6 TB NAS Drives: WD Red, Seagate Enterprise Capacity and HGST Ultrastar He6 Face-Off
by Ganesh T S on July 21, 2014 11:00 AM ESTFeature Set Comparison
Enterprise hard drives come with features such as real time linear and rotational vibration correction, dual actuators to improve head positional accuracy, multi-axis shock sensors to detect and compensate for shock events and dynamic fly-height technology for increasing data access reliability. For the WD Red units, Western Digital incorporates some features in firmware under the NASware moniker. We have already covered these features in our previous Red reviews. These hard drives also expose some of their interesting firmware aspects through their SATA controller.
A high level overview of the various supported SATA features is provided by HD Tune Pro 5.50
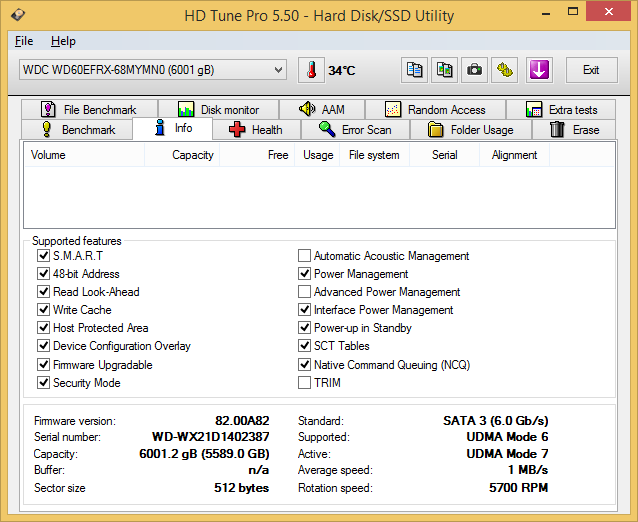
The HGST Ultrastar He6 supports almost all features (except for TRIM - this is obviously not a SSD - and Automatic Acoustic Management - a way to manage the sound levels by adjusting the seek velocity of the heads). The Seagate Enterprise Capacity drive avoids the host protected area and device configuration overlay, as well as the power management features. APM's absence means that the head parking interval can't be set through ATA commands by the NAS OS. Device Configuration Overlay allows for the hard drive to report modified drive parameters to the host. It is not a big concern for most applications. Coming to the WD Red, we find it is quite similar to the Ultrastar He6 in the support department, except for the absence of APM (Advanced Power Management).
We get a better idea of the supported features using FinalWire's AIDA64 system report. The table below summarizes the extra information generated by AIDA64 (that is not already provided by HD Tune Pro).
| Supported Features | |||
| WD Red | Seagate Enterprise Capacity v4 | HGST Ultrastar He6 | |
| DMA Setup Auto-Activate | Supported, Disabled | Supported, Disabled | Supported, Disabled |
| Extended Power Conditions | Not Supported | Supported, Enabled | Supported, Enabled |
| Free-Fall Control | Not Supported | Not Supported | Not Supported |
| General Purpose Logging | Supported, Enabled | Supported, Enabled | Supported, Enabled |
| In-Order Data Delivery | Not Supported | Not Supported | Supported, Disabled |
| NCQ Priority Information | Supported | Not Supported | Supported |
| Phy Event Counters | Supported | Supported | Supported |
| Release Interrupt | Not Supported | Not Supported | Not Supported |
| Sense Data Reporting | Not Supported | Supported, Disabled | Supported, Disabled |
| Software Settings Preservation | Supported, Enabled | Supported, Enabled | Supported, Enabled |
| Streaming | Supported, Disabled | Not Supported | Supported, Enabled |
| Tagged Command Queuing | Not Supported | Not Supported | Not Supported |
Interesting aspects are highlighted in the above table. While the two enterprise drives support the extended power conditions (EPC) extensions for fine-grained power management, the Red lineup doesn't. NCQ priority information adds priority to data in complex workload environments. While WD and HGST have it enabled on their drives, Seagate seems to believe it is unnecessary. The NCQ streaming feature enables isochronous data transfers for multimedia streams while also improving performance of lower priority transfers. This feature could be very useful for media server and video editing use-cases. The Seagate enterprise drive doesn't support it, and, surprisingly, the Red seems to have disabled it by default.








