ASRock X99 WS-E/10G Motherboard Review: Dual 10GBase-T for Prosumers
by Ian Cutress on December 15, 2014 10:00 AM EST- Posted in
- Motherboards
- IT Computing
- Intel
- ASRock
- Enterprise
- X99
- 10GBase-T
Testing the 10GBase-T
Many thanks to Brett Howse for his help!
As an indication of how far away from mainstream adoption of 10GBase-T we are, our testing setup was not ready to receive 10GBase-T – we have no switches or other PCIe cards in house to test the ports. Apart from that, one of the downsides of testing network ports as a whole is that any test out one machine and into another, meaning that and any result will always be at the whims of the lowest common denominator between the two systems. The easiest way to test is therefore to essentially loop back on itself. As the X540-BT2 is a dual port solution, this was ideal for the testing scenario.
We set up the system with ESXi and two Windows Server 2012 VMs, each allocated with 8 threads, 16 GB of DRAM and one of the 10GBase-T ports with custom IPs. We then used LAN Speed Test to set up a server on one VM and a client on the other. LAN Speed Test allows us to simulate multiple clients through the same cable, effectively probing our ports similar to a SOHO/SMB environment.
We organized a series of send/receive commands to go through the connections with differing numbers of streams and differing amounts of data per stream. The system was set to repeat for 10 minutes, and the peak transfer rate was recorded. Results shown are in Gbps.

There are several key points to note with these results.
- Firstly, single client speed never broke 2.2 Gbps. This puts an absolute limit on individual point-to-point communication speed in our system setup.
- Next, with between 4-9 clients the speed is fairly consistent between 6.7 and 8 Gbps, no matter what the size of the transfer is.
- Thus in order to get peak throughput, at least 10 concurrent connections need to be made. This is when 8+ Gbps is observed.
- With a small number of clients, a longer transfer results in higher overall speed. However with a larger amount of clients, faster transfers results in higher peak speed.
As part of the test, we also examined CPU usage when each stream was set for 1GB transfers. Normally CPU usage for a standard 1Gbit Ethernet port is minimal although one of the factors that some companies like to point to for increased gaming rates. Normally this rarely goes above a few percent on a quad core system, but with the X540-BT2 that changed, especially when the system was being hammered.
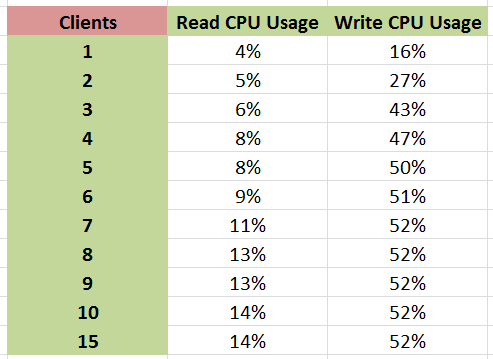
As the main VM alternated between reading and writing from the server VM, reading CPU usage peaked after 10 concurrent clients but write CPU usage shot up very quickly to 50% and stayed there. This might explain the slow increases in peak performance we observed, if the software simply ran out of threads and was only geared for four threads.

With a 4 core VM we saw 100% usage during writes, and above was the result in terms of CPU performance monitoring.
This marks an interesting juncture, suggesting that a faster single threaded CPU could deliver better performance and that the X540T-BT2 would be better attached to a Haswell/Broadwell platform – at least in our testing scenario. The truth of the matter is that fast connectivity technology runs on optimized FPGAs because general purpose CPUs cannot keep up with what is needed.
So where does leave the X99 WS-E/10G? The best example I could propose is in that SOHO/SMB environment where the system is connected to a 10Gbit/1Gbit mixed switch that has 24+ clients that all need to access the system, either as a virtualized workspace, some form of storage or a joint streaming venture. As the former, it allows the rest of the office to use very basic machines and rely on the grunt of the virtualized environment to perform tasks.
Additional: As mentioned in the comments, this is almost the complete out-of-the-box scenario where the only thing configured is the RAMDisk transfers and multiple stream application, whereas most users might be limited by the SSD speed. Jammrock in the comments has posted a list in helping to optimize the connection solely for individual point-to-point transfers and is worth a read.








