Micron M500DC (480GB & 800GB) Review
by Kristian Vättö on April 22, 2014 2:35 PM ESTRandom & Sequential Performance
We are currently in the process of updating our enterprise SSD test suite and the new random and sequential performance tests are the first fruits of that. In the past our tests were set to a certain queue depth (mostly 32 in the enterprise tests), which didn't give the full picture of performance. As enterprise workloads are almost always unique, the queue depths vary greatly and the proper way to test performance is across all the possible queue depths. In our new tests we are now testing queue depth scaling from one to all the way to 128. While it's unlikely for enterprise workloads to have small queue depths, testing them gives us an important look into the architecture of the drive. Similarly, it's rare for even the more demanding enterprise workloads to exceed queue depth of 64 but we are still including the 128 in case it matters to some of you.
Since we are testing an enterprise class drive, we cannot look at the performance in a secure erased state as that would be unrealistic. Enterprise workloads tend to stress the drive 24/7 and thus we need to simulate the worst case performance by preconditioning the drive into steady-state before running the actual tests. To do this, we first fill the drive with sequential 128KB data and proceed with 4KB random writes at a queue depth of 32. The length of the torture depends on the drive and its characteristics but in the case of the M500DC, I ran the 4KB random write workload for two hours. As the performance consistency graphs on the previous page show, two hours is enough for the M500DC to enter steady-state and ensure consistent results.
After the preconditioning, we tested the performance across all queue depths at full LBA with Iometer. The test was ran for three minutes at each queue depth and the next test was started right after the previous one to make sure the drive was given no time to rest. The preconditioning process was repeated before every test (excluding read tests, which were run right after write tests) to guarantee that the drive was always in steady-state when tested.
4KB Random Performance
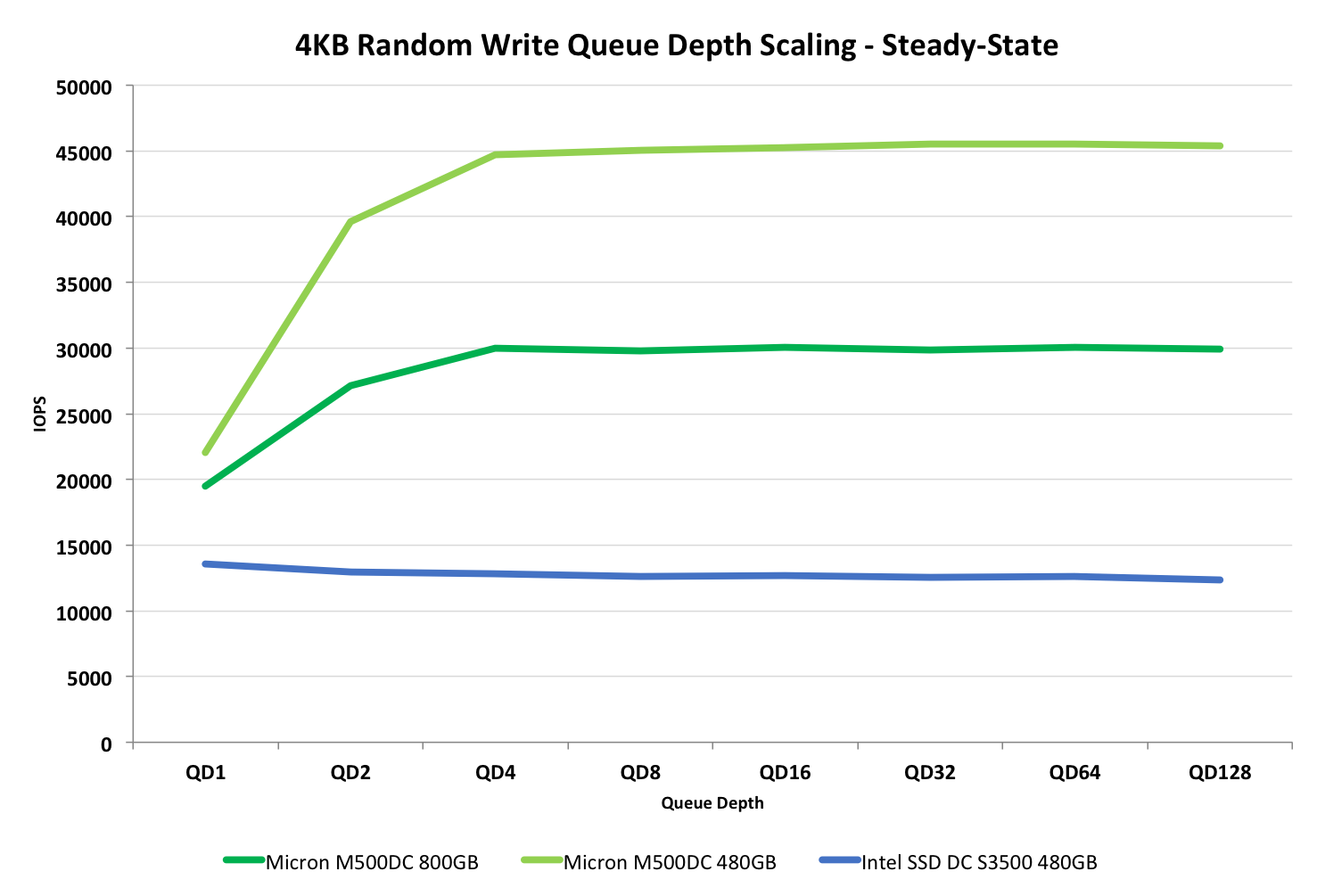
The random write scaling graph shows pretty much the same as our consistency tests. After the queue depth of four the performance reaches its limit and no longer scales. Interestingly, the DC S3500 doesn't scale at all, although it's performance is low to begin with when compared with the M500DC. (This is due to the difference in over-provisioning -- the S3500 only has 12% whereas the M500DC has 27/42%.)