83 Comments
View All Comments
jabber - Tuesday, July 22, 2014 - link
Quality of HDDs is plummeting. The mech drive makers have lost interest, they know the writing is on the wall. Five years ago it was rare to get a HDD fail of less than 6 months old. But now I regularly get in drives with bad sectors/failed mechanics in that are less than 6-12 months old.I personally don't risk using any drives over a terrabyte for my own data.
asmian - Tuesday, July 22, 2014 - link
You're not seriously suggesting that WD RE drives are the same as Reds/Blacks or whatever colour but with a minor firmware change, are you? If they weren't significantly better build quality to back up the published numbers I'm sure we'd have seen a court case by now, and the market for them would have dried up long ago.On the subject of my rebuild failure calculation, I wonder whether that is exactly what happened to the failing drive in the article: an unrecoverable bit read error during an array rebuild, making the NAS software flag the drive as failed or failing, even though the drive subsequently appears to perform/test OK. Nothing to do with compatability, just the verification of their unsuitability for use in arrays due to their size increasing the risk of bit read errors occurring at critical moments.
NonSequitor - Tuesday, July 22, 2014 - link
It's more likely that they are binned than that they are manufactured differently. Think of it this way: you manufacture a thousand 4TB drives, then you take the 100 with the lowest power draw and vibration. Those are now RE drives. Then the rest become Reds.Regarding the anecdotes of users with several grouped early failures: I tend to blame some of that on low-dollar Internet shopping, and some of it on people working on hard tables. It takes very little mishandling to physically damage a hard drive, and even if the failure isn't initial a flat spot in a bearing will eventually lead to serious failure.
Iketh - Tuesday, July 22, 2014 - link
LOL nom0du1us - Friday, July 25, 2014 - link
@NonSequitor This is exactly how enterprise drives are chosen, as well as using custom firmware.LoneWolf15 - Friday, July 25, 2014 - link
Aren't most of our drives fluid-dynamic bearing rather than ball bearing these days?asmian - Wednesday, July 23, 2014 - link
Just in case anyone is still denying the inadvisability of using these 6TB consumer-class Red drives in a home NAS, or any RAID array that's not ZFS, here's the maths:6TB is approx 0.5 x 10^14 bits. That means if you read the entire disk (as you have to do to rebuild a parity or mirrored array from the data held on all the remaining array disks) then there's a 50% chance of a disk read error for a consumer-class disk with 1 in 10^14 unrecoverable read error rate (check the maker's specs). Conversely, that means there's a 50% chance that there WON'T be a read error.
Let's say you have a nice 24TB RAID6 array with 6 of these 6TB Red drives - four for data, two parity. RAID6, so good redundancy right? Must be safe! One of your disks dies. You still have a parity (or two, if it was a data disk that died) spare, so surely you're fine? Unfortunately, the chance of rebuilding the array without ANY of the disks suffering an unrecoverable read error is: 50% (for the first disk) x 50% (for the second) x 50% (for the third) x 50% (for the fourth) x 50% (for the fifth. Yes, that's ** 3.125% ** chance of rebuilding safely. Most RAID controllers will barf and stop the rebuild on the first error from a disk and declare it failed for the array. Would you go to Vegas to play those odds of success?
If those 6TB disks had been Enterprise-class drives (say WD RE, or the HGST and Seagates reviewed here) specifically designed and marketed for 24/7 array use, they have a 1 in 10^15 unrecoverable error rate, an order of magnitude better. How does the maths look now? Each disk now has a 5% chance of erroring during the array rebuild, or a 95% chance of not. So the rebuild success probability is 95% x 95% x 95% x 95% x 95% - that's about 77.4% FOR THE SAME SIZE OF DISKS.
