AMD's Steamroller Detailed: 3rd Generation Bulldozer Core
by Anand Lal Shimpi on August 28, 2012 4:39 PM EST- Posted in
- CPUs
- Bulldozer
- AMD
- Steamroller
Cache Improvements
The shared L1 instruction cache grew in size with Steamroller, although AMD isn’t telling us by how much. Bulldozer featured a 2-way 64KB L1 instruction cache, with each “core” using one of the ways. This approach gave Bulldozer less cache per core than previous designs, so the increase here makes a lot of sense. AMD claims the larger L1 can reduce i-cache misses by up to 30%. There’s no word on any possible impact to L1 d-cache sizes.
Although AMD doesn’t like to call it a cache, Steamroller now features a decoded micro-op queue. As x86 instructions are decoded into micro-ops, the address and decoded op are both stored in this queue. Should a fetch come in for an address that appears in the queue, Steamroller’s front end will power down the decode hardware and simply service the fetch request out of the micro-op queue. This is similar in nature to Sandy Bridge’s decoded uop cache, however it is likely smaller. AMD wasn’t willing to disclose how many micro-ops could fit in the queue, other than to say that it’s big enough to get a decent hit rate.
The L1 to L2 interface has also been improved. Some queues have grown and logic is improved.
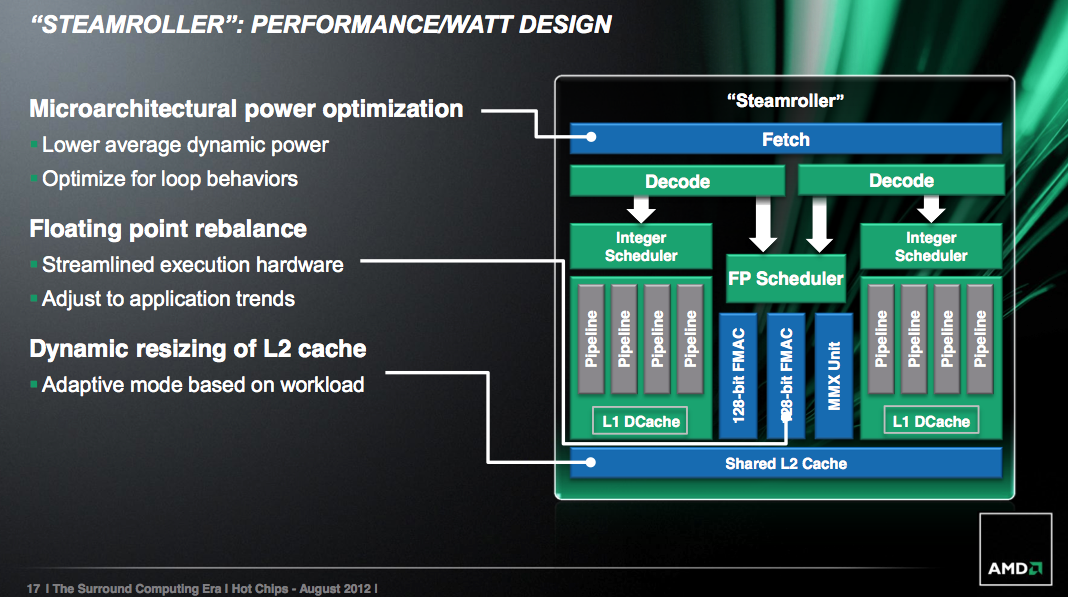
Finally on the caching front, Steamroller introduces a dynamically resizable L2 cache. Based on workload and hit rate in the cache, a Steamroller module can choose to resize its L2 cache (powering down the unused slices) in 1/4 intervals. AMD believes this is a huge power win for mobile client applications such as video decode (not so much for servers), where the CPU only has to wake up for short periods of time to run minor tasks that don’t have large L2 footprints. The L2 cache accounts for a large chunk of AMD’s core leakage, so shutting half or more of it down can definitely help with battery life. The resized cache is no faster (same access latency); it just consumes less power.
Steamroller brings no significant reduction in L2/L3 cache latencies. According to AMD, they’ve isolated the reason for the unusually high L3 latency in the Bulldozer architecture, however fixing it isn’t a top priority. Given that most consumers (read: notebooks) will only see L3-less processors (e.g. Llano, Trinity), and many server workloads are less sensitive to latency, AMD’s stance makes sense.
Looking Forward: High Density Libraries
This one falls into the reasons-we-bought-ATI column: future AMD CPU architectures will employ higher levels of design automation and new high density cell libraries, both heavily influenced by AMD’s GPU group. Automated place and route is already commonplace in AMD CPU designs, but AMD is going even further with this approach.
The methodology comes from AMD’s work in designing graphics cores, and we’ve already seen some of it used in AMD’s ‘cat cores (e.g. Bobcat). As an example, AMD demonstrated a 30% reduction in area and power consumption when these new automated procedures with high density libraries were applied to a 32nm Bulldozer FPU:

The power savings comes from not having to route clocks and signals as far, while the area savings are a result of the computer automated transistor placement/routing and higher density gate/logic libraries.
The tradeoff is peak frequency. These heavily automated designs won’t be able to clock as high as the older hand drawn designs. AMD believes the sacrifice is worth it however because in power constrained environments (e.g. a notebook) you won’t hit max frequency regardless, and you’ll instead see a 15 - 30% energy reduction per operation. AMD equates this with the power savings you’d get from a full process node improvement.
