AMD's Steamroller Detailed: 3rd Generation Bulldozer Core
by Anand Lal Shimpi on August 28, 2012 4:39 PM EST- Posted in
- CPUs
- Bulldozer
- AMD
- Steamroller
Today at the annual Hot Chips conference, AMD’s new CTO Mark Papermaster unveiled the first details about the Steamroller x86 CPU core.
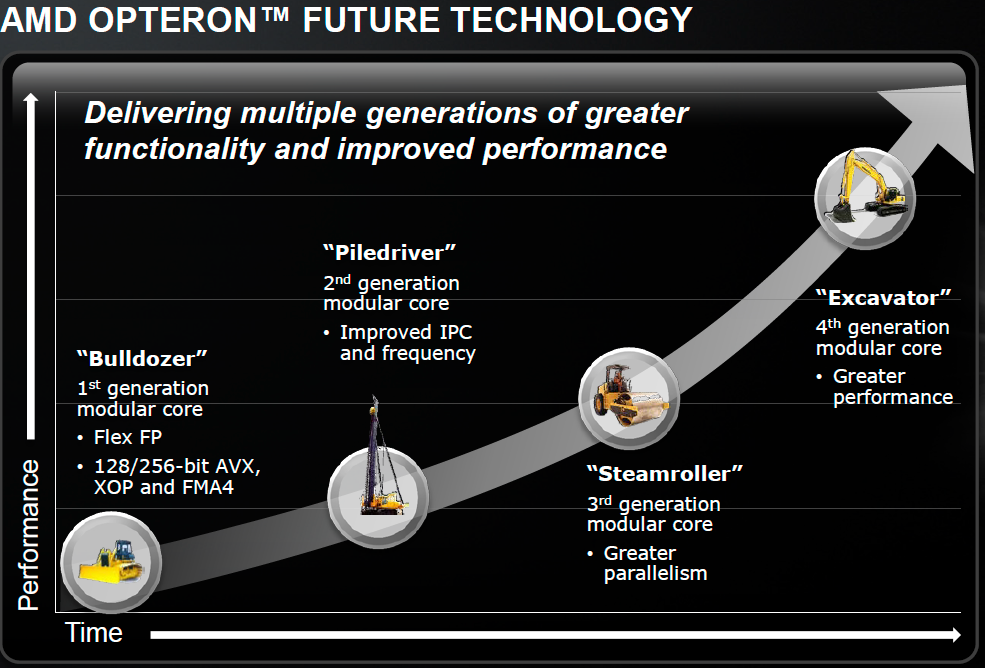
Steamroller is the third instantiation of AMD’s Bulldozer architecture, first conceived in the mid-2000s and finally brought to market in late 2011. Committed to this architecture for at least one more design after Steamroller, AMD has settled on roughly yearly updates to the architecture. For 2012 we have the introduction of Piledriver, the optimized Bulldozer derivative that formed the CPU foundation for AMD’s Trinity APU. By the end of the year we’ll also see a high-end desktop CPU without processor graphics based on Piledriver.
Piledriver saw a switch to hard edge flip flops, which allowed for a considerable decrease in power consumption at the expense of careful design and validation work. Performance didn’t change, but AMD saw a 10% - 20% reduction in active power. Piledriver also brought some scheduling efficiency improvements, but prefetching and branch prediction were the two other major design improvements in Piledriver.
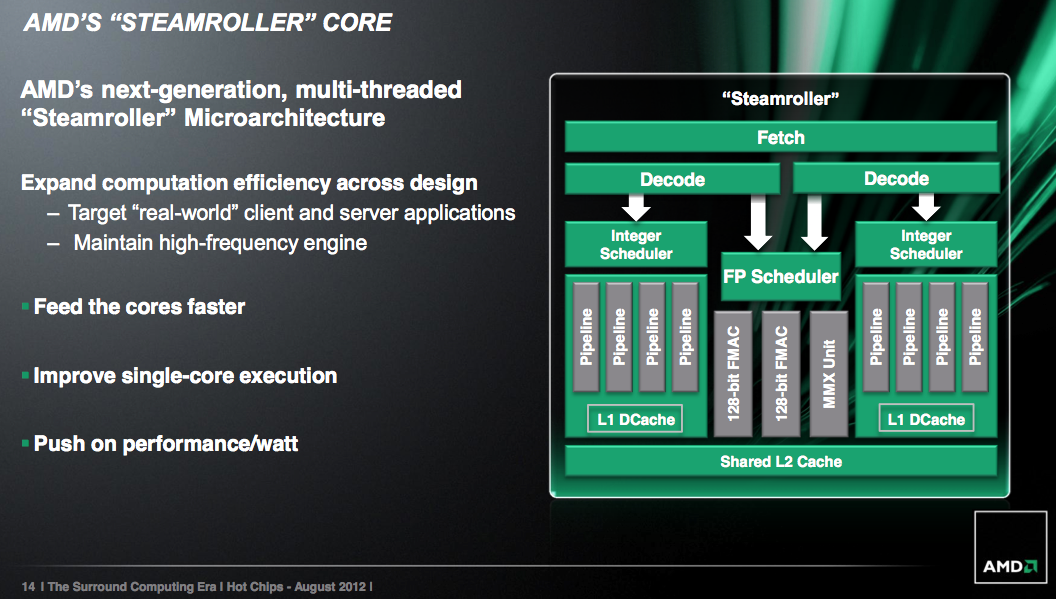
Steamroller is designed to keep the ball rolling. It takes fundamentals from the Bulldozer/Piledriver architectures and offers a healthy set of evolutionary improvements on top of them. In Intel speak Steamroller wouldn’t be a tick as it isn’t accompanied by a significant process change (28nm bulk is pretty close to 32nm SOI), but it’s not a tock as the architecture is mostly enhanced but largely unchanged. Steamroller fits somewhere in between those two extremes when it comes to changes.
