Trinity is and Vishera will be.Most people don't care what brand of CPU/APU or GPU is in their PC. All they care is that the PC functions as desired and the price is affordable. I'm confident that AMD will continue to serve their needs quite well.
BTW, the fallacy that moving from one process to a lower sized process is still a big deal, i.e. 32nm to 22nm, it untrue. It has power consumption advantages for ULV but for everything else, other design parameters are far more important than the process node these days, as Intel learned with tri-gate Ivy Bridge which has leakage and OC'ing issues.
In regards to benches, people might as well get use to the Intel bias and make their purchasing decisions based on actual system performance because Intel is good at buying favor on benches.
jabber - Tuesday, August 28, 2012 - link
Yep, always amazed how many here still haven't woken up to the fact that the CPU world doesn't revolve around them.Also that 90% of the worlds computer users switched off caring the minute dual core CPUs came out years ago.
Lot of denial in the enthusiast world, hence probably why AMD quite bothering with them.
"Is it cheap, will it do Ebay and can my daughter play the Sims on it?"
Thats all the criteria needed in most cases.
BenchPress - Tuesday, August 28, 2012 - link
You sound like the people who said 1 GHz is enough for everybody...The reality is that the mainstream market follows in the footsteps of the enthusiast market. So sooner or later everybody is affected by the directions AMD and Intel are taking today. And these are quite exciting times. AMD is betting the farm on heterogeneous computing with HSA, while Intel is revolutionizing homogeneous high throughput computing with AVX2 and TSX. It's really the equivalent of the 'RISC versus CISC' debate of this decade. Perhaps 99.9% of the world's population doesn't care about these things at all, and you're free to join them, but it's what brought you eBay and The Sims at an affordable price!
Computers have evolved from mere tools, to becoming part of our lives. In the future we'll probably interact even closer with them, for instance through speech and natural gestures. This requires lots of additional innovation.
FunBunny2 - Tuesday, August 28, 2012 - link
Nope, but almost. The circle dance had been Intel/MicroSoft: Intel needed windoze bloat to justify the performance ramp, and MicroSoft needed Intel to ramp to support dreadful windoze.Multi-processor/core and parallelism is going to be some hurdle for Amdahl constrained single threaded apps. Which is most of them, in the consumer PC world.
Computers have evolved from being computers to being entertainment appliances. That Jobs for that.
Spunjji - Thursday, August 30, 2012 - link
LolJobsNo.