iPhone 6s and iPhone 6s Plus Preliminary Results
by Joshua Ho on September 28, 2015 8:00 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- PowerVR
- SoCs
- iPhone 6s
- iPhone 6s Plus
- Twister

At this point the iPhone release cycle is pretty well understood. One year, Apple releases the design refresh that changes the external design significantly while generally focusing on evolving the internal components. The year after, the S variant is released with the same design as the previous year, but with sweeping changes to the internals. This cycle of upgrades allows Apple to focus on updating one half of the iPhone at a time while essentially giving their teams a more comfortable two years to develop their next generation technologies.
The iPhone 6s fits into this model quite well, with the introduction of new features like 3D Touch and a 12MP camera that supports 4K video recording. However, it’s often difficult to understand exactly how much has changed with an S model as Apple tends to focus on high level features, this despite the fact that so many of the changes in an S model are at a low level. While I haven’t had a lot of time with the iPhone 6s yet, I wanted to share some of the first results that I’ve acquired over the course of testing the iPhone 6s and 6s Plus in the past few days.

The first, and probably biggest change that I haven’t seen addressed anywhere else yet is the storage solution of the iPhone 6s. Previous writers on the site have often spoken of Apple’s custom NAND controllers for storage in the iPhone, but I didn’t really understand what this really meant. In the case of the iPhone 6s, it seems that this means Apple has effectively taken their Macbook SSD controller and adapted it for use in a smartphone. Doing some digging through system files reveals that the storage solution identifies itself as APPLE SSD AP0128K, while the Macbook we reviewed had an SSD that identified itself as AP0256H.

While the name alone isn’t all that interesting, what is interesting is how this SSD enumerated. One notable difference is that this storage solution uses PCI-E rather than SDIO, so it’s unlikely that this is eMMC. Given the power requirements, it’s likely that this isn’t the same PCI-E as what you’d see in a laptop or desktop, but PCI-E over a MIPI M-PHY physical layer. By comparison, UFS's physical layer is MIPI M-PHY as well, while the protocol is SCSI. In essence, MIPI M-PHY is just a standard that defines the physical characteristics for transmitting signal, but SCSI and PCI-E are ways of determining what to do with that channel.
The iPhone 6s in turn appears to use NVMe, which rules out both UFS and traditional eMMC. To my knowledge, there’s no publicly available mobile storage solution that uses PCI-E and NVMe, so this controller seems to have more in common with the Macbook SSD controller than anything in the mobile space. It doesn’t seem this is an uncommon idea though, as SanDisk detailed the potential advantages of PCIE and NVMe in mobile storage at the Flash Memory Summit a month ago.
| NVMe | eMMC | |
| Latency | 2.8 µs | N/A |
| Maximum Queue Depth | Up to 64K queues with 64K commands each |
Up to 1 queue with 32 commands each |
| Duplex (Typical) | Full | Half |
The controller is a critical part of any storage component, but without any NAND to control it’s a bit pointless. Fortunately, the NAND used appears to be exposed in the OS as it’s referred to as 1Y128G-TLC-2P. Breaking this down, the 1Y means that we’re looking at 1Ynm NAND process with TLC. The TLC portion might concern some, but as we’ll soon see it turns out that we’re looking at a hybrid SLC/TLC NAND solution similar to SanDisk’s iNAND 7232 eMMC and desktop SSDs like Samsung’s 850 EVO which is better suited to the bursty workloads seen in mobile and PC segments. Between the 128GB and 64GB units we currently have, the 64GB unit uses Hynix NAND, but it remains to be seen who is supplying the NAND for the 128GB variants and what other suppliers exist for the 64GB SKUs.