Random read performance, on the other hand, behaves a bit differently. As steady-state doesn't really affect read performance, the performance scales all the way to 90K IOPS. The M500DC does well here and is able to beat the S3700 quite noticeably for typical enterprise workloads. The S3500 does have a small advantage at smaller queue depths but at QD16 and after, which are what matter for enterprise customers, the M500DC takes the lead.
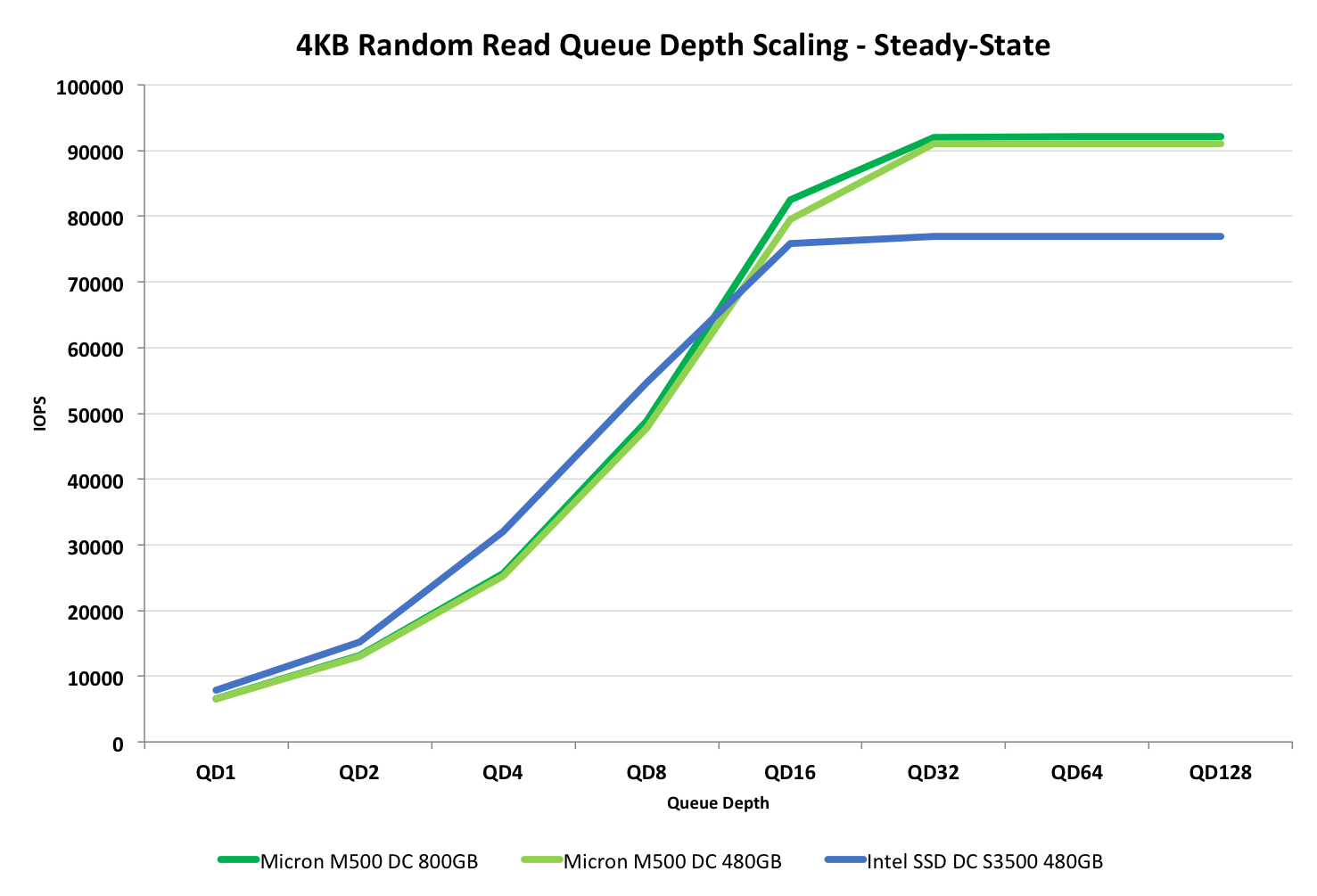
4KB Random 70% Read - 30% Write Performance
Typically no workload is 100% read or write, so to give a perspective of a mixed workload we are now including a 4KB random test with 70% read and 30% write commands. The LBA space is still 100% and the IOs are fully random, something which is also common for enterprise workloads.
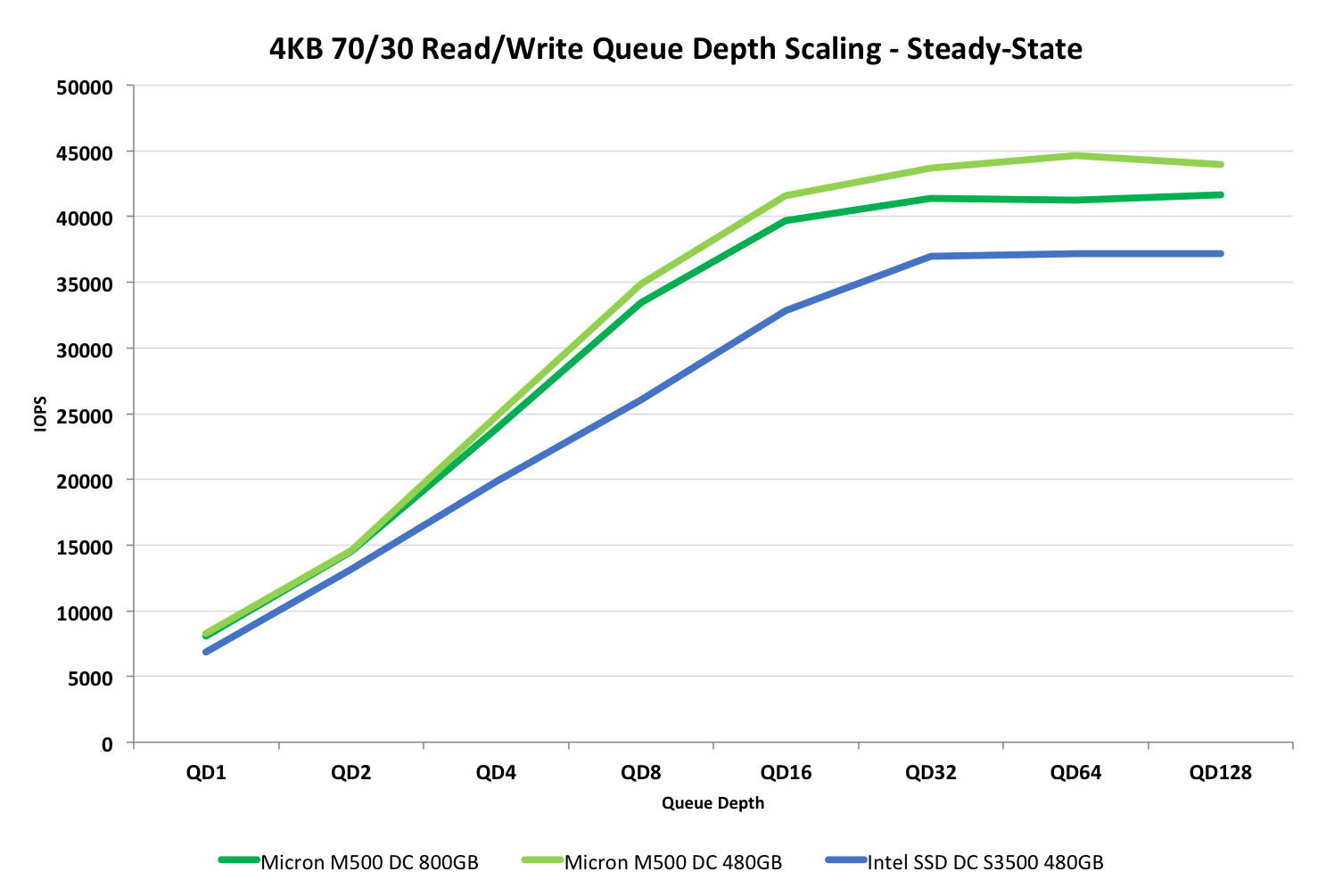
Once again the M500DC beats the DC S3500, which is mostly due to its superior random write performance. This is also the only workload where scaling happens up to queue depth of 32.
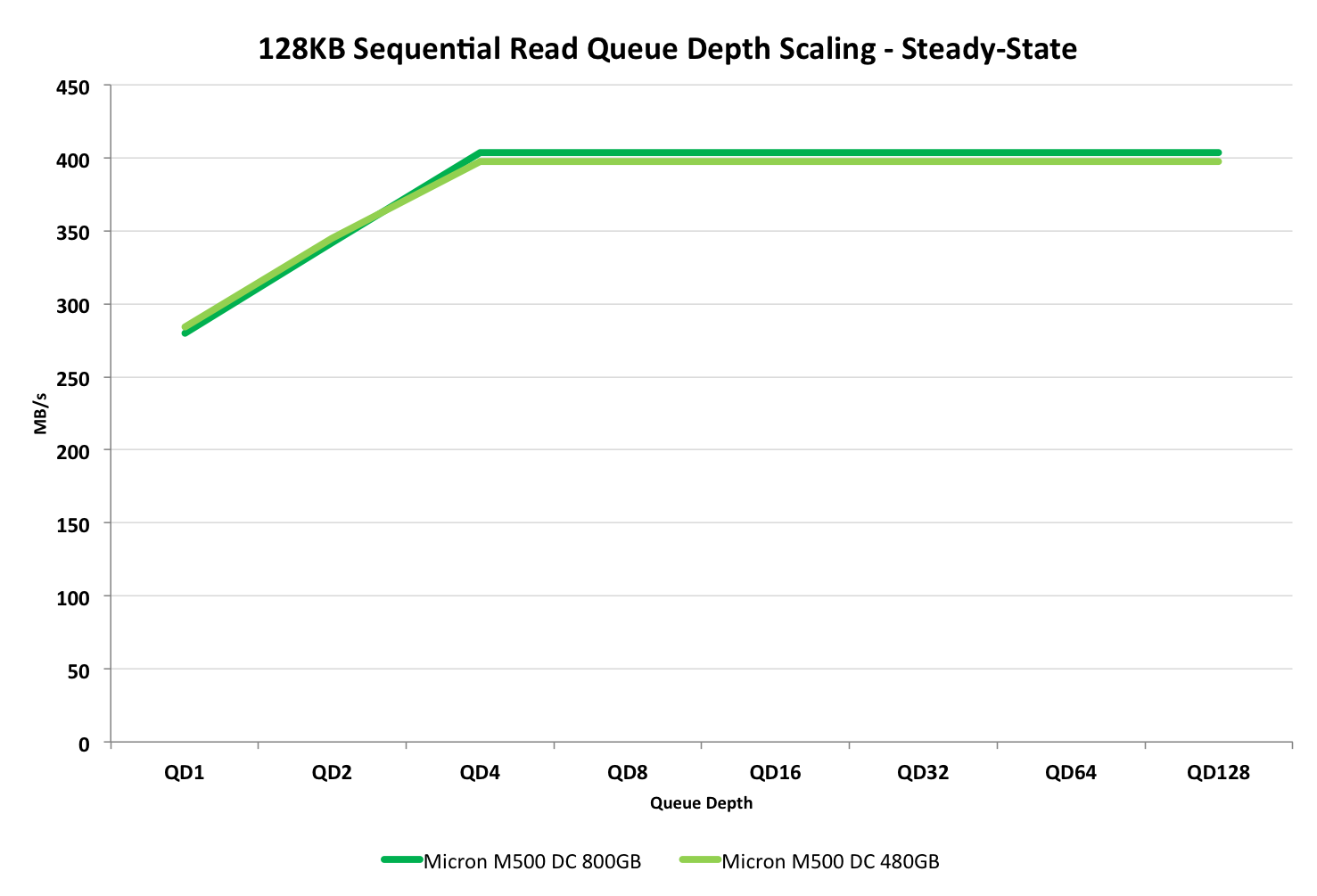
128KB Sequential Performance
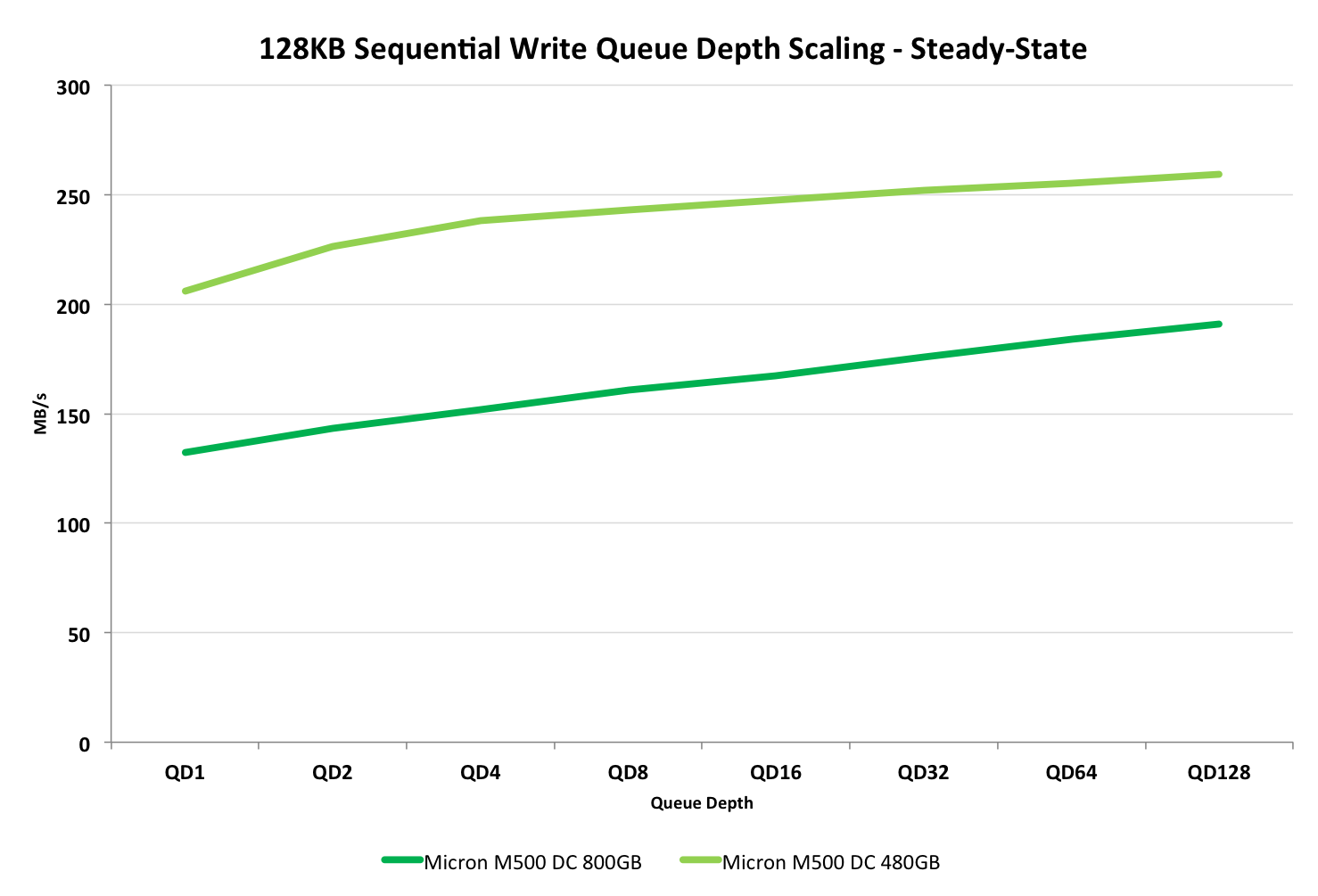
