A Closer Look at Android RunTime (ART) in Android L
by Andrei Frumusanu on July 1, 2014 7:12 PM EST64-Bit Support
ART was designed in mind with modularity of the various target architectures in which it is supposed to run on. As such, it provides a multitude of compiler-backends targeting today’s most common architectures such as ARM, x86 and MIPS. In addition, 64-bit support for ARM64, x86-64 and while still not implemented, also MIPS64.
While we have gone more in depth of the advantages and implications of switching over to 64-bit architectures in the iPhone 5s review, the main points to take away are the availability of an increased address space, generally increased performance, and vastly increased cryptographic capabilities and performance, all while maintaining full 32-bit compatibility with all existing apps.
An important difference that Google is applying over Apple, at least inside VM runtime applications, is that they are using reference compression to avoid the usual memory bloat that comes with the switch to 64-bit. The VM retains simple 32-bit references.
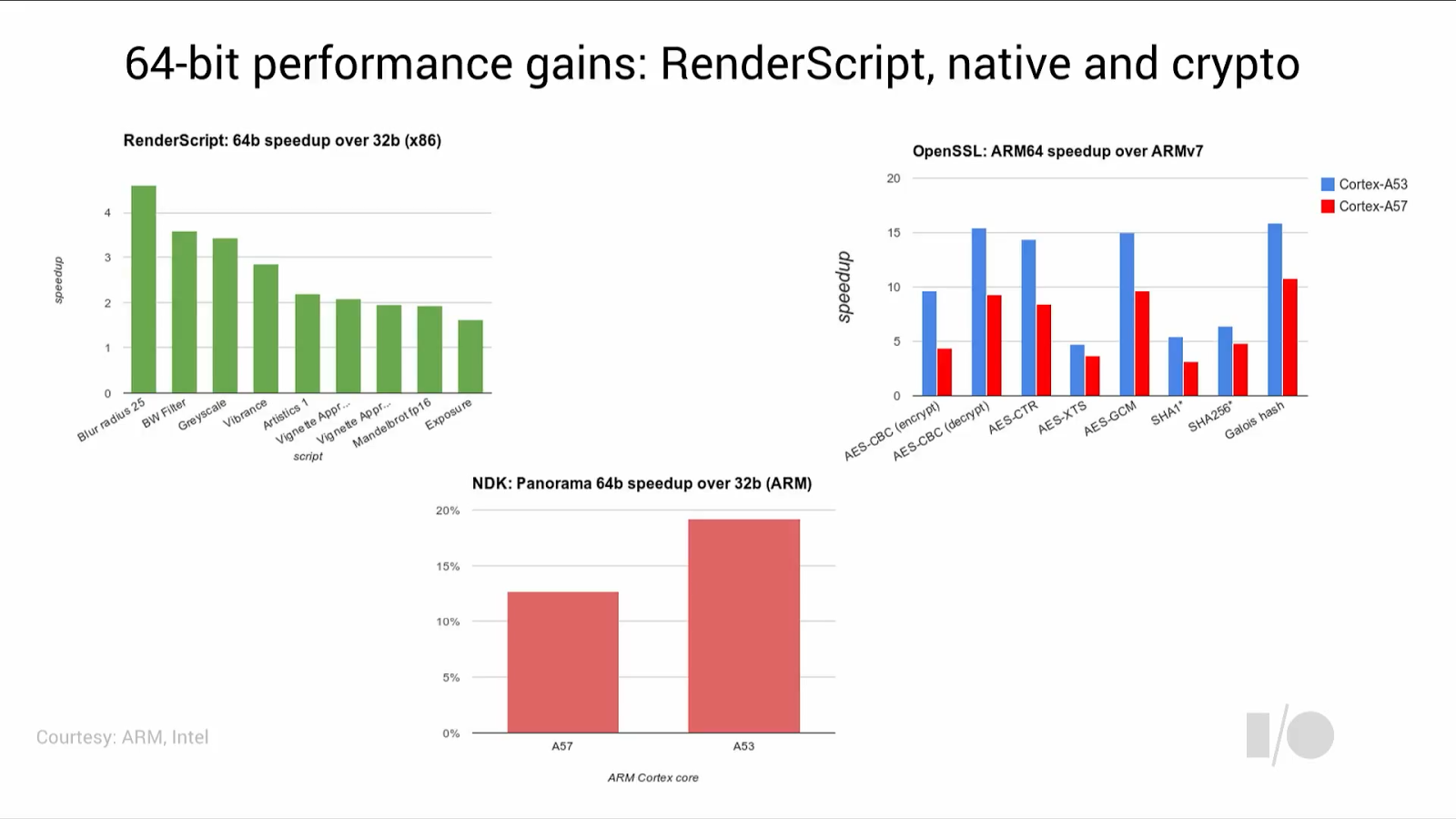
Google has made available some preview benchmarks showcasing the performance gains both on x86 and ARM platforms. The x86 benchmarks were executed on a Intel BayTrail system, and show a 2x to 4.5x speedup in various RenderScript benchmarks. On the ARM side, the crypto performance gains over 32-bit were showcased on an A57/A53 system. Both of these are relatively non-representative of one should really expect in real-world use-cases so they’re not that useful as a performance prediction.