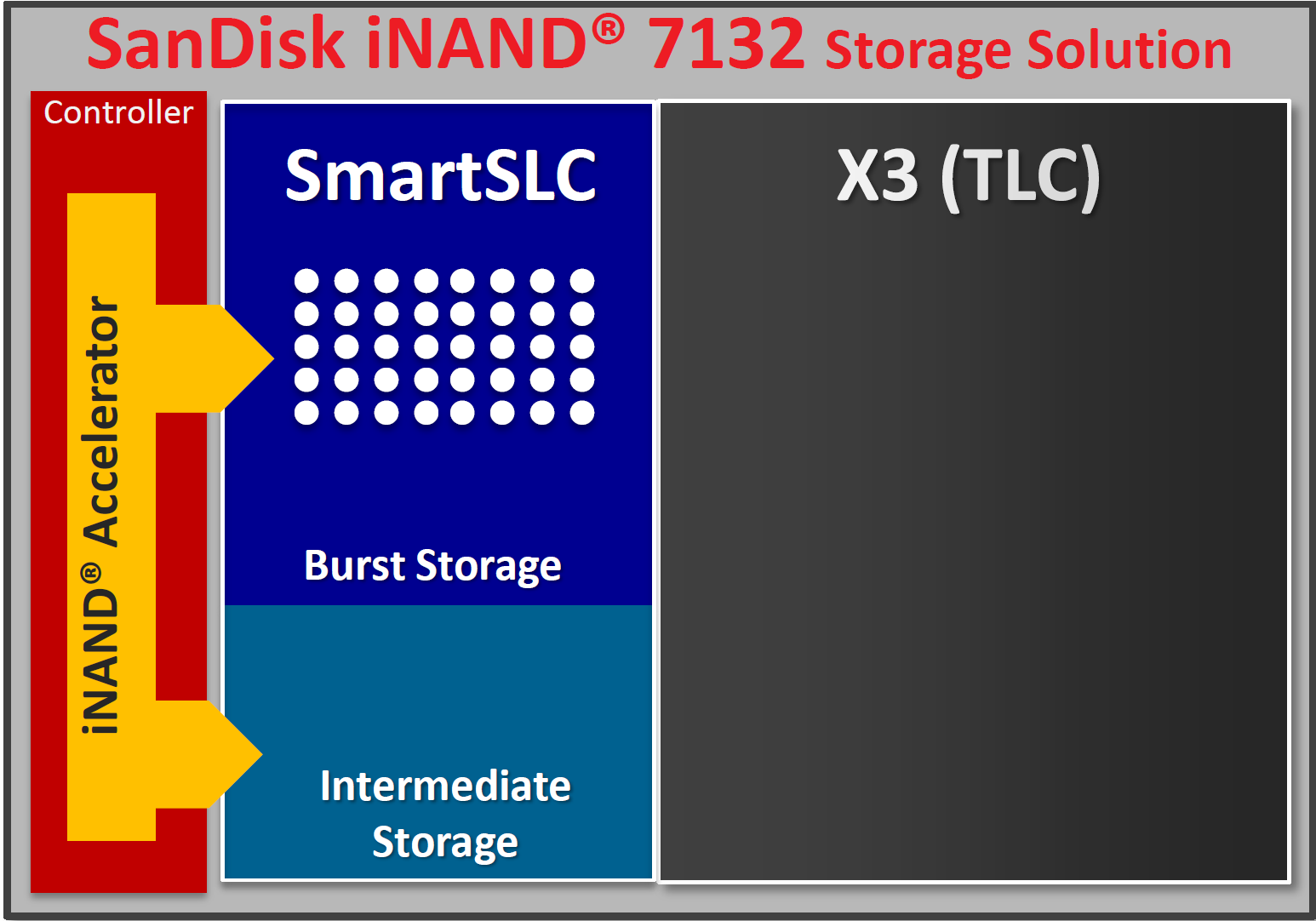
An example of how an SLC/TLC NAND storage device looks in mobile devices
For those that are unfamiliar how these hybrid SLC/TLC NAND solutions work, in essence the SLC cache is made sufficiently large to avoid showing the reduced performance of TLC NAND. Any time you’re writing to the storage, the writes go to the SLC cache first before being committed to TLC NAND. As long as the overall average bandwidth demand doesn’t exceed the speed of the TLC, short-run bandwidth is solely limited by the speed of the SLC cache, which turns out to be the case for almost every normal use case.
In order to see how all of this translates into performance, we once again use StorageBench, which is an app that allows us to do 256K sequential and 4K random storage performance testing developed by Eric Patno and is comparable to AndroBench 3.6.