Due to lack of time, I unfortunately don't have results for the sequential performance of the DC S3500. However, the tests still provide a look into the M500DC even though the graphs lack a comparison point.
The 480GB M500DC is again significantly faster than the 800GB model thanks to the added over-provisioning. Bear in mind that these are steady-state figures, which is why the performance may seem a bit slow compared to what we usually see in benchmarks.
In terms of sequential read performance, on the other hand, the drives appear equal.








37 Comments
View All Comments
abufrejoval - Monday, April 28, 2014 - link
I'm seen an opportunity here to clarify something that I've always wondered about:How exactly does this long time retention work for FLASH?
In the old days, when you had an SSD, you weren't very likely having it lie around, after you paid an arm and a leg for it.
These days, however, storing your most valuable data on an SSD almost seems logical, because one of my nightmares is dropping that very last backup magnetic drive, just when I'm trying to insert it after a complete loss of my primary active copy: SSD just seems so much more reliable!
And then there comes this retention figure...
So what happens when I re-insert an SSD, that has been lying around say for 9 months with those most valuable baby pics of your grown up children?
Does just powering it up mean all those flash cells with logical 1's in them will magically draw in charge like some sort of electron sponge?
Or will the drive have to go through a complete read-check/overwrite cycle depending on how near blocks have come to the electron depletion limit?
How would it know the time delta? How would I know it's finished the refresh and it's safe to put it away for another 9 months?
I have some older FusionIO 320GB MLC drives in the cupboard, that haven't been powered up for more than a year: Can I expect them to look blank?
P.S. Yes, you need an edit button and a resizable box for text entry!
Kristian Vättö - Tuesday, April 29, 2014 - link
The way NAND flash works is that electrons are injected to what is called a floating gate, which is insulated from the other parts of the transistor. As it is insulated, the electrons can't escape the floating gate and thus SSDs are able to hold the data. However, as the SSD is written to, the insulating layer will wear out, which decreases its ability to insulate the floating gate (i.e. make sure the electrons don't escape). That causes the decrease in data retention time.Figuring out the exact data retention time isn't really possible. At the maximum endurance, it should be 1 year for client drives and 3 months for enterprise drives but anything before and after is subject to several variables that the end-user don't have access to.
Solid State Brain - Tuesday, April 29, 2014 - link
Data retention depends mainly on NAND wear. It's the highest (several years - I've read 10+ years even for TLC memory though) at 0 P/E cycles and decreases with usage. By JEDEC specifications, consumer SSDs are to be considered at "end life" when the minimum retention time drops below 1 year, and that's what you should expect when reaching the P/E "limit" (which is not actually a hard limit, just a threshold based on those JEDEC-spec requirements). For enterprise drives it's 3 months. Storage temperature will also affect retention. If you store your drives in a cool place when unpowered, their retention time will be longer. By JEDEC specifications the 1 year time for consumer drives is at 30C, while the 3 months time for enterprise one is at 40C. Tidbit: manufacturers use to bake NAND memory in low temperature ovens to simulate high wear usage scenarios during tests.To be refreshed, data has to be reprogrammed again. Just powering up an SSD is not going to reset the retention time for the existing data, it's only going to make it temporarily slow down.
