The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8

The story behind the high-end Xeon E7 has been an uninterrupted triumphal march for the past 5 years: Intel's most expensive Xeon beats Oracle servers - which cost a magnitude more - silly, and offers much better performance per watt/dollar than the massive IBM POWER servers. Each time a new generation of quad/octal socket Xeons is born, Intel increases the core count, RAS features, and performance per core while charging more for the top SKUs. Each time that price increases is justified, as the total cost of a similar RISC server is a factor more than an Xeon E7 server. From the Intel side, this new generation based upon the Haswell core is no different: more cores (18 vs 15), better RAS, slightly more performance per core and ... higher prices.
However, before you close this tab of your browser, know that even this high-end market is getting (more) exciting. Yes, Intel is correct in that the market momentum is still very much in favor of themselves and thus x86.
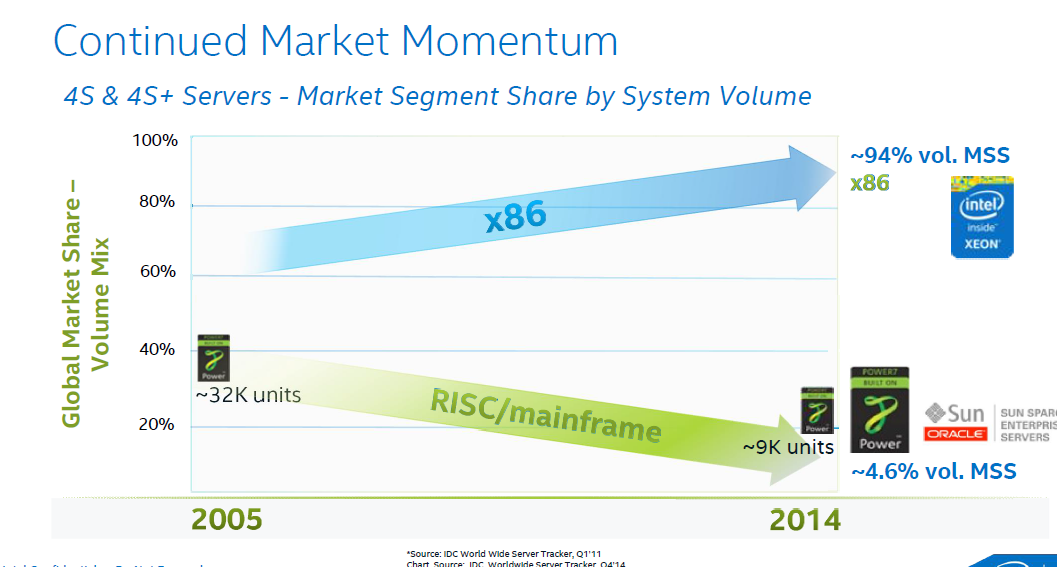
No less than 98% of the server shipments have been "Intel inside". No less than 92-94% of the four socket and higher servers contain Intel Xeons. From the revenue side, the RISC based systems are still good for slightly less than 20% of the $49 Billion (per year) server market*. Oracle still commands about 4% (+/- $2 Billion), but has been in a steady decline. IBM's POWER based servers are good for about 12-15% (including mainframes) or $6-7 Billion depending on who you ask (*).
It is however not game over (yet?) for IBM. The big news of the past months is that IBM has sold its x86 server division to Lenovo. As a result, Big Blue finally throw its enormous weight behind the homegrown POWER chips. Instead of a confusing and half heartly "we will sell you x86 and Itanium too" message, we now get the "time to switch over to OpenPOWER" message. IBM spent $1 billion to encourage ISVs to port x86-linux applications to the Power Linux platform. IBM also opened up its hardware: since late 2013, the OpenPower Foundation has been growing quickly with Wistron (ODM), Tyan and Google building hardware on top of the Power chips. The OpenPOWER Foundation now has 113 members, and lots of OpenPower servers are being designed and build. Timothy Green of the Motley fool believes OpenPower will threaten Intel's server hegemony in the largest server market, China.
But enough of that. This is Anandtech, and here we quantify claims instead of just rambling about changing markets. What has Intel cooked up and how does it stack up to the competion? Let's find out.
(*) Source: IDC Worldwide Quarterly Server Tracker, 2014Q1, May 2014, Vendor Revenue Share








146 Comments
View All Comments
Brutalizer - Monday, June 22, 2015 - link
@Troll KevinGI claim that SGI UV2000 is only used as a HPC cluster, and I claim scale-out servers such as UV2000 can not replace large Unix scale-up servers on business enterprise workloads. Here are my arguments:
1) I have posted several SGI links where SGI CTO and other SGI people, say UV2000 is exclusively for HPC market, and UV300H is for enterprise market.
2) SGI has ~50 customers UV2000 use cases on their web site and all are about HPC, such as datawarehouse analytics (US Postal Service). Nowhere on the website do SGI talk about scale-up workloads with UV2000.
3) There are no scale-up benchmarks on the whole wide internet, on large UV2000 servers, no SAP benchmarks, no database benchmarks, no nothing.