Front End Improvements
One of the biggest issues with the front end of Bulldozer and Piledriver is the shared fetch and decode hardware. This table from our original Bulldozer review helps illustrate the problem:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
Steamroller addresses this by duplicating the decode hardware in each module. Now each core has its own 4-wide instruction decoder, and both decoders can operate in parallel rather than alternating every other cycle. Don’t expect a doubling of performance since it’s rare that a 4-issue front end sees anywhere near full utilization, but this is easily the single largest performance improvement from all of the changes in Steamroller.
The penalties are pretty obvious: area goes up as does power consumption. However the tradeoff is likely worth it, and both of these downsides can be offset in other areas of the design as you’ll soon see.

Steamroller inherits the perceptron branch predictor from Piledriver, but in an improved form for better performance (mostly in server workloads). The branch target buffer is also larger, which contributes to a reduction in mispredicted branches by up to 20%.
Execution Improvements
AMD streamlined the large, shared floating point unit in each Steamroller module. There’s no change in the execution capabilities of the FPU, but there’s a reduction in overall area. The MMX unit now shares some hardware with the 128-bit FMAC pipes. AMD wouldn’t offer too many specifics, just to say that the shared hardware only really applied for mutually exclusive MMX/FMA/FP operations and thus wouldn’t result in a performance penalty.
The reduction of pipeline resources is supposed to deliver the same throughput at lower power and area, basically a smarter implementation of the Bulldozer/Piledriver FPU.
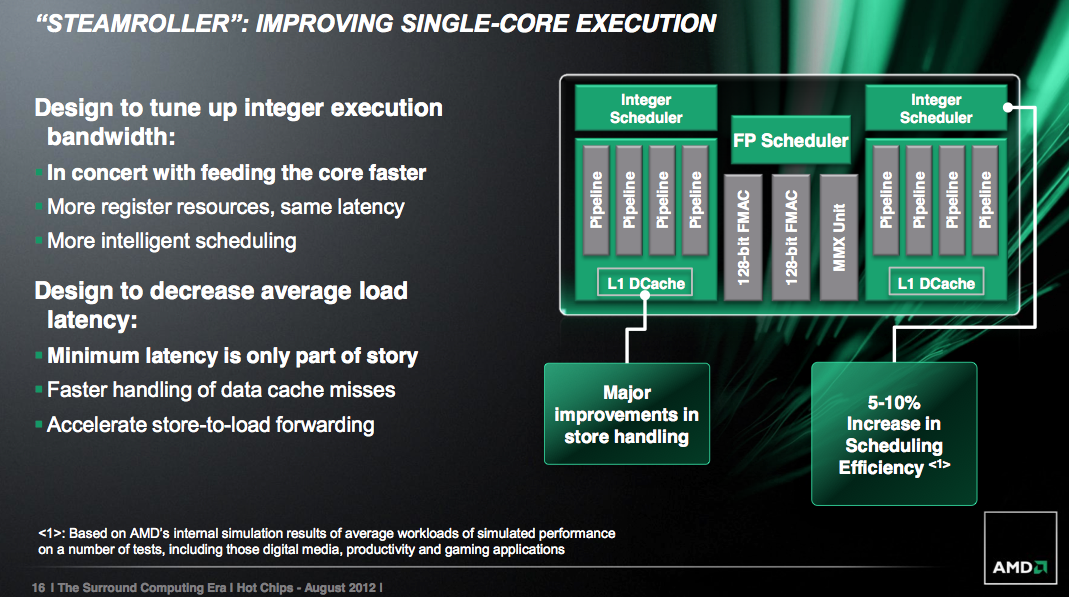
There’s no change to the integer execution units themselves, but there are other improvements that improve integer performance.
The integer and floating point register files are bigger in Steamroller, although AMD isn’t being specific about how much they’ve grown. Load operations (two operands) are also compressed so that they only take a single entry in the physical register file, which helps increase the effective size of each RF.
The scheduling windows also increased in size, which should enable greater utilization of existing execution resources.
Store to load forwarding sees an improvement. AMD is better at detecting interlocks, cancelling the load and getting data from the store in Steamroller than before.








126 Comments
View All Comments
jabber - Tuesday, August 28, 2012 - link
You keep believing that.The computing world does not revolve around mainly males aged between 14 to 25 playing Crysis.