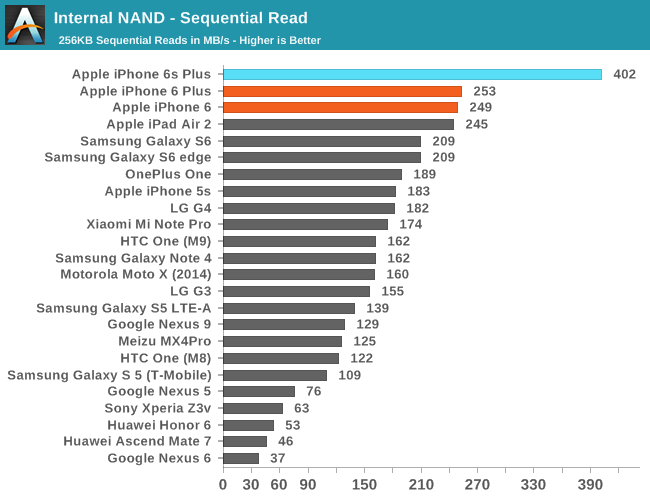
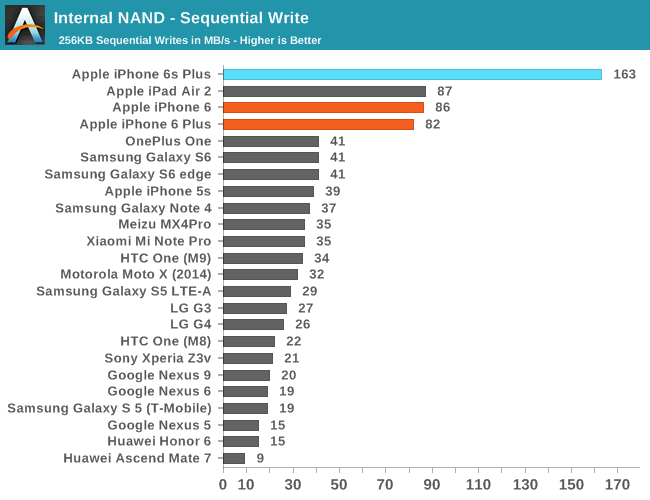
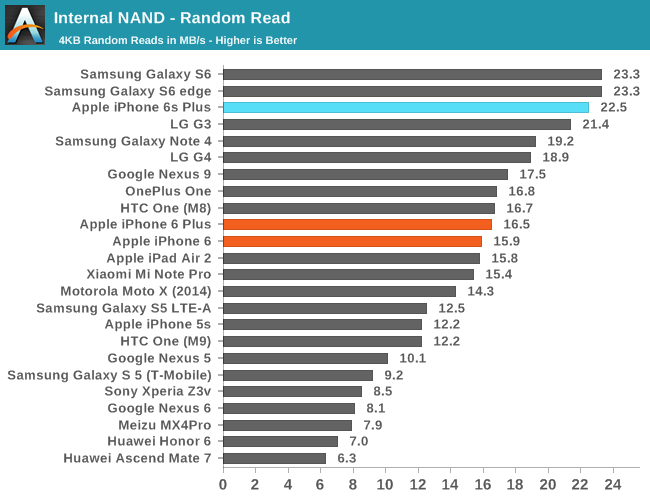
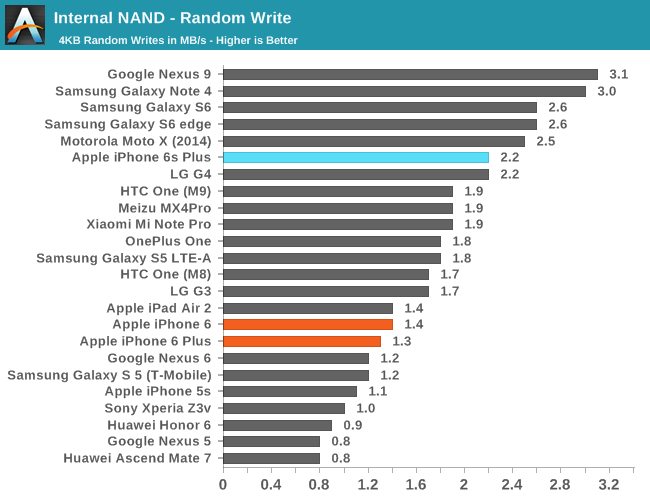
In practice, it seems random IO performance is relatively low, but it’s likely that we’re looking at a bottleneck of the testing methodology as the queue depth of the test is 1 and given PCB size limitations it isn’t reasonable to have as many NAND die working in parallel as we would see in something like a laptop. However, when we look at sequential speeds we can really start to see the strengths of the new storage controller and SLC/TLC. In the interest of seeing the limits of this SLC cache I decided to try running this test over a 5GB span.
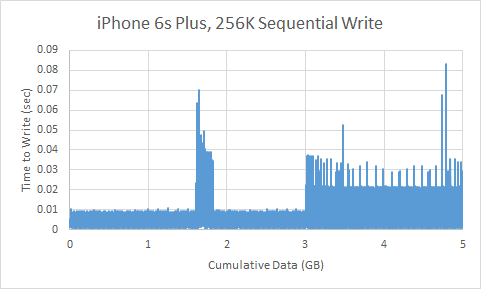
The graph is a bit difficult to interpret, but in effect we’re looking at the time it takes to write 256KB at a time until we get to 5GB. There are two notable spikes roughly around 2GB, but it appears to be small and likely to be some kind of garbage collection or some background work. At 3GB or so the latency increases which suggests that the SLC cache is overrun and write bandwidth is limited by TLC NAND performance.