4) There are no articles or anonymous forum posts on the whole wide internet about any company using UV2000 for scale-up workloads.
5) SGI sales people said UV2000 is only for HPC workloads, in email exchange with me.
6) SAP says in numerous links, that the largest scale-up servers are 32 sockets, SAP never mention 256-socket. SAP talks about the UV300H server, and never mention UV2000. Remember that SAP has close ties to SGI.
And you claim the opposite, that the SGI UV2000 can in fact replace and outperforms large Unix servers on scale-up workloads, and tackle larger workloads. On what grounds? Here they are:
1) It appears to you, that UV2000 is able to actually startup and successfully finish scale-up workloads.
2) You have examined scale-out clustered HPC workloads on x86 servers from another vendor than SGI.
3) US Postal Service use an SGI UV2000 for in-memory datawarehouse analytics (they also use a real database on disk for storing data).
From these three points you have concluded that UV2000 outperforms and tackles larger scale-up workloads than Unix servers.
.
Are you for real?? What kind of person am I "discussing" with? You are not serious, you are Trolling! Your Troll arguments are more in the line of a child "did too, no did not, did too, no did not!" - instead of presenting serious technical arguments to discuss. I have met eight graders more serious than you.
You say it appears to you that SGI UV2000 can startup and run scale-up workloads, and therefore UV2000 outperforms Unix on scale-up. Well, appearance is not a fact, not hard numbers as benchmarks are, it is just your subjective opinion. Something might appear different to me than you, depending on who look at it. You have pulled this opinion out of a hat, and now present this opinion as a fact. This logic is so faulty that I dont know what to say. There is no way any University would graduate you with this FUBAR logic, much of what you conclude is pure wrong and opinions.
I asked you many times to prove and support your claims by showing benchmarks, otherwise people might believe you are FUDing and lying. But you never backup your claims with benchmarks. For instance, I have counted how many times I have asked you this single question:
-post SAP benchmarks of SGI UV2000 or any other x86 server, beating the best Unix servers.
I have asked you this single question 41 times. Yes, 41 times. And everytime you have ducked it, you have never posted such a benchmark. But still you claim it is true, with no proof. And in addition I have also asked other questions, that you also ducked. I dont think that if I ask you another 41 times, you will suddenly post with holded SAP benchmarks of a x86 server attaining close to a million saps, beating the largest Unix servers. Because there are no such a powerful x86 scale-up server. They dont exist. No matter how much you say so. There are no proof of their existence, no links, no benchmarks, no nothing. They are a fairy tale, living only in your imagination.
The case is clear, I can ask you 10000 times, and you can not prove your false claims about x86 outperforms Unix servers on SAP. Because they are false. In other words, you are FUDing (spreading false information).
If what you say were true; x86 tackles larger SAP workloads than Unix (844.000 saps), then you could prove it by posting x86 benchmarks of 900.000 saps or more. That would be +-10% of a million saps. But you can not post such x86 benchmarks. I can ask you another 41 times, but you will not post any x86 benchmarks beating Unix servers on SAP. They. Dont. Exist.
You have ducked that question 41 times. Instead you reiterate "x86 is in the top 10, and therefore x86 tackles larger SAP workloads than Unix". Well, the best servers are Unix, and there are only a few large Unix servers on the market (SPARC and POWER). These few Unix servers can only grab so many SAP entries.
Of course, Fujitsu could SAP benchmark 32 sockets, 31 sockets, 30 sockets, 29 sockets, etc and grab all 10 top spots. And there would be no way for x86 to stop SPARC grabbing all top 10 spots. Unix can grab top 10 at anytime. x86 can not stop Unix doing that because x86 can not compete with the largest Unix servers in terms of scale-up performance.
Just because x86 has a spot in top 10, does not mean x86 is fast enough to beat the largest Unix servers. It only means that the Unix vendors have chosen not to benchmark all different cpu configurations. It does not mean x86 is faster. Your logic is plain wrong. As usual.
.
To round this off, you have asked me several times what it means that "enterprise business systems have code that branches heavily". SGI explained that in a link I showed you; that as scale-up workloads have heavily branching code SGI will not be able to go into the scale-up enterprise market with their large switch based clusters. This SGI link you rejected because it was several years old. And after that, you kept asking me what does it mean that code branches heavily. This is hilarious. You dont understand SGI's explanation, but you reject it - without understanding what SGI said.
But fear not, I will finally teach you what heavily branching code is. The reason I did not answer earlier is because there are so much to type, an essay. Besides I doubt you will understand, no matter how much I explain as this is quite technical, and you are clearly not technically inclined. You have time and again proved you have very strong opinions of things you dont understand. To a normal person that would be very strange. I would never tell a quantum physicist he is wrong, as I dont know much about quantum physics. But lack of knowledge of quantum physics would not stop you for telling a physicist is wrong, based on your opinions, judging from this discussion. Your lack of comp sci or comp arch knowledge is huge as you have shown many times.
Anyway, here goes. "What does SGI mean when they say that heavily branching code is a problem for scaling up?". Read and learn.