Note that this success/failure probability is NOT PROPORTIONAL to the size of the disk and the URE rate - it is a POWER function that squares, then cubes, etc. given the number of disks remaining in the array. That means that using smaller disks than these 6TB monsters is significant to the health of the array, and so is using disks with much better URE figures than consumer-class drives, to an enormous extent as shown by the probability figure above.
For instance, suppose you'd used an eight-disk RAID6 of 6TB Red drives to get the same 24TB array in the first example. Very roughly your non-error probability per disk full read is now 65%, so the probability of no read errors over a 7-disk rebuild is roughly 5%. Better than 3%, but not by much. However, all other things being equal, using far smaller disks (but more of them) to build the same size of array IS intrinsically safer for your data.
Before anyone rushes to say none of this is significant compared to the chance of a drive mechanically failing in other ways, sure, that's an ADDITIONAL risk of array failure to add to the pretty shocking probabilities above. Bottom line, consumer-class drives are intrinsically UNSAFE for your data at these bloated multi-terabyte sizes, however much you think you're saving by buying the biggest available, since the build quality has not increased in step with the technology cramming the bits into smaller spaces.
asmian - Wednesday, July 23, 2014 - link
Apologies for proofing error: "For instance, suppose you'd used an eight-disk RAID6 of 6TB Red drives" - obviously I meant 4TB drives.KAlmquist - Wednesday, July 23, 2014 - link
"6TB is approx 0.5 x 10^14 bits. That means if you read the entire disk (as you have to do to rebuild a parity or mirrored array from the data held on all the remaining array disks) then there's a 50% chance of a disk read error for a consumer-class disk with 1 in 10^14 unrecoverable read error rate (check the maker's specs)."What you are overlooking is that even though each sector contains 4096 bytes, or 32768 bits, it doesn't follow that to read the contents of the entire disk you have to read the contents of each sector 32768 times. To the contrary, to read the entire disk, you only have to read each sector once.
Taking that into account, we can recalculate the numbers. A 5.457 gigabyte drive contains 1,464,843,750 sectors. If the probability of an unrecoverable read error is 1 in 10^14, and the probability of a read error on one sector is independent of the probability of a read error in any other sector, then the probability of getting a read error at some point when reading the entire disk is 0.00146%. I suspect that the probability of getting a read error in one sector is probably not independent of the probability of getting a read error in any other sector, meaning that the 0.00146% figure is too high. But sticking with that figure, it gives us a 99.99268% probability of rebuilding safely.
I don't know of anyone who would dispute that the correct way for a RAID card to handle an unrecoverable read error is to calculate the data that should have been read, try to write it to the disk, and remove the disk from the array if the write fails. (This assumes that the data can be computed from data on the other disks, as is the case in your example of rebuilding a RAID 6 array after one disk has been replaced.) Presumably a lot of RAID card vendors assume that unrecoverable read errors are rare enough that the benefits of doing this right, rather than just assuming that the write will fail without trying, are too small to be worth the cost.
asmian - Wednesday, July 23, 2014 - link
That makes sense IF (and I don't know whether it is) the URE rate is independent of the number of bits being read. If you read a sector you are reading a LOT of bits. You are suggesting that you would get 1 single URE event on average in every 10^14 sectors read, not in every 10^14 BITS read... which is a pretty big assumption and not what the spec seems to state. I'm admittedly suggesting the opposite extreme, where the chance of a URE is proportional to the number of bits being read (which seems more logical to me). Since you raise this possibility, I suspect the truth is likely somewhere in the middle, but I don't know enough about how UREs are calculated to make a judgement. Hopefully someone else can weigh in and shed some light on this.Ganesh has said that previous reviews of the Red drives mention they are masking the UREs by using a trick: "the drive hopes to tackle the URE issue by silently failing / returning dummy data instead of forcing the rebuild to fail (this is supposed to keep the RAID controller happy)." That seems incredibly scary if it is throwing bad data back in rebuild situations instead of admitting it has a problem, potentially silently corrupting the array. That for me would be a total deal-breaker for any use of these Red drives in an array, yet again NOT mentioned in the review, which is apparently discussing their suitability for just that... <sigh>