ASRock X99 WS-E/10G Motherboard Review: Dual 10GBase-T for Prosumers
by Ian Cutress on December 15, 2014 10:00 AM EST- Posted in
- Motherboards
- IT Computing
- Intel
- ASRock
- Enterprise
- X99
- 10GBase-T
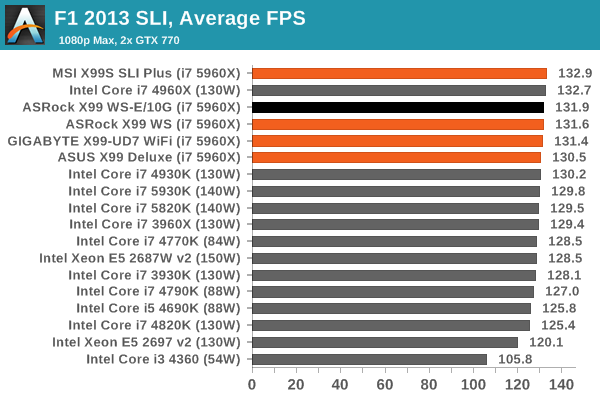
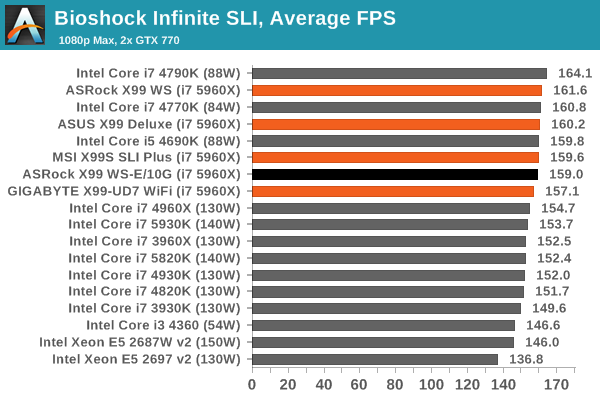
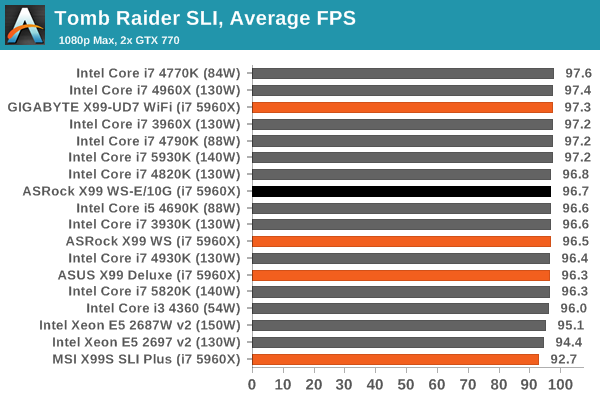
Gaming Performance
An interesting point to consider is the addition of the PLX8747 chips to allow for x16/x16/x16/x16 PCIe layouts. In previous reviews we have noted that these chips barely reduce the frame rate if at all, however one could suggest that as the X99 WS-E/10G uses two of them (and we split our SLI testing cards between them), there might be more room for additional delays.
Ultimately however our results were within the same range as the other X99 motherboards, suggesting that PCIe bandwidth on this scale (1080p, max settings) is not affected. It would be interesting to see a three or four-way SLI setup powering several 4K monitors.
F1 2013
First up is F1 2013 by Codemasters. I am a big Formula 1 fan in my spare time, and nothing makes me happier than carving up the field in a Caterham, waving to the Red Bulls as I drive by (because I play on easy and take shortcuts). F1 2013 uses the EGO Engine, and like other Codemasters games ends up being very playable on old hardware quite easily. In order to beef up the benchmark a bit, we devised the following scenario for the benchmark mode: one lap of Spa-Francorchamps in the heavy wet, the benchmark follows Jenson Button in the McLaren who starts on the grid in 22nd place, with the field made up of 11 Williams cars, 5 Marussia and 5 Caterham in that order. This puts emphasis on the CPU to handle the AI in the wet, and allows for a good amount of overtaking during the automated benchmark. We test at 1920x1080 on Ultra graphical settings.
Bioshock Infinite
Bioshock Infinite was Zero Punctuation’s Game of the Year for 2013, uses the Unreal Engine 3, and is designed to scale with both cores and graphical prowess. We test the benchmark using the Adrenaline benchmark tool and the Xtreme (1920x1080, Maximum) performance setting, noting down the average frame rates and the minimum frame rates.