.
For a server to be fast, it needs to have fast RAM, i.e. low latency so it can feed the fast cpus. Fast RAM is very expensive, so typically servers have loads of slow RAM. This slow RAM makes it difficult to feed data to the fast cpus, and most of the time a cpu has to wait for data to process. Intel studies shows that server x86 cpus, under full load, under maximum load, waits for data more than 50% of the time. Let me repeat this; under full load, a x86 server cpu idles >50% of the time as it waits for data to process.
So you have also small (~ 10MB or so) but fast caches that can keep a small portion of the data easy accessible to the CPU, so CPU does not need to wait too long time to get data. If the data is small enough to fit in the cpu cache, all is well and the cpu can process the data quickly. Otherwise, the cpu needs to wait for data to arrive from slow RAM.
C++ game programmers say that typical numbers are 40x slower performance when reaching out to slow RAM. This is on a small PC. I expect the numbers be worse on a large scale-up server with 32 sockets.
http://norvig.com/21-days.html#answers
This is also why C++ game programmers avoid the use of virtual functions (because it will thrash the cache, and performance degrades heavily). Virtual pointers hop around a lot in memory, so the data can not be consecutive, so the cpu always need to jump around in slow RAM. Instead, game programmers tries to fit all data into small vectors that can fit into the cpu cache, so the cpu just can step around in the vector, without ever leaving the vector. All data is located in the vector. This is an ideal situation. If you have loads of data, you can not fit it all into a small cpu cache.
Enteprise business workloads serve many users at the same time, accessing and altering databases, etc. HPC servers are only serving one single user, a scientist that choose what HPC number crunching workload should be run for the next 24 hours.
Say that you serve 153.000 SAP users (the top SAP spot with 844.000 saps serves 153.000 users) at the same time, and all SAP users are doing different things. All these 153.000 SAP users are accessing loads of different data structs, which means all the different user data can not fit into a small cpu cache. Instead, all the user data is strewn everywhere in RAM. The server needs to reach out to slow RAM all the time, as every SAP user does different things with their particular data set. One is doing accounting, someone else is doing sales, one is reaching the database, etc etc.
This means SAP servers serving large number of users, goes out to slow RAM all the time. The workload of all users will never fit into a small cpu cache. Therefore performance degrades 40x or so. This means if you have a 3.6 GHz cpu, it corresponds to a 90 MHz cpu. Here is a developer "Steve Thomas" talking about this in the comments:
http://www.enterprisetech.com/2013/09/22/oracle-li...
"...My benchmarks show me that random access to RAM when you go past the cache size is about 20-30ns on my test system. Maybe faster on a better processor? Sure. Call it 15ns? 15ns = a 66Mhz processor. Remember those?..."
Steve Thomas says that the performance of a 3GHz cpu, deteroiates down to 66MHz cpu when reaching out to slow RAM. Why does it happen? Well, if there are too much user data, so it can not fit into RAM, performance will be 66MHz cpu.
BUT!!! this can also happen if the source code can branche too heavily. In step one, the cpu reads byte 0xaafd3 and in the next step, the cpu reads byte far away, and in the third step the cpu will read another byte very far away. Because the cpu jumps around too much, the source code can not be read in advance into the the small cpu cache. Ideally all source code will lie consecutively in cpu cache (like the data vector I talked about above). In that case, the cpu will read the first byte in the cache and process it, and read the second byte in the cache and process it, etc. There will be no wait, everything is in the cache. If the code branches too heavily, it means the cpu will need to jump around in slow RAM everywhere. This means the cpu cache is not used as intended. In other words, performance degrades 40x. This means a 3.6GHz cpu equals a 90MHz cpu.
Business enteprise systems have source code that branches heavily. One user does accounting, at the same time another user does some sales stuff, and a third user reaches the database, etc. This means the cpu will serve the accounting user and fill the cpu cache with accounting algorithms, and then the cpu will serve the sales person and will empty the cache and fill it with sales stuff source code, etc. And off and on it goes, the cpu will empty and fill the cache all the time with different source code, once for every user, the cpu cache is thrashed. And as we have 153.000 users, the cache will be filled and emptied all the time. And not much work will be done in the cache, instead we will exclusively work in slow RAM all the time. This makes a fast cpu equivalent of a 66MHz cpu. Ergo, heavily branching code SCALES BAD. Just as SGI explained.
OTOH, HPC workloads are number crunching. Typically, you have a very large grid, X and Y and Z coordinates. And each cpu handles say, 100 grid points each. This means a cpu will solve Navier Stokes incompressible differential equations again and again on the same small grid. Everything will fit into the cache, which will never be emptied. The same equation can be run on every point in the grid. It just repeats itself, so it can be optimized. Therefore the cpu can run at full 3.6GHz speed, because everything is fit into the cpu cache. The cache is never emptied. The cache always contains 100 grid points and the equation, which will be applied over and over again. There is not much communication going on between the cpus.