Overall, NAND performance is impressive, especially in sequential cases. Apple has integrated a mobile storage solution that I haven’t seen in any other device yet, and the results suggest that they’re ahead of just about every other OEM in the industry here by a significant amount.
Storage aside, the SoC itself sees major changes this year. Apple has moved to a FinFET process from either TSMC or Samsung for the A9 SoC. However, it still isn’t clear whether the A9 is single source from one foundry or if A9 is being dual-sourced. Chipworks has reason to believe their iPhone 6s' A9 is fabricated on Samsung's 14nm process, though it hasn't been confirmed yet. Dual-sourcing is well within Apple's capabilities, however TSMC's 16nm and Samsung's 14nm process are not identical - naming aside, different processes developed by different fabs will have different characteristics - so dual-sourcing requires a lot more work to get consistent chips out of both sources. For what it's worth A8 was initially rumored to be dual-sourced as well, but decapping by Chipworks only ever turned up TSMC chips.
Update: Chipworks has since taken apart multiple phones and confirmed that Apple is indeed dual-sourcing; both Samsung and TSMC are supplying chips
Moving on, let's talk about initial performance and battery life measurements, which look promising. Of course, it’s worth noting that the web browser benchmarks we currently have are often optimization targets for OEMs, so web browser benchmarks seen here aren’t necessarily evidence that the browser experience will be performant and smooth across all scenarios.