Tomb Raider
The next benchmark in our test is Tomb Raider. Tomb Raider is an AMD optimized game, lauded for its use of TressFX creating dynamic hair to increase the immersion in game. Tomb Raider uses a modified version of the Crystal Engine, and enjoys raw horsepower. We test the benchmark using the Adrenaline benchmark tool and the Xtreme (1920x1080, Maximum) performance setting, noting down the average frame rates and the minimum frame rates.

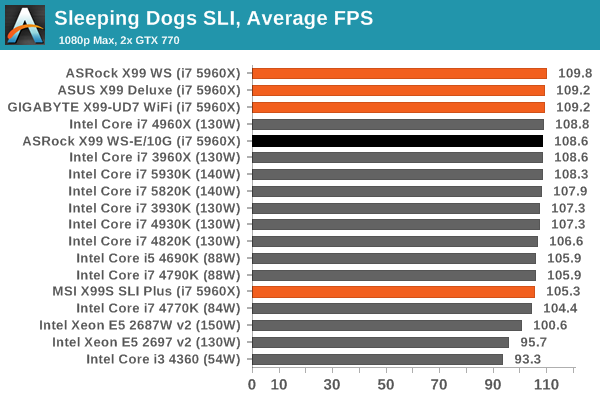
Sleeping Dogs
Sleeping Dogs is a benchmarking wet dream – a highly complex benchmark that can bring the toughest setup and high resolutions down into single figures. Having an extreme SSAO setting can do that, but at the right settings Sleeping Dogs is highly playable and enjoyable. We run the basic benchmark program laid out in the Adrenaline benchmark tool, and the Xtreme (1920x1080, Maximum) performance setting, noting down the average frame rates and the minimum frame rates.

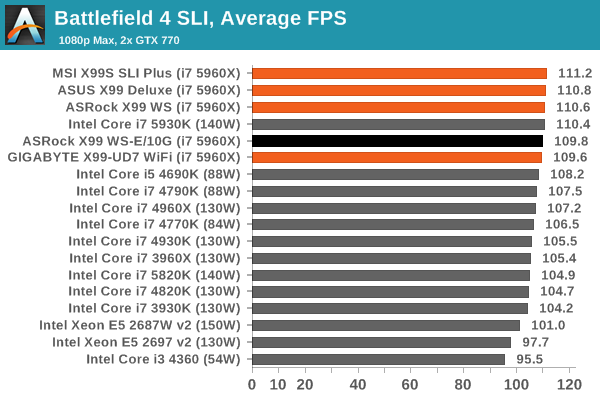
Battlefield 4
The EA/DICE series that has taken countless hours of my life away is back for another iteration, using the Frostbite 3 engine. AMD is also piling its resources into BF4 with the new Mantle API for developers, designed to cut the time required for the CPU to dispatch commands to the graphical sub-system. For our test we use the in-game benchmarking tools and record the frame time for the first ~70 seconds of the Tashgar single player mission, which is an on-rails generation of and rendering of objects and textures. We test at 1920x1080 at Ultra settings.









45 Comments
View All Comments
Jammrock - Monday, December 15, 2014 - link
You can achieve 10Gb speeds (~950MB/s-1.08Gb/s real world speeds) on a single point-to-point transfer if you have the right hardware and you know how to configure it. Out-of-the-box...not likely. The following assumes your network hardware is all 10Gb and jumbo frame capable and enabled.1. You need a source that can sustain ~1GB/s reads and a destination that can sustain ~1GB/s writes. A couple of high end PCIe SSD cards, RAID'ed SSDs or a RAMdisk can pull it off, and that's about it.
2. You need a protocol that supports TCP multi-channel. SMB3, when both source and destination are SMB3 capable (Win8+/2012+), does this by default. Multi-threaded FTP can. I think NFS can, but I'm not 100% certain...
3. You need RSS (Receive Side Scaling), LSO (Large Send/Segment Offloading), TCP window scaling (auto tuning) and TCP Chimney (for Windows), optionally RSC (Receive Side Coalescing), are setup and configured properly.
Even modern processors cannot handle 10Gb worth of reads on a single processor core, thus RSS needs setup with a minimum of 4 physical processor cores (RSS doesn't work on Hyperthreaded logical cores), possibly 8, depending on processor, to distribute receive load across multiple processors. You can do this via PowerShell (Windows) with the Set-NetAdapterRss cmdlet.