OTOH, enterprise business users never repeat everything, they tend to do different things all the time, calling accounting, sales, book keeping, database, etc functionality. So they are using different functions at the same time, so there is lot of communcation between the cpus, so the perforamcne will degrade to 90MHz cpu. Their workflow can not be optimized as it never repeats. 153.000 users will never do the same thing, you can never optimize their workflow.
Now, the SGI UV2000 has 256 sockets and five(?) layers of many NUMAlink switches. BTW, NUMA means the latency differs between cpus far away and close. This means any NUMA machine is not a true SMP server. So it does not matter how much SGI says UV2000 is a SMP server, it is not SMP because latency differs. SMP server has the same latency to every cpu. So, this is just SGI marketing, as I told you. Google on NUMA and see that latency differs, i.e. any server using NUMA is not SMP. All large Unix servers are NUMA, but they are small and tight - only 32 sockets - so they keep latency low so they can run scale-up workloads. If you keep UV2000 down to a small configuration with few sockets it would be able to run scale-up workloads. But not when you use many cpus because latency grows with the number of switches. If you google, there are actually a 8-socket database benchmark with the UV2000, so there are actually scale-up benchmarks with UV2000, they do exist. SGI have actually benchmarked UV2000 for scale-up, but stopped at 8-sockets. Why not continue benchmarking with 32 sockets, 64 and 256 sockets? Well...
These five layers of switches adds additional latency. And as 15ns cpu latency cache is only able to fully feed a 66 MHz cpu, what do you think the latency of five layered switches gives? If every switch layer takes 15 ns to connect, and you have five layers, the worst case latency will be 5 x 15 = 75 ns. This corresponds to a 13 MHz cpu. Yes, 13 MHz server.
If the code branches heavily, we will exclusively jump around in slow RAM all the time and can never work in the fast cpu cache, and the five layers of switches need to create and destroy connections all the time, yielding a 13 MHz UV2000 server. Now that performance is not suitable for any workload, scale-up or scale-out. Heavily branching code is a PITA, as SGI explained. If you have a larger UV2000 cluster with 2048 cpus you need maybe 10 layers of switches or more, so performance for scale-up workloads will degrade even more. Maybe down to 1MHz cpu. You know the Commodore C64? It had a 1MHz cpu.
(Remember, the UV2000 are used for HPC workloads, that means all the data and source code fits in the cache so the cpu never needs to go out to slow RAM, and can run full speed all the time. So HPC performance will be excellent. If the HPC code is written so to reach slow RAM all the time, performance will degrade heavily down to 13MHz or so. This is why UV2000 are only used for scale-out analytics by USP, and not scale-up workloads)
In short; if code branches heavily, you need to go out to slow RAM and you get a 66 MHz server. If worst case latency of the five layers are in total 15ns, then the UV2000 is equivalent of 66MHz cpus. If worst case latency is 5 x 15 = 75ns, then you have a 13MHz UV2000 server. SAP performacne will be bad in either case. Maybe this is why SGI does not reveal the real latency numbers of SGI UV2000, because then it would be apparent even to non technical people like you, that UV2000 is very very slow when running code that branch heavily. And that is why you will never find UV2000 replacing large Unix servers on scale-up workloads. Just google a bit, and you will find out that SGI does not reveal the UV2000 latency. And this is why SGI does not try to get into enterprise market with UV2000, but instead use the UV300H which has few sockets and therefore low latency.
And how much did I need to type to explain what SGI means with "heavy branching code" to you? This much! There are so much you dont know or fail to understand, no matter how much I explain and show links, so this is a huge waste of time. After a couple of years, I have walked you through a complete B Sc comp sci curriculum. But I dont have the time to school you on this. I should write this much on every question you have, becuase there are so large gaps in your knowledge everywhere. But I will not do that. So I leave you now, to your ignorance. They say that "there are no stupid people, only uninformed". But I dont know in this case. I explain and explain, and show several links to SGI and whatnot, and still you fail to understand despite all information you receive from SGI and me.
I hope at least you have a better understanding now, why a large server with many sockets can not run scale-up workloads, Unix or x86 or whatever. Latency will be too slow, as I have explained all the time, so you will end up with a 66 MHz server. Large scale-up server performance are not about cpu performance, but about I/O. It is very difficult to make a good scale-up server, cpus need to be fast, but I/O need to be evenly good in every aspect in the server, and RAM. You seem to believe that as UV2000 has 256 sockets, it must be faster than 32-socket Unix servers in every aspect. Well, you forgot to consider I/O. To run scale-up workloads, you need to keep the number of sockets low, say 32-sockets. And use superior engineering with a all-to-all topology. Switches will never do.
And one last 42nd question: as you claim that x86 beats largest Unix servers on SAP benchmarks, show us a x86 benchmark. You can't. So you are just some Troll spreading FUD (false information).
(Lastly, it says on the SGI web page that the UV300H goes only to 24TB RAM, and besides, Xeon can maximum adress 1.5TB RAM per cpu in 8-socket configurations. It is a built in hard limit in Xeon. I expect performance of UV300H to deterioate fast when using more than 6-8TB RAM because of scaling inefficencies of x86 architecture. Old mature IBM AIX with 32-socket servers for decades, had severe problems scaling to 8TB RAM, and needed to be rewritten just a few years ago, Solaris as well recently. Windows and Linux needs also to be rewritten if they go into 8TB RAM territory)
BTW, the SGI sales person have stopped emailing me.