45 Comments
View All Comments
gsvelto - Tuesday, December 16, 2014 - link
Where I worked we had extensive 10G SFP+ deployments with ping latency measured in single-digit µs. The latency numbers you gave are for pure-throughput oriented, low CPU overhead transfers and are obviously unacceptable if your applications are latency sensitive. Obtaining those numbers usually requires tweaking your power-scaling/idle governors as well as kernel offloads. The benefits you get are very significant on a number of loads (e.g. lots of small file over NFS for example) and 10GBase-T can be a lot slower on those workloads. But as I mentioned in my previous post 10GBase-T is not only slower, it's also more expensive, more power hungry and has a minimum physical transfer size of 400 bytes. So if you're load is composed of small packets and you don't have the luxury of aggregating them (because latency matters) then your maximum achievable bandwidth is greatly diminished.shodanshok - Wednesday, December 17, 2014 - link
Sure, packet size play a far bigger role for 10GBase-T then optical (or even copper) SFP+ links.Anyway, the pings tried before were for relatively small IP packets (physical size = 84 bytes), which are way lower then typical packet size.
For message-passing workloads SFP+ is surely a better fit, but for MPI it is generally better to use more latency-oriented protocol stacks (if I don't go wrong, Infiniband use a lightweight protocol stack for this very reason).
Regards.
T2k - Monday, December 15, 2014 - link
Nonsense. CAT6a or even CAT6 would work just fine.Daniel Egger - Monday, December 15, 2014 - link
You're missing the point. Sure Cat.6a would be sufficient (it's hard to find Cat.7 sockets anyway but the cabling used nowadays is mostly Cat.7 specced, not Cat.6a) but the problem is to end up with a properly balanced wiring that is capable of properly establishing such a link. Also copper cabling deteriorates over time so the measurement protocol might not be worth snitch by the time you try to establish a 10GBase-T connection...Cat.6 is only usable with special qualification (TIA-155-A) over short distances.
DCide - Tuesday, December 16, 2014 - link
I don't think T2k's missing the point at all. Those cables will work fine - especially for the target market for this board.You also had a number of other objections a few weeks ago, when this board was announced. Thankfully most of those have already been answered in the excellent posts here. It's indeed quite possible (and practical) to use the full 10GBase-T bandwidth right now, whether making a single transfer between two machines or serving multiple clients. At the time you said this was *very* difficult, implying no one will be able to take advantage of it. Fortunately, ASRock engineers understood the (very attainable) potential better than this. Hopefully now the market will embrace it, and we'll see more boards like this. Then we'll once again see network speeds that can keep up with everyday storage media (at least for a while).
shodanshok - Tuesday, December 16, 2014 - link
You are right, but the familiar RJ45 & cables can be a strong motivation to go with 10GBase-T in some cases. For a quick example: one of our customer bought two Dell 720xd to use as virtualization boxes. The first R720xd is the active one, while the second 720xd is used as hot-standby being constantly synchronized using DRBD. The two boxes are directly connected with a simple Cat 6e cable.As the final customer was in charge to do both the physical installation and the normal hardware maintenance, a familiar networking equipment as RJ45 port and cables were strongly favored by him.
Moreover, it is expected that within 2 die shrinks 10GBase-T controller become cheap/low power enough that they can be integrated pervasively, similar to how 1GBase-T replaced the old 100 Mb standard.
Regards.
DigitalFreak - Monday, December 15, 2014 - link
Don't know why the went with 8 PCI-E lanes for the 10Gig controller. 4 would have been plenty.1 PCI-E 3.0 lane is 1GB per second (x4 = 4GB). 10Gig max is 1.25 GB per second, dual port = 2.5 GB per second. Even with overhead you'd still never saturate an x4 link. Could have used the extra x4 for something else.
The Melon - Monday, December 15, 2014 - link
I personally think it would be a perfect board if they replaced the Intel X540 controller with a Mellanox ConnectX-3 dual QSFP solution so we could choose between FDR IB and 40/10/1Gb Ethernet per port.Either that or simply a version with the same slot layout and drop the Intel X540 chip.
Bottom line though is no matter how they lay it out we will find something to complain about.
Ian Cutress - Tuesday, November 1, 2016 - link
The controller is PCIe 2.0, not PCIe 3.0. You need to use a PCIe 3.0 controller to get PCIe 3.0 speeds.eanazag - Monday, December 15, 2014 - link
I am assuming we are talking about the free ESXi Hypervisor in the test setup.SR-IOV (IOMMU) is not an enabled feature on ESXi with the free license. What this means is that networking is going to tax the CPU more heavily. Citrix Xenserver does support SR-IOV on the free product, which it is all free now - you just pay for support. This is a consideration to base the results of the testing methodology used here.
Another good way to test 10GbE is using iSCSI where the server side is a NAS and the single client is where the disk is attached. The iSCSI LUN (hard drive) needs have something going on with an SSD. It can just be 3 spindle HDDs in RAID 5. You can use disk test software to drive the benchmarking. If you opt to use Xenserver with Windows as the iSCSI client. Have the VM directly connect to the NAS instead of using Xenserver to the iSCSI LUN because you will hit a performance cap from VM to host in the typical add disk within Xen. This is in older 6.2 version. Creedance is not fully out of beta yet. I have done no testing on Creedance and the contained changes are significant to performance.
About two years ago I was working on coming up with the best iSCSI setup for VMs using HDDs in RAID and SSDs as caches. I was using Intel X540-T2's without a switch. I was working with Nexenta Stor and Sun/Oracle Solaris as iSCSI target servers run on physical hardware, Xen, and VMware. I encountered some interesting behavior in all cases. VMware's sub-storage yielded better hard drive performance. I kept running into an artifical performance limit because of the Windows client and how Xen handles the disks it provides. The recommendation was to add the iSCSI disk directly to the VM as the limit wouldn't show up there. VMware still imposed a performance ding on (Hit>10%) my setup. Physical hardware had the best performance for the NAS side.