# example command for a 4 physical core proc w/ Hyerpthreading (0,2,4,6 are physical, 1,3,5,7 are logical....pretty much a rule of thumb)
Set-NetAdapterRss -Name "<adapter name>" -NumberOfReceiveQueues 4 -BaseProcessorNumber 0 -MaxProcessorNumber 6 -MaxProcessors 4 -Enabled
LSO is set in the NIC drivers and/or PowerShell. This allows Windows/Linux/whatever to create a large packet (say 64KB-1MB) and let the NIC hardware handle segmenting the data to the MSS value. This lowers processor usage on the host and makes the transfer faster since segmenting is faster in hardware and the OS has to do less work.
RSC is set in Windows or Linux and on the NIC. This does the opposite of LSO. Small chunks are received by the NIC and made into one large packet that is sent to the OS. Lowers processor overhead on the receive side.
While TCP Chimney gets a bad rap in the 1Gb world, it shines in the 10Gb world. Set it to Automatic in Windows 8+/2012+ and it will only enable on 10Gb networks under certain circumstances.
TCP window scaling (auto-tuning in the Windows world) is an absolute must. Without it the TCP windows will never grow large enough to sustain high throughput on a 10Gb connection.
4. Enable 9K jumbo frames (some people say no, some say yes...really depends on hardware, so test both ways).
5. Use a 50GB file or larger. You need time for the connection to ramp up before you reach max speeds. A 1GB file is way too small to test a 10Gb connection. To create a dummy file in Windows use fsutil: fsutil file createnew E:\Temp\50GBFile.txt 53687091200
This will normally get you in the 900 MB/s range on modern hardware and fast storage. LSO and TCP Chimney makes tx faster. RSS/RSC make rx faster. TCP multi-channel and auto-tuning give you 4-8 fast data streams (one for each RSS queue) on a single line. The end result is real world 10Gb data transfers.
While 1.25GB/s is the theoretical maximum, that is not the real world max. 1.08GB/s is the fastest I've gone on a single data transfer on 10Gb Ethernet. That was between two servers in the same blade chassis (essentially point-to-point with no switching) using RAM disks. You can't really go much faster than that due to protocol overhead and something called bandwidth delay product.
Ian Cutress - Monday, December 15, 2014 - link
Hi Jammrock, I've added a link in the main article to this comment - it is a helpful list of information for sure.For some clarification, our VMs were set for RAMDisk-to-RAMDisk operation, but due only having UDIMMs on hand the size of our RAMDisks was limited. Due to our internal use without a switch, not a lot else was changed in the operation, making it more of an out-of-the-box type of test. There might be scope for ASRock to apply some form of integrated software to help optimise the connection. If possible I might farm out this motherboard to Ganesh for use in future NAS reviews, depending on his requirements.
staiaoman - Monday, December 15, 2014 - link
wow. Such a concise summary of what to do in order to achieve high speed network transfers...something so excellent shouldnt just be buried in the comments on Anandtech (although if it has to be in the comments of a site, Anand or STH.com are clearly the right places ;-P). Thanks Jammrock!!Hairs_ - Monday, December 15, 2014 - link
Excellent comment, but it just underlines what a ridiculously niche product this is.Anyone running workloads like this surely isn't doing it using build it yourself equipment over a home office network?
While this sort of arrive no doubt is full of interesting concepts to research for the reviewer, it doesn't help 99% of builders or upgraders out there.
Where are the budget/midrange haswell options? Given the fairly stagnant nature of the amd market, what about an article on long term reliability? Both things which actually might be of interest to the majority of buyers.
Nope, another set of ultra-niche motherboard reviews for those spending several hundred dollars.
The reviews section on newegg is more use as a resource at this stage.
Harald.1080 - Monday, December 15, 2014 - link
It's not that complicated.We set up 2 xeon E5 single socket machines with esxi 5.1, some guests on both machines, a 800€ 10g switch, and as the NAS backup machine a xeon E3 with 2 samsung 840pro in raid0 as fastcache in front of a fast raid5 disk system. NFS. All 3 machines with intel single port 10g. Jumbo frames.
Linux vm guest A to other hosts vm guest B with ramdiskt 1GB/s from the start.
Vmware hosts to NAS (the xeon E3 NFS System) with ssd cache: 900 MB/s write. w/o cache: 20 MB/s
Finally used Vmdk disk tools to copy snapshotted disks for backup. Faster than file copy.