However Google also made some interesting numbers available on one of their internal build-systems called Panorama. Here we can see a 13 to 19% increase in performance by simply switching over the ABI. It is also good to see how ARM’s Cortex A53 is able to make a bigger impact on performance when in AArch64 mode than the A57 cores.
Google claims that 85% of all current Play Store apps are immediately ready to switch over to 64 bit - which would mean that only 15% of applications have some kind of native code that needs targeted recompiling by the developer to make use of 64-bit architectures. This is a great win for Google and I expect the shift over to 64-bit to be very fast once silicon vendors start shipping 64-bit SoCs in the coming year.
Conclusion
In many points, Google has delivered its “Performance boosting thing” and addressed much of the shortcomings that have plagued Android for years.
ART patches up many of the Achilles’ heels that comes with running non-native applications and having an automatic memory management system. As a developer, I couldn’t have asked for more, and most performance issues that I needed to work around with clever programming no longer pose such a drastic problem anymore.
This also means that Android is finally able to compete with iOS in terms of application fluidity and performance, a big win for the consumer.
Google still promises to evolve ART in the future and its current state is definitely not what it was 6 months ago, and definitely not what it will be once the L release is made available in its final form in devices. The future looks bright and I can’t wait to see what Google will do with its new runtime.








136 Comments
View All Comments
johncuyle - Wednesday, July 2, 2014 - link
It's not a great reason to discourage the NDK. Many applications are written to be cross platform and run successfully on multiple architectures. It doesn't even increase your test load, since even if you're writing your application in Java you still do need to fully test it on every platform. Test is usually the expensive part. The exact wording of the page is just odd. It says that preferring C++ isn't a good reason to write your application in C++. That's a pretty obviously false assertion. Preferring C++ is a great reason to write your application in C++.Exophase - Monday, July 7, 2014 - link
Not directly, since this applies to DEX which never had a compatibility issue. But it might convince some app developers to stop using NDK due to the improved performance of DEX binaries.johncuyle - Tuesday, July 1, 2014 - link
The frame drop counts seem very odd with respect to the total milliseconds delayed. (Or I'm bad at math.) At 60 FPS a frame is 16 ms. A 4ms GC sweep might drop a single frame at 60fps. The output indicates it dropped 30 frames. That's 750fps. Plausible if you're running without vsync or framerate limiting on a static screen like a splash screen, but that's not really a meaningful example, nor is it especially noticeable to the end user. More interesting would be the frequency of a frame drop in an application with extensive animation running at an average of 30fps. That's going to be a situation where you notice every frame drop.kllrnohj - Tuesday, July 1, 2014 - link
It's a mistake in the article. Those log lines have nothing to do with each other. The Choreographer is reporting a huge amount of dropped frames because <unknown> took a really long time on the UI thread, *NOT* because specifically the GC took that time. This is actually pretty normal, as when an application is launched the UI loading & layout all happens on the UI thread, which the Choreographer reports as "dropped" frames even though there wasn't actually any frames to draw in the first place as the app hadn't loaded yet. So the 30 dropped frames there means the application took about 500ms to load, which isn't fantastic but it's far from bad.Stonebits - Tuesday, July 1, 2014 - link
"Overhead such as exception checks in code are largely removed, and method and interface calls are vastly sped up"This doesn't make sense to me--are exceptions handled some other way, or do you just keep executing?
extide - Tuesday, July 1, 2014 - link
If an exception is not handled, your application crashes.Gigaplex - Thursday, July 3, 2014 - link
If the compiler can statically prove that a given piece of code won't throw, there's no need to insert the exception handling support. Not all exceptions will be removed by the compiler though.Impulses - Tuesday, July 1, 2014 - link
Hah, that PBT link was pretty funny... PBT FTWhackbod - Wednesday, July 2, 2014 - link
Re: "Because ART compiles an ELF executable, the kernel is now able to handle page handling of code pages - this results in possibly much better memory management, and less memory usage too."There shouldn't really be any difference. Dalvik was carefully designed so that its odex format could be mmapped in to RAM, allowing the kernel to do the same page handling as with ELF executables. (Actually a little better than regular ELF executables, since odex doesn't need any relocations that cause dirty pages.)
The "ProcessStateJankPerceptible" and "ProcessStateJankImperceptible" are the process coming in and out of the foreground. When it goes out of the foreground, the GC switches to a compacting mode that takes more time to run but saves more RAM. When it switches back to the foreground, it switches to the faster GC you have been looking at. The GC pauses here won't cause any jank, because these switches are never done when the app is on screen.
tuxRoller - Wednesday, July 2, 2014 - link
KSM mostly kicks in on virt loads, but the ksmd overhead is so small that including it on memory starved, multiprocess devices isn't a bad idea.BTW, I believe that android use the dalvik cache partition to avoid unnecessary re-jitting, but the space is limited, and therefore dynamic, so apps can be vacated.