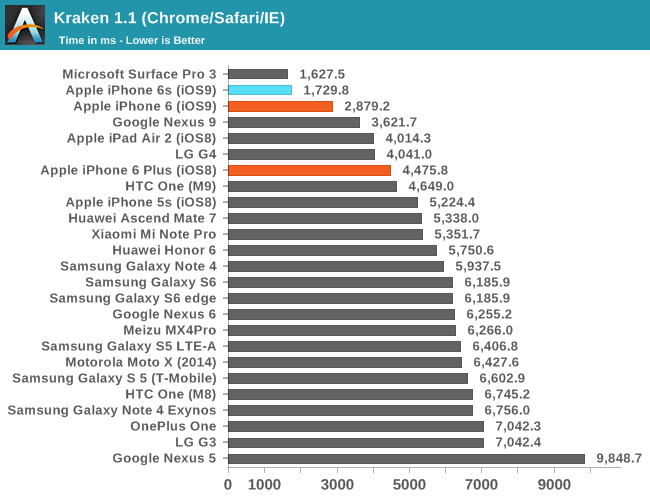
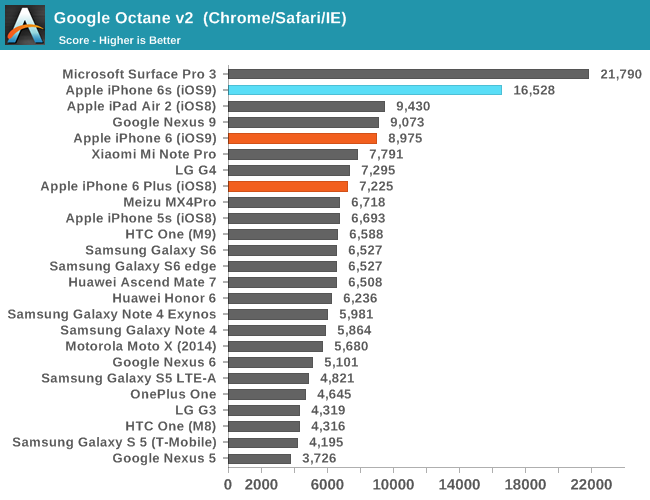
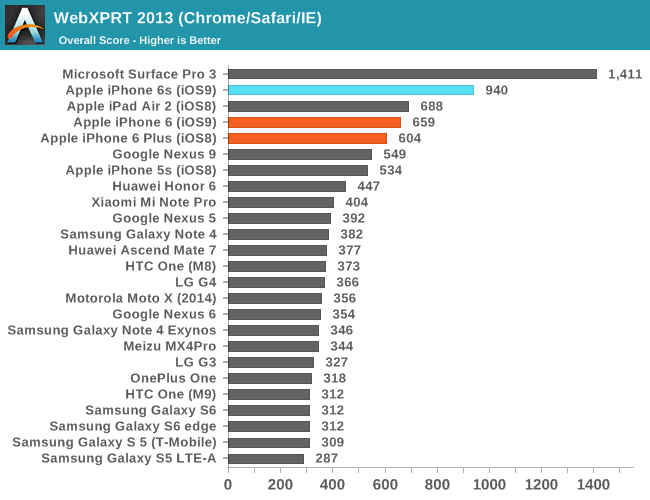
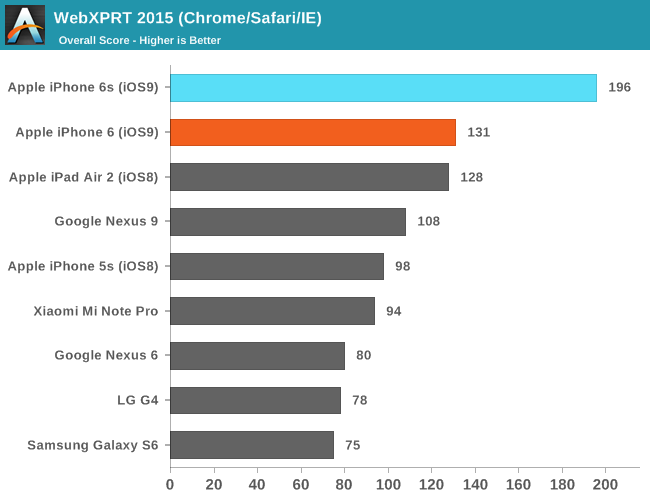
Regardless of whether an OEM is optimizing specifically for these benchmarks, it’s hard to ignore just how well Apple has optimized Safari and the dual core Twister CPUs as they’ve effectively set new records for these benchmarks in mobile. Of course, to try and really figure out the relative performance between CPU architectures when ignoring differences in operating system and developer convention we’ll have to turn to some of our native benchmarks such as SPEC CPU2000, but this will have to wait for the full review. What we can look at are some of our standard benchmarks that test graphics and game-related performance.

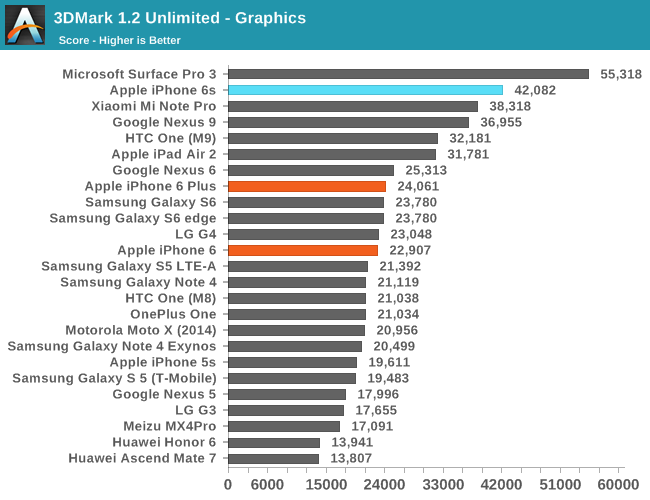
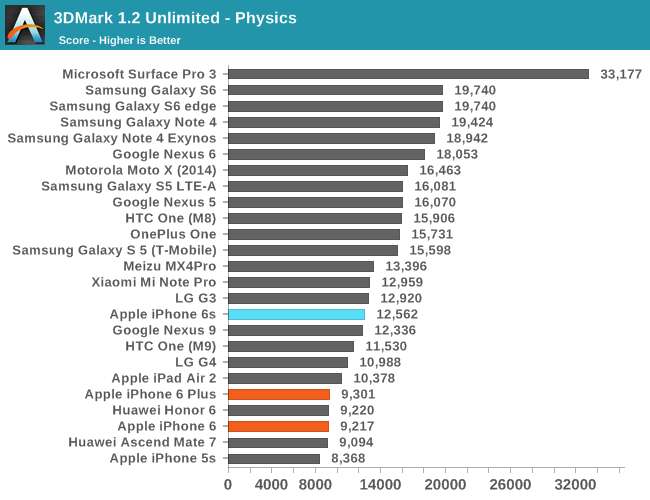
In 3DMark, we see the continuation of a long-running trend in the physics test in which the primary determinant of performance is clock speed and memory performance as data dependencies mean that much of the CPU’s out of order execution assets go unused. However, in graphics we see an enormous improvement, to the extent that the A9’s PowerVR GPU is actually beating the iPad Air’s GXA6850 GPU by a significant margin.