I think, doing the test on the SAME MACHINE is a bad idea. Interrupt handlers will have a big effect on the results. What about Queues?
shodanshok - Tuesday, December 16, 2014 - link
I had similar experience on two Red Hat 6 boxes using Broadcomm's NetXtreme II BCM57810 10 Gb/s chipset. The two boxes are directly connected by a Cat 6e cable, and the 10GBASE-T adapters are used to synchronize two 12x 15K disks arrays (sequential read > 1.2 GB/s)RSS is enabled by default, and so are TCO and the likes. I manually enabled jumbo frames on both interface (9K MTU). Using both netperf and iperf, I recorded ~9.5 Gb/s (1.19 GB/s) on UDP traffic and slightly lower (~9.3 Gb/s) using TCP traffic.
Jumbo frames really made a big difference. A properly working TCP windows scaling alg is also a must have (I had two 1 Gb/s NICs with very low DRBD throughput - this was due to bad window scaling decision from the linux kernel when using a specific ethernet chip driver).
Regards.
jbm - Saturday, December 20, 2014 - link
Yes, the configuration is not easy, and you have to be careful (e.g. if you want to use SMB multichannel over several NICs, you need to have them in separate subnets, and you should make sure that the receive queues for the NICs are not on the same CPU cores). Coincidentally, I configured a couple servers for hyper-v at work recently which use Intel 10Gb NICs. With two 10Gb NICs, we get live migration speeds of 2x 9.8Gb/s, so yes - it does work in real life.Daniel Egger - Monday, December 15, 2014 - link
> The benefits of 10GBase-T outside the data center sound somewhat limited.Inside the data center the benefits are even more limited as there's usually no problem running fibre which is easier to handle, takes less volume, uses less power and allows for more flexibility -- heck, it even costs less! No sane person would ever use 10GBase-T in a datacenter.
The only place where 10GBase-T /might/ make sense is in a building where one has to have cross room connectivity but cannot run fibre; but better hope for a good Cat.7 wiring and have the calibration protocol ready in case you feel the urge to sue someone because it doesn't work reliably...
gsvelto - Monday, December 15, 2014 - link
There's also another aspect that hasn't been covered by the review: the reason why 10GBase-T is so slow when used by a single user (or when dealing with small transfers, e.g. NFS with small files) is that it's latency is *horrible* compared to Direct Attach SFP+. A single hop over an SFP+ link can take as little as 0.3µs while one should expect at least 2µs per 10GBase-T link and it can be higher.This is mostly due to the physical encoding (which requires the smallest physical frame transferable to be 400 bytes IIRC) and the heavy DSP processing needed to extract the data bits from the signal. Both per-port price and power are also significantly.
In short, if you care about latency or small-packet transfers 10GBase-T is not for you. If you can't afford SFP+ then go for aggregated 1GBase-T links, they'll serve you well, give you lower latency and redundancy as the cherry on top.
shodanshok - Tuesday, December 16, 2014 - link
This is very true, but it really depend on the higher-level protocol you want to use over it.IP over Ethernet is *not* engineered for latency. Try to ping your localhost (127.0.0.1) address: on RHEL 6.5 x86-64 running on top of a Xeon E5-2650 v2 (8 cores at 2.6 GHz, with performance governor selected, no heavy processes running) RTT times are about 0.010 ms, or about 10 usec. On-way sending is about half, at 5us. Adding 2us is surely significant, but hardly world-changer.
This is for a localhost connection with a powerful processor and no other load. On a moderately-loaded, identical machine, the localhost RTT latency increase to ~0.03ms, or 15us for one-way connection. RTT for one machine to another is ranging from 0.06ms to 0.1ms, or 30-50us for one way traffic. As you can see, the 2-4us imposed by the 10Base-T encoding/decoding is rapidly fading away.
IP creators and stack writers know that. They integrated TCP window scaling, Jumbo frames et similar to overcome that very problem. Typically, when very low-latency is needed, some lightweight protocol is used *on top* of these low-latency optical links. Heck, even PCI-E, with its sub-us latency is often too slow for some kind of workload. For example, some T-series SPARC CPU include 10GB Ethernet links rightly into the CPU packages, using dedicated low-latency internal bus, but using classical IP schemes on top of these very fast connection will not give you very high gain over more pedestrian 10Base-T ethernet cards...
Regards.