Sorry to burst your bubble.
swaaye - Tuesday, August 28, 2012 - link
I think you forgot to read what you replied to.jabber - Wednesday, August 29, 2012 - link
It was a reply to Benchpress.About time a modern forum got some modern comments software.
MySchizoBuddy - Wednesday, August 29, 2012 - link
so far all these cries of a modern comment system has fallen on deaf ears.rocketbuddha - Tuesday, August 28, 2012 - link
I look at it slightly different. AMD is totally dependent right now on its OEM partners to push its processors into products that the consumers/market wants.Let us take Trinity for example. A excellent mobile APU and improvement over Llano in every single way. With AMD giving OEMs all the freedom to differentiate compared to the strict Ultabook guidelines that Intel forces, you should see a huge number of Ultra Thins (UT)
But what the OEMs are doing is equipping Trinity based NB/UT with substandard hardware. Worse they are pricing them so friggin close to low-end ultrabooks or UB like a little thicker notebooks with a better performance to hit AMD at all ends.
So now we have Brazos 2 systems fighting the simple Ivy pentiums which is not its intended competition and Trinity systems against Ivy systems sometimes with a discrete basic NVIDIA chip which can come close/exceed Trinity's graphics performance with a more powerful and efficient CPU.
So AMD who can just compete in Price/price to performance market right now have
a) Intel based systems very close in price in consumer market.
b) High-end gaming is now solely Intel
c) Stable (repeatedly rewarding) business market firm on the Intel camp.
d) Intel firmly owning the low-power market (expensive) due to technology advantage.
That is the reason AMD is missing revenues while Intel is growing albeit at a slower pace.
Conficio - Wednesday, August 29, 2012 - link
You are right and you are wrong.Totally agree that there are many computer uses where CPU speed and architecture does nto matter that much.
Unfortunately, the laptop OEMs have nto yet caught on to this. They still produce only crappy systems with crappy screens and crappy keyboards/mousepads (and in extension flexing cases). Or they go ultra light/thin and add unnecessary GPU and top of the line quad core CPUs
I think AMD needs to play its cards for affordable systems not just for cheap systems, but for an affordable middle ground, where the UX is quality and the chips are just good enough for the non gamer. AMD could do a lot with a good branding. Where is the AMD equivalent of UltraBooks with standards for solid keyboards, high res/high quality (IPS) screens, etc. At the end a CPU with a decent GPU (good enough for photo/video viewing and the OS animation gimmicks) shines much more in a solid combination. Call them EverydayBooks or A-Class laptops (as in AMD class)
CeriseCogburn - Wednesday, August 29, 2012 - link
Whom is going to build these amd wonders I ask.AMD couldn't get their damned fan design correct on the 69xx series and had to SHAVE PLASTIC CORNERS on the 6 pin connector.
I shudder to think AMD would have a hand in the design... they can't do basic measuring correct - and go to production with that kind of fault.
I suspect AMD internally is a bunch of scared losers who dare not speak out about problems lest they "get canned for the sake of the bottom line".
That grows into a real problem very quickly - different parts of the company not communicating with other portions - STOVEPIPED management with workers, engineers, groups, blocks, all living in fear...
SOMEONE needs to straighten it out - a modern government, secret agency, AND corporation cannot function properly if secrecy due to fear or stovepiping or "security" and/or protecting one's domain is the REASON for the silence and lack of communication...
In that environment people "give up" pretty quickly and "work with what they've got" which is less than they need to get it done correctly.
It's like AMD drivers - " I didn't know anything was wrong " says Catalyst Maker.... that kind of level of total and utter lack of communication.
Galidou - Sunday, September 2, 2012 - link
You speak like everyhting is so simple working building video cards and processors. It's so easy that everyone at home should build their own freaking parts, it's so easy... But still you ahve so much knowledge about management but you spend your timje spreading hate on forums about AMD AMD AMD....''I suspect AMD internally is a bunch of scared losers''
You jsut suspect too much things, go back to your design of the processor and video card that will dominate them all, it seems so easy after all.
CeriseCogburn - Friday, October 12, 2012 - link
Oh must have really severed that nerve as the reality cut through to the bone.You're fired !
(so another amd employee left - of course the emp was told it's layoffs again, but we all know crap under performance leads to it, and is effectively a firing no matter the name, or the nature, as in the boss saying "turn in your resignation")
Aren't you touchy feely types all about minimizing the hostile work environment ...
You ever been onboard a sinking ship miss touchy ?
ifrit39 - Tuesday, August 28, 2012 - link
While I agree with your comment about 'good enough' performance for mainstream users, I don't agree with the idea that process node shrinks are not important.Most of the consumer market uses their pcs simply for we browsing, email, and video. There has been an enormous shift from desktop to notebook and now to tablet and other mobile and light devices. This shift is enabled by process node shrinks that reduce power consumption and heat to reasonable levels and allow greater performance in smaller form factors. I think core 2 duo was 'good enough' to meet basic needs without feeling sluggish. But what user could complain about an extra hour of battery life?
If you read AT regularly, you'll see the impact that node shrinks have on battery life, power consumption, and heat/noise. Ivy bridge is no different and neither is any