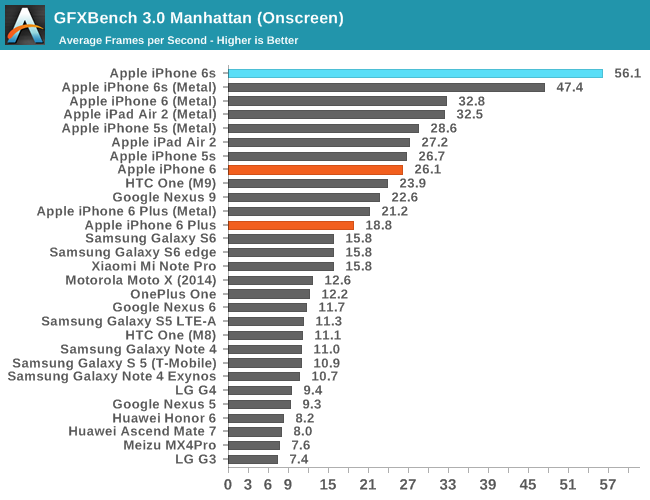
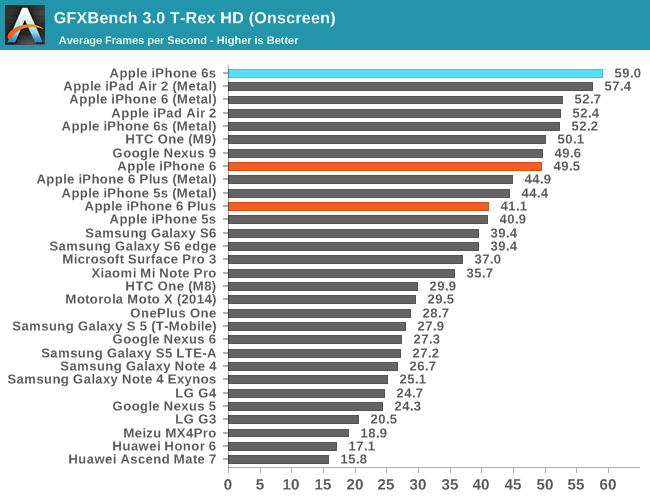
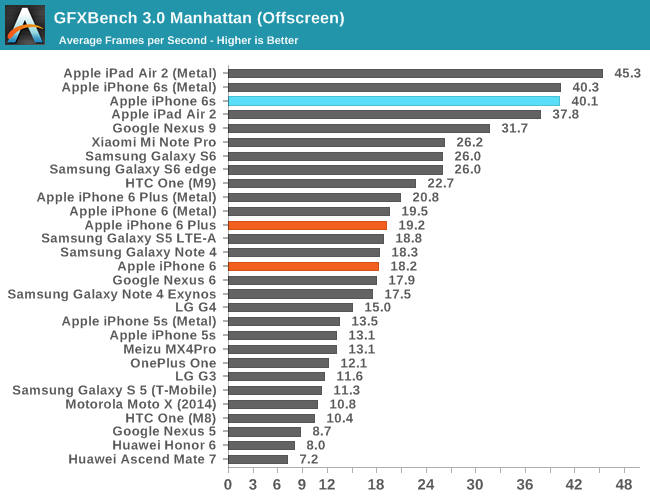
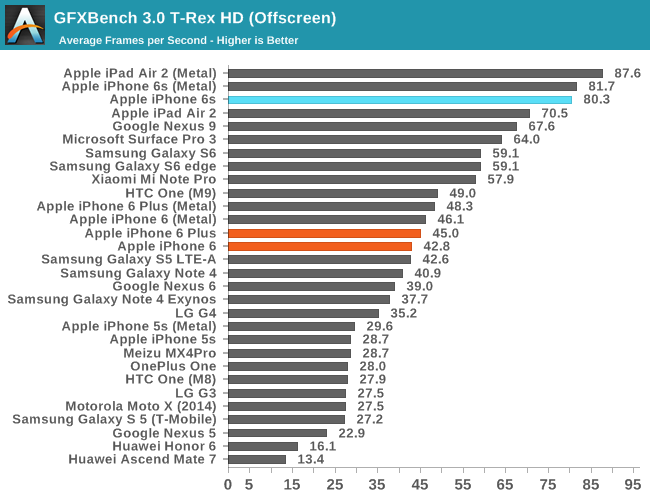
In GFXBench, we see a similar trend which is incredible to think about. Apple has managed to fit a GPU into the iPhone 6s that is more powerful than what was in the iPad Air 2 for OpenGL ES, which is really only possible because of the new process technology that enables much lower power consumption and higher performance.