Kevin G - Wednesday, June 24, 2015 - link
@BrutalizerI think I’ll start by reposting two questions that you have dodged:
QB) You have asserted that OCC and MVCC techniques use locking to maintain concurrency when they were actually designed to be alternatives to locking for that same purpose. Please demonstrate that OCC and MVCC do indeed use locking as you claim.
QC) Why does the Unix market continue to exist today? Why is the Unix system market shrinking? You indicated that it not because of exclusive features/software, vendor lock-in, cost of porting custom software or RAS support in hardware/software. Performance is being rivaled by x86 systems as they’re generally faster per socket and per core(SAP) and cheaper than Unix systems of similar socket count in business workloads.
“I claim that SGI UV2000 is only used as a HPC cluster, and I claim scale-out servers such as UV2000 can not replace large Unix scale-up servers on business enterprise workloads. Here are my arguments:
1) I have posted several SGI links where SGI CTO and other SGI people, say UV2000 is exclusively for HPC market, and UV300H is for enterprise market.”
First off, this is actually isn’t a technical reason why the UV 2000 couldn’t be used for scale-up workloads.
Secondly, you have not demonstrated that the UV 2000 is a cluster as you have claimed. There is no networking software stack or a required software stack to run a distributed workload on the system. The programmers on a UV 2000 can see all memory and processor cores available. The unified memory and numerous processor sockets are all linked via hardware in a in a cache coherent manner.
And I have posted links where SGI was looking to move the UV 2000 into the enterprise market prior to the UV 300. I’ve also explained why SGI isn’t doing that now with the UV 2000 as the UV 300 has a more uniform latency and nearly the same memory capacity. In most enterprise use-cases, the UV 300 would be more ideal.
“2) SGI has ~50 customers UV2000 use cases on their web site and all are about HPC, such as datawarehouse analytics (US Postal Service). Nowhere on the website do SGI talk about scale-up workloads with UV2000.”
Again, this is actually isn’t a technical reason why the UV 2000 couldn’t be used for scale-up workloads.
The UV 2000 is certified to run Oracle’s database software so it would appear that both SGI and Oracle deem it capable. SAP (with the exception of HANA) is certified to run on the UV 2000 too. (You are also the one that presented this information regarding this.) Similarly it is certified to run MS SQL Server. Those are enterprise, scale up databases.
And the US Postal Service example is a good example of an enterprise workload. Every piece of mail gets scanned in: that is hundreds of millions of pieces of mail every day. These new records are compared to the last several days worth of records to check for fraudulent postage. Postage is time sensitive so extremely old postage gets handled separately as there is likely an issue with delivery (ie flagged as an exception). This logic enables the UV 2000 to do everything in memory due to the system’s massive memory capacity. Data is eventually archived to disk but the working set remains in-memory for performance reasons.
“3) There are no scale-up benchmarks on the whole wide internet, on large UV2000 servers, no SAP benchmarks, no database benchmarks, no nothing.”
Repeating, this is actually isn’t a technical reason why the UV 2000 could not be used for scale-up workloads.
“4) There are no articles or anonymous forum posts on the whole wide internet about any company using UV2000 for scale-up workloads.”
Once again, this is actually isn’t a technical reason why the UV 2000 couldn’t be used for scale-up workloads.
If you were to actually look, there are a couple of forum posts regarding UV 2000’s in the enterprise market. I never considered these forum posts to be exceedingly reliable as there is no means of validating the claims so I have never presented them. I have found references to Pal Pay owning a UV 2000 for fraud detection but I couldn’t find specific details on their implementation.
“5) SGI sales people said UV2000 is only for HPC workloads, in email exchange with me.”
This is appropriate considering point 1 above. Today the niche the UV 2000 occupies a much smaller niche with the launch of the UV 300. The conversation would have been different a year ago before the UV 300 launched.
“6) SAP says in numerous links, that the largest scale-up servers are 32 sockets, SAP never mention 256-socket. SAP talks about the UV300H server, and never mention UV2000. Remember that SAP has close ties to SGI.”
Actually your SGI contact indicated that it was certified for SAP with the exception of HANA. As I’ve pointed out, HAHA only gets certified on Xeon E7 based platforms for production. The UV 2000 uses Xeon E5 class chips.
“And you claim the opposite, that the SGI UV2000 can in fact replace and outperforms large Unix servers on scale-up workloads, and tackle larger workloads. On what grounds? Here they are:”
Actually the main thing I’m attempting to get you to understand is that the UV 2000 is simply a very big scale up server. My main pool of evidence is SGI documentation on the architecture and how it is similar to other well documented large scale up machines. And to counter this you had to state that the 32 socket version of the SPARC M6-32 is a cluster.