We won’t see these new libraries and automated designs in Steamroller, but rather its successor in 2014: Excavator.
Final Words
Steamroller seems like a good evolutionary improvement to AMD’s Bulldozer and Piledriver architectures. While Piledriver focused more on improving power efficiency, Steamroller should make a bigger impact on performance.
The architecture is still slated to debut in 2013 on GlobalFoundries' 28nm bulk process. The improvements look good on paper, but the real question remains whether or not Steamroller will be enough to go up against Haswell.








126 Comments
View All Comments
rocketbuddha - Tuesday, August 28, 2012 - link
Thanks.. With STM licensing FDSOI 28nm to GF , which AMD can use for a path towards atleast improving Vishera series with a die-shrink it makes little sense for AMD to move to TSMC now. Easier would it be for AMD to chose from the multiple IBM bulk consortium members for fabbing rather than TSMC which is all by itself and go to for any 28nm manufacturing today.freezervv - Tuesday, August 28, 2012 - link
"Load operations (two operands) are also compressed so that they only take a single entry in the physical register file, which helps increase the effective SIDE of each RF."alpha754293 - Tuesday, August 28, 2012 - link
It still only has a single FPU unit (and no matter how you divde up the 128-bits); in the real-world, it probably means that it'll only use half of it at any given time.So, it's still gonna suck.
Don't forget that computers are really just really BIG, glorified calculators. And without the FPU; it won't be able to do much of what it's intended/designed to do in the first place.
cotak - Tuesday, August 28, 2012 - link
For FPU related work maybe. AMD's stated before their vision is to move FPU work off onto the GPU side of things. If their plans are still in place the FPU is just a place holder for the time being.I am not saying it's the right choice but it's what they have said they wanted to do.
At any rate a fast integer processing rate already goes a long way towards making a computer feel fast for most users. And for a lot of server tasks it would be good enough.
HPC-Top10 - Wednesday, August 29, 2012 - link
You are correct. With only a single FPU unit, it will only be in use half the time. We have 40,000+ AMD Interlagos cores, yet tell our users to run on only half of them to get better performance. We have 32 cores per node, yet if a user runs on all 32, their HPC codes run slower. By running on 16 cores, thus wasting the other 16 cores, their HPC codes run faster. This is not true for every single code, but it is true for many of them.Beenthere - Tuesday, August 28, 2012 - link
It really doesn't matter to most folks if Steamroller is as good or better than Haswell. The real question is does Steamroller continue to up performance and meet the needs of Mainstream consumers. That is where money is made, not in the 5% of the market that buys over-hyped, over-priced, top-of-the-line CPUs (or GPUs). If Steamroller continues AMD's 15% performance bumps it will be a sales hit just as Trinity is and Vishera will be.Most people don't care what brand of CPU/APU or GPU is in their PC. All they care is that the PC functions as desired and the price is affordable. I'm confident that AMD will continue to serve their needs quite well.
BTW, the fallacy that moving from one process to a lower sized process is still a big deal, i.e. 32nm to 22nm, it untrue. It has power consumption advantages for ULV but for everything else, other design parameters are far more important than the process node these days, as Intel learned with tri-gate Ivy Bridge which has leakage and OC'ing issues.
In regards to benches, people might as well get use to the Intel bias and make their purchasing decisions based on actual system performance because Intel is good at buying favor on benches.
jabber - Tuesday, August 28, 2012 - link
Yep, always amazed how many here still haven't woken up to the fact that the CPU world doesn't revolve around them.Also that 90% of the worlds computer users switched off caring the minute dual core CPUs came out years ago.
Lot of denial in the enthusiast world, hence probably why AMD quite bothering with them.
"Is it cheap, will it do Ebay and can my daughter play the Sims on it?"
Thats all the criteria needed in most cases.
BenchPress - Tuesday, August 28, 2012 - link
You sound like the people who said 1 GHz is enough for everybody...The reality is that the mainstream market follows in the footsteps of the enthusiast market. So sooner or later everybody is affected by the directions AMD and Intel are taking today. And these are quite exciting times. AMD is betting the farm on heterogeneous computing with HSA, while Intel is revolutionizing homogeneous high throughput computing with AVX2 and TSX. It's really the equivalent of the 'RISC versus CISC' debate of this decade. Perhaps 99.9% of the world's population doesn't care about these things at all, and you're free to join them, but it's what brought you eBay and The Sims at an affordable price!
Computers have evolved from mere tools, to becoming part of our lives. In the future we'll probably interact even closer with them, for instance through speech and natural gestures. This requires lots of additional innovation.
FunBunny2 - Tuesday, August 28, 2012 - link
Nope, but almost. The circle dance had been Intel/MicroSoft: Intel needed windoze bloat to justify the performance ramp, and MicroSoft needed Intel to ramp to support dreadful windoze.Multi-processor/core and parallelism is going to be some hurdle for Amdahl constrained single threaded apps. Which is most of them, in the consumer PC world.
Computers have evolved from being computers to being entertainment appliances. That Jobs for that.
Spunjji - Thursday, August 30, 2012 - link
LolJobsNo.