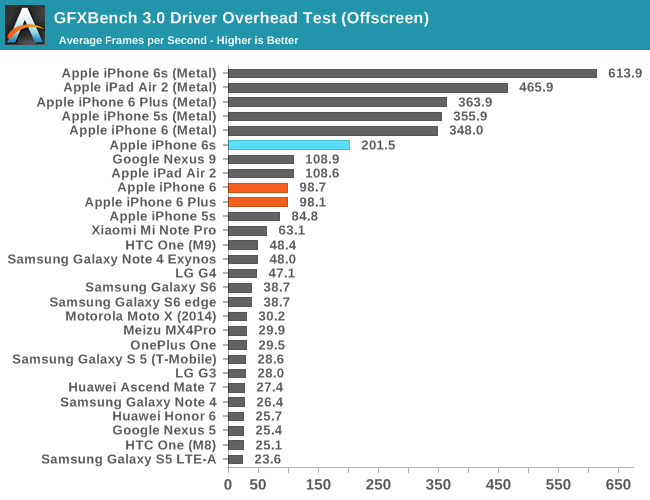
While I don’t normally call attention to most of the GFXBench subtests, in this case I think the driver overhead is worthy of special attention as it highlights one of the real-world benefits that improved CPU performance has. While we often think of CPU and GPU performance as orthogonal, the GPU is fundamentally tied to CPU performance to a certain extent as traditional APIs like OpenGL ES can have significant CPU overhead, especially as GPU performance has grown far faster than CPU performance. For APIs like OpenGL ES, to set up a frame it’s necessary for the CPU to check that the API call is valid, then do any necessary GPU shader or state compilation and begin running code on the GPU at draw time, which incurs increasing overhead as scenes become more complex. Through a combination of efficient drivers and enormous CPU performance, the dual core Twister CPU manages to set a new record for OpenGL ES driver overhead.
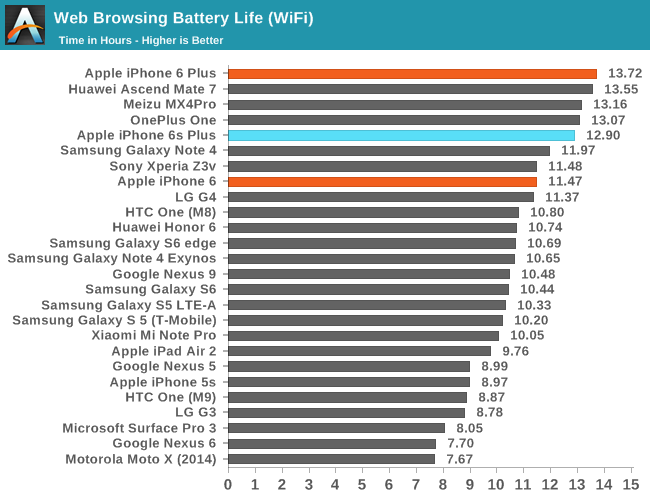
The final piece of data I've been able to collect over the course of the past few days is basic WiFi battery life. For those that are unfamiliar with the changes from the iPhone 6 line to iPhone 6s, the iPhone 6s now has a 1715 mAh (6.517 WHr) battery, and the iPhone 6s Plus has a 2750 mAh (10.45 WHr) battery. Both have a battery about 5.5-6% smaller than the previous generation.
Interestingly, the iPhone 6s Plus appears to actually have accordingly less battery life at 12.9 hours, or right around 6% less than the iPhone 6 Plus. This could be evidence that there haven't been any efficiency improvements to the iPhone 6s line, but given that our testing shows Apple is already at the point where our web browsing test is effectively a pure display rundown it's likely we're looking at the worst-case difference. This warrants additional investigation, but it's possible that a more balanced workload will even out the difference in battery life and maybe even tilt the scales back towards the iPhone 6s depending upon how much load is placed on the SoC.

Overall, while there’s still a great deal of work left to do to exhaustively evaluate the iPhone 6s and 6s Plus, the initial results are quite positive. I haven’t finished a detailed investigation into the architecture of Twister, but I suspect we’re looking at some pretty significant changes compared to Typhoon, which would be unlike the smaller move from Cyclone to Typhoon. The GPU improvements are enormous, and while we don’t have enough data to determine whether the iPhone 6s retains the same sustained GPU performance that we saw in the iPhone 6, the peak performance figures are impressive to say the least. The SSD-like storage solution is also a major surprise, and likely to be overlooked as its effects are often hard to distinguish without direct comparison. Battery life does regress in a single test, but I suspect in real-world situations with less of a focus on the display battery life will either be equal or favor the iPhone 6s, so it will be interesting to see if Apple's battery life estimates remain as accurate as they traditionally have been. We’ve definitely discovered much more about the iPhone 6s than what we’re able to cover in this initial article, so stay tuned for the full review.