I’ve also indicated that companies should use the best tool for the job. There still exists a valid niche for Unix based systems, though you have mocked of them. In fact, you skipped over the question (QC above) of why the Unix market exists today when you ignore the reasons I’ve previously cited. And yes, there are reasons to select a Unix server over a UV 2000 based upon the task at hand but performance is not one of those reasons.
“The case is clear, I can ask you 10000 times, and you can not prove your false claims about x86 outperforms Unix servers on SAP. Because they are false. In other words, you are FUDing (spreading false information).”
Really? What part of the following paragraph I posted previously to answer your original question is actually false:
First off, there is actually no SAP benchmark result of a million or relatively close (+/- 10%) and thus cannot be fulfilled by any platform. The x86 platform has a score in the top 10 out of 792 results posted as of [June 05]. This placement means that it is faster than 783 other submissions, including some (but not all) modern Unix systems (submissions less than 3 years old) with a subset of those having more than 8 sockets. These statements can be verified as fact by sorting by SAP score after going to http://global.sap.com/solutions/benchmark/sd2tier....
The top x86 score for reference is http://download.sap.com/download.epd?context=40E2D...
As for false information, here are a few bits misinformation you have recently spread:
*That the aggregate cross sectional bandwidth of all the M6-32 interconnects is comparable to the uplink bandwidth of a single of the NUMALink6 chip found in the UV 2000.
*Modern Unix systems like the SPARC M6-32 and the POWER8 based E880 only need a single hop to go between sockets when traffic clearly needs up to 3 or 2 hops on each system respectively.
*That a switched fabric for interprocessor communication cannot be used for scaleup workloads despite your example using such a switch for scale up workloads (SPARC M6-32).
*OLTP cannot be done in-memory as a ‘real’ database needs to store data on disk despite there being commercial in-memory databases optimized for OLTP workloads.
*That the OCC or MVCC techniques for concurrency use a traditional locking mechanism.
*That code branching directly affects system scalability when in fact you meant the random access latency across all a system’s unified memory (see below).
*It takes over 35,000 connections to form a mesh topology across 256 sockets when the correct answer is 32,640.
To round this off, you have asked me several times what it means that "enterprise business systems have code that branches heavily". […]
Anyway, here goes. "What does SGI mean when they say that heavily branching code is a problem for scaling up?". Read and learn.[…]
This is exactly what I thought: you are using the wrong terminology for something that does genuinely exist. You have described the performance impact of the random memory access latency across the entire unified memory space. Branching inside of code strictly speaking isn’t necessary to create such a varied memory access pattern to the point that prefetching and caching are not effective. A linked list (https://en.wikipedia.org/wiki/Linked_list ) would be a simple example as traversing it doesn’t require any actual code branches to perform. It does require jumping around in memory as elements in the list don’t necessarily have to be neighbors in memory. On a modern processor, the prefetching logic would loads the data into cache in an attempt to speed up access before it is formally requested by the running code. The result is that the request is served from cache. And yes, if the data isn’t in the cache and a processor has to wait on the memory access, performance does indeed drop rapidly. In the context of increasing socket count, the latency for remote memory access increases, especially if multiple hops between sockets are required. I’ll reiterate that my issue here is not the actual ideas you’ve presented but rather the terms you were using to describe it.
“BUT!!! this can also happen if the source code can branche too heavily. In step one, the cpu reads byte 0xaafd3 and in the next step, the cpu reads byte far away, and in the third step the cpu will read another byte very far away.”
This is the core problem I’ve had with the terminology you have been using. The code for this does not actually need a branch instruction here to do what you are describing. This can be accomplished by several sequential load statements to non-adjacent memory regions. And the opposite can also happen: several nested branches where the code and/or referenced data all reside in the same memory page. There is where your usage of the term code branch leads to confusion.
“Now, the SGI UV2000 has 256 sockets and five(?) layers of many NUMAlink switches. “
It is three layers but five hops in the worst case scenario. Remember you need a hop to enter and exit the topology.
“BTW, NUMA means the latency differs between cpus far away and close. This means any NUMA machine is not a true SMP server. So it does not matter how much SGI says UV2000 is a SMP server, it is not SMP because latency differs. SMP server has the same latency to every cpu. So, this is just SGI marketing, as I told you. Google on NUMA and see that latency differs, i.e. any server using NUMA is not SMP. All large Unix servers are NUMA, but they are small and tight - only 32 sockets - so they keep latency low so they can run scale-up workloads.”
You are flat out contradicting yourself here. If NUMA suffices to run scale up workloads like a classical SMP sign as you claim, then the UV 2000 is a scale up server. Having lower latency and fewer sockets to traverse for remote memory access does indeed help performance but as long as cache coherency is able to maintained, then the system can be seen as one logical device.
“ If you keep UV2000 down to a small configuration with few sockets it would be able to run scale-up workloads.”
Progress! You have finally admitted that the UV 2000 is a scale up system. Victory is mine!
“But not when you use many cpus because latency grows with the number of switches. If you google, there are actually a 8-socket database benchmark with the UV2000, so there are actually scale-up benchmarks with UV2000, they do exist. SGI have actually benchmarked UV2000 for scale-up, but stopped at 8-sockets. Why not continue benchmarking with 32 sockets, 64 and 256 sockets? Well...”