When powered, the SSD's internal controller keeps track of when writes occurred and reprograms old blocks as needed to make sure that data retention is maintained and consistent across all data. This is part of the wear leveling process, which usually is pretty efficient in keeping block usage consistent. However, I speculate this can happen only to a certain extent/rate. A worn drive left unpowered for a long time should preferably have its data dumped somewhere and then cloned back, to be sure that all NAND blocks have been refreshed and that their retention time has been reset to what their wear status allow.
hojnikb - Wednesday, April 23, 2014 - link
TLC is far from crap (well quality one that is). And no, TLC does not have issues holding a "charge". Jedec states a minimum of 1 year of data retention, so your statement is complete bullshit.apudapus - Wednesday, April 23, 2014 - link
TLC does have issues but the issues can be mitigated. A drive made up of TLC NAND requires much stronger ECC compared to MLC and SLC.Notmyusualid - Tuesday, April 22, 2014 - link
My SLC X25-E 64GB is still chugging along, with not so much as a hiccup.It n e v e r slows down, it 'felt' fast constantly, not matter what is going on.
In about that time I've had one failed OCZ 128GB disk (early Indullix I think), one failed Kingston V100, one failed Corsair 100GB too (model forgotten), a 160GB X25-M arrived DOA (but it's replacement is still going strong in a workstation), and late last year a failed Patriot Wildfire 240GB.
The two 840 Evo 250GB disks I have (TLC) are absolute garbage. So bad I had to remove them from the RAID0, and run them individually. When you want to over-write all the free space - you'd better have some time on your hands.
SLC for the win.
Solid State Brain - Wednesday, April 23, 2014 - link
The X25-E 64 GB actually has 80 GiB of NAND memory on its PCB. Since of these only 64 GB (-> 59.6 GiB) are available to the user, it means that about 25% of it is overprovisining area. The drive is obviously going to excel in performance consistency (at least for its time).On the other hand, the 840 250 GB EVO has less OP than the previous 840 models with TLC memory, as you have to subtract 9 GiB from the 23.17 GiB amount of unavailable space (256 GiB of physically installed NAND - 250 GB->232.83 GiB of user space) previously fully used as overprovisioning area, for the Turbowrite feature. This means that in trim-less or intensive write environments with little or no free space they're not going to be that great in performance consistency.
If you were going to use The Samsung 840 EVOs in a RAID-0 configuration you should really had at the very least to increase the OP area by setting up trimmed, unallocated space. So, it's not really that they are "absolute garbage" (as they obviously they aren't) and it's really inherently due to the TLC memory. It's your fault in that you most likely didn't take the necessary steps to use them properly with your RAID configuration.
Solid State Brain - Wednesday, April 23, 2014 - link
I meant:*...and it's NOT really inherently due to the...
TheWrongChristian - Friday, April 25, 2014 - link
> When you want to over-write all the free space - you'd better have some time on your hands.Why would you overwrite all the free space? Can't you TRIM the drives?
Any why run them in RAID0? Can't you use them as JBOD, and combine volumes?
SLC versus TLC results in a about a factor of 4 cheaper just based on a die area basis. That's why drives are MLC and TLC based, the extra storage being used to add extra spare area to make the drive more economical over the drives useful life. Your SLC x25-e, on the other hand, will probably never ever reach it's P/E limit before you discard it for a more useful, faster, bigger replacement drive. We'll probably have practical memrister based drives before the x25-e uses all it's P/E cycles.
zodiacsoulmate - Tuesday, April 22, 2014 - link
It make me think about my OCZ vector 256GB, it breaks everytime there is power lose, even hard reset...There are quite a lot people claim this problem online, and Vector 256GB became only sale refurbised before any other vector drive....
I RMAed two of them, and OCZ replaced mine with Vector 150, which seems fine now.. maybe we should add power lost test to SSDs...