185 Comments
View All Comments
tipoo - Monday, September 28, 2015 - link
I read that it was because the hardware encryption on that chip was slower than software, somehow. Not because Android just can't use it yet.name99 - Monday, September 28, 2015 - link
"Twister", huh?I thought this would be a three-cycle micro-architecture going eastward (cyclone, typhoon, hurricane) but they seem to have paused over the Continental US. This in turn suggests that next year's model will be like the three before it, only better in all dimensions, and it will be at least 2017 before we see a truly new micro-architecture.
The most interesting fact about Twister itself seems to be that this was the CPU for which they decided to improve the uncore. Look here (comparing iPhone6S to the best retina Macbook score on the site)
https://browser.primatelabs.com/geekbench3/compare...
The point of interest (IMHO) is how close to identical all the memory scores are, and likewise the memory dependent benchmarks (things like the FFTs and blur/sharpen).
Time was (like as recently as a month ago) that people were saying Intel's great strength was their uncore --- other people might put together a great core, but only Intel had the expertise in the memory controller and the cache management algorithms to get the data flowing optimally all the way from RAM to registers. Not so much anymore...
The one place Intel probably is still substantially ahead of Apple is in tech related to coherence and consistency for many cores, the sort of stuff needed to make an 18 core Xeon work well. I'm guessing Apple won't have much incentive to push in that particular direction until they ship their SoC for the Mac Pro...
One final point. I'm not convinced that 3Dmark Physics is purely a test of frequency as you suggest; I think there is more going on here. Compare, for example, the Surface Pro 3 to Samsung and iPhone 6S numbers.
My current hypothesis is that this matches something else we have observed, that Apple SoC seem to have high L2 and L3 latencies. It is possible to design a cache that is segmented into differently behaving portions. A simple example would be a follows: Suppose your cache has 8 ways. You put two ways in the A (fast) sector and 6 in the B (slow) sector. Every L1 miss FIRST probes the A sector and only on an A miss probes the B sector (which is a drowsy cache). A hits are fast, B hits require at least one more cycle to probe the extra ways, then an additional cycle or two to wake up the drowsy line (and that line is then swapped with an A sector line).
Cache designs like this have to been modeled to save 40 to 80% power, at the cost of 2 to 5% performance, which seems like a good tradeoff. (I don't know if anyone has implemented one, but Intel implemented something like this for the Ivy Bridge L3, where the B partition was, I think, not drowsy but simply shut down.)
In essence this is an implementation of the L1 idea of way prediction applied to L2 or L3 in a way that makes sense in those contexts.
The one place they expose a glass jaw is in code that more or less randomly bounces around the address space --- stuff like L2 latency testers and (as far as I can tell) 3dmark Physics --- where the heuristics for what to put in the A vs B partition and when to swap them fail.
There are ways to make this more sophisticated. You can dynamically change the size of the partitions so that if your entire L2 or L3 is being used aggressively you make everything A sector. (This is essentially what Ivy Bridge does, swapping between use of the entire L3 and use of a smaller A partition dynamically). You can have the A partition be one way in size, or two ways, or four ways, or the full eight ways. I don't think Apple is dynamically sizing the cache yet --- if they were, then the latency and Physics numbers would show the latency for just the A partition and be somewhat improved.
You can also add a third state of dead-line prediction and (to save power further) just drop dead lines in the B-partition. It's possible that Apple is already doing this; if not it's one more thing that can be added for the future.
There are also other tricks available to make L2 that much more performant. One that is simple enough that I am guessing Intel and Apple already use is to mark I-lines in the L2 as higher priority than D-lines because the CPU hurts more when it misses in L1-I than when it misses in L1-D. The standard algorithm for this is called Code Line Preservation (CLIP).
To summarize, I think Apple have made the right choice with the cache here. It obviously can be shown to be slower than a traditional cache if tested in exactly the right way, but for "normal" code it seems to be every bit as fast as the simulations show it should be, while reducing power substantially, which then allows more power for things like branch prediction and 6-wide OoO.
tipoo - Monday, September 28, 2015 - link
Yeah, I thought the core count/frequency explanation for the physics scores never really made sense. The A8X with three cores didn't improve it as much as you would think it would given 50% more cores, whereas Android phones seemed to happily scale on it. So there must be something else going on in the SoC design. Interesting theory about caches.WoodyPWX - Monday, September 28, 2015 - link
Any chance you can compare iP6s+