Link please. If you have found them, then why have you been complaining that they don’t exist earlier?
These five layers of switches adds additional latency. And as 15ns cpu latency cache is only able to fully feed a 66 MHz cpu, what do you think the latency of five layered switches gives? If every switch layer takes 15 ns to connect, and you have five layers, the worst case latency will be 5 x 15 = 75 ns. This corresponds to a 13 MHz cpu. Yes, 13 MHz server.
The idea that additional layers add latency is correct but your example figures here are way off. Mainly because you are forgetting to include the actual memory access time. Recent single socket systems are around ~75 ns and up (http://anandtech.com/show/9185/intel-xeon-d-review... ).Thus a single socket system has local memory latency on the same level you are describing from just moving across the interconnect. Xeons E7 and POWER8 will have radically higher local memory access times even on a single socket configuration due to the presence of a memory buffer. Remote memory access latencies are several hundred nanoseconds.
You are also underestimating the effect of caching and prefetching in modern architectures. Cache hit rates have increased over the past 15 years by improving prefetchers, the splitting of L2 into L2 + L3 for multicore systems and increasing the last level cache sizes. I high recommend reading this the following paper as it paints a less dire scenario than you are describing with real actual data that your random forum commenter provided: http://www.pandis.net/resources/cidr07hardavellas....
“In short; if code branches heavily, you need to go out to slow RAM and you get a 66 MHz server. If worst case latency of the five layers are in total 15ns, then the UV2000 is equivalent of 66MHz cpus. If worst case latency is 5 x 15 = 75ns, then you have a 13MHz UV2000 server. SAP performacne will be bad in either case. Maybe this is why SGI does not reveal the real latency numbers of SGI UV2000, because then it would be apparent even to non technical people like you, that UV2000 is very very slow when running code that branch heavily. And that is why you will never find UV2000 replacing large Unix servers on scale-up workloads. Just google a bit, and you will find out that SGI does not reveal the UV2000 latency. And this is why SGI does not try to get into enterprise market with UV2000, but instead use the UV300H which has few sockets and therefore low latency.”
Apparently you never did the searching as I found a paper that actually measured the UV 2000 latencies rather quickly. Note that this is a 64 socket configuration UV 2000 where the maximum number of hops necessary is four (in, two NUMAlink6 switches, out), not five on a 256 socket model. The interesting thing is that despite the latencies presented, they were still able to achieve good scaling with their software. Also noteworthy is that even without the optimized software, the UV 2000 was faster than the other two tested systems even if the other two systems were using optimized software. Of course, with the NUMA optimized software, the UV 2000 was radically faster. Bonus: the workloads tested included an in-memory database.
http://www.adms-conf.org/2014/adms14_kissinger.pdf
For comparison, a 32 socket SPARC M6 needs 150 ns to cross just the Bixby chips. Note that is figure does not include the latency of the actual memory access itself nor the additional latency if a local socket to socket hop is also necessary. Source: (http://www.enterprisetech.com/2014/10/06/ibm-takes... )
While a rough estimate, it would appear that the worst case latency on a UV 2000 is 2.5 to 3 times higher than the worst case latency on a 32 socket SPARC M6 (~100 ns for socket-to-socket hop, 150 ns across the Bixby interconnect and ~120 ns for the actual memory access). This is acceptable in the context that the UV 2000 has sixteen times as many sockets.
(Lastly, it says on the SGI web page that the UV300H goes only to 24TB RAM, and besides, Xeon can maximum adress 1.5TB RAM per cpu in 8-socket configurations. It is a built in hard limit in Xeon. I expect performance of UV300H to deterioate fast when using more than 6-8TB RAM because of scaling inefficencies of x86 architecture.
1.5 TB per socket * 32 sockets = 48 TB
You need 64 GB DIMMs to do it per http://www.theplatform.net/2015/05/01/sgi-awaits-u...
You are providing no basis for the performance deterioration, just an assertion.
“Old mature IBM AIX with 32-socket servers for decades, had severe problems scaling to 8TB RAM, and needed to be rewritten just a few years ago, Solaris as well recently. Windows and Linux needs also to be rewritten if they go into 8TB RAM territory)”
The only recent changes I know of with regards to memory addressing has been operating support for larger page sizes. It is inefficient to use small page sizes for such large amounts of memory due to the sheer number of pages involved. Linux has already been adapted to the large 1 MB page sizes offered by modern x86 systems.
Kevin G - Friday, June 26, 2015 - link
A quick correction:"While a rough estimate, it would appear that the worst case latency on a UV 2000 is 2.5 to 3 times higher than the worst case latency on a 32 socket SPARC M6 (~100 ns for socket-to-socket hop, 150 ns across the Bixby interconnect and ~120 ns for the actual memory access). This is acceptable in the context that the UV 2000 has sixteen times as many sockets."
The UV 2000 has eight times as many sockets as the M6-32. If Oracle were to formally release the 96 socket of the M6, it'd actually be 2.5 times as many sockets.
Kevin G - Monday, August 24, 2015 - link
Well HP has submitted a result for the 16 socket Super Dome X:http://download.sap.com/download.epd?context=40E2D...
A score of 459,580 is ~77% faster than a similarly configured eight socket Xeon E7 v2 getting 259,680:
http://download.sap.com/download.epd?context=40E2D...
Main difference between the systems would be the amount of RAM at 4 TB for the Super Dome X vs. 1 TB for the Fujitsu system.
Overall, the Super Dome X is pretty much where I'd predicted it would be. Scaling isn't linear but a 77% gain is still good for doubling the socket count. Going to 32 sockets with the E7 v2 should net a score around ~800,000 which would be the 3rd fastest on the chart. All HP would need to do is migrate to the E7 v3 chips (which are socket compatible with the E7 v2) and at 32 sockets they could take the top spot with a score just shy of a million.
kgardas - Monday, May 18, 2015 - link
"The best SAP Tier-2 score for x86 is actually 320880 with an 8 socket Xeon E7-8890 v3. Not bad in comparison as the best score is 6417670 for a 40 socket, 640 core SPARC box. In other words, it takes SPARC 5x the sockets and 4.5x the cores to do 2x the work." -- Kevin G. This is not that fair, you are comparing 2 years old SPARC box with just released Xeon E7v3! Anyway still more than one year old SPARC is able to achieve nearly the same number with 32 sockets! The question here is really how it happens that neither IBM with Power nor Intel with Xeon is able to achieve such high number with whatever resources they throw at it.Speaking about Xeon versus Power8, Power8, 8 sockets gets to 436100 SAPS while 8 sockets Xeon E7v3 just to 320880. Here it looks like Power8 is really speedy CPU, cudos to IBM!
Kevin G - Monday, May 18, 2015 - link
@kgardasI consider it a totally fair comparison as Brutalizer was asking for *any* good x86 score as he is in total denial that the x86 platform can be used for such tasks. So I provided one. That's a top 10 ranking one and my note of the top SPARC benchmark requiring 5x the sockets for 2x the work is accurate.
kgardas - Tuesday, May 19, 2015 - link
@Kevin G: this 5x sockets to perform 2x work is not fair. As I told you, in more than one year old system it went to 4x sockets.Anyway, if you analyse SPARC64 pipe-line, than it's clear that you need twice the number of SPARC64 CPUs to perform the same work like Intel. This is a well known weakness of SPARC implementation(s) unfortunately...
Kevin G - Tuesday, May 19, 2015 - link
@kgardasI don't think that that is a inherent to SPARC. It is just that Sun/Oracle never pursued the ultra high single threaded performance like Intel and IBM. Rather they focused on throughput by increasing thread count. With this philosophy, the T series was a surprising success for its targeted workloads.
The one SPARC core that was interesting never saw the light of day: Rock. The idea of out of order instruction retirement seems like a natural evolution from out of order execution. This design could have been the single threaded performance champion that SPARC needed. Delays and trouble validating it insured that it it never made it past prototype silicon. I see the concept of OoO instruction retirement as a feature Intel or IBM will incorporate if they can get a license or the Sun/Oracle patents expire.
kgardas - Tuesday, May 19, 2015 - link
@Kevin G: Yes, true, SPARC is more multi-threaded CPU, but honestly POWER too these days. Look at the pipe-lines. SPARC-Tx/Mx -- just two integer execution units. SPARC64-X, 4 integer units and max 4 isns per cycle. Look at POWER8, *just* two integer execution units! They are talking about 8 or so executions units, but they are just two integer. My bet is they are not shared between threads which means POWER8 is brutally throughput chip. So the only speed-daemon in single-threaded domain remains Intel...Rock? Would like to see it in reality, but Oracle killed that as a first thing after purchase of Sun. Honestly it was also very revolutionary so I'd bet that Sun engineers kind of not been able to handle that. i.e. All Sun's chip were in-order designs and now they not only come with OoO chip, but also that revolutionary. So from this point of view modest OoO design of S3 core looks like very conservative engineering approach.
Kevin G - Tuesday, May 19, 2015 - link
@kgardasPOWER8 can cheat as the load/store and dedicated load units can be assigned simple integer operations to execute. Only complex integer operations (divide etc.) are generally sent to the pure integer units. That's a total of 6 units for simple integer operations.
The tests here does show that single threaded performance on the POWER8 isn't bad but not up to the same level as Haswell. Once you add SMT though, the POWER8 can pull ahead by a good margin. With the ability to issue 10 instructions and dispatch 8 per cycle, writing good code and finding the proper compiler to utilize everything is a challenge.
Rock would have been interesting but by the time it would have reached the market it would have been laughable against Nehalem and crushed against POWER7 a year later. They did have test silicon of the design but it was perpetually stuck in validation for years. Adding OoO execution, OoO retirement, and transactional memory (TSX in Intel speak) would have been a nightmare. Though if Sun got it to work and shipped systems on time in 2006, the high end market place would be very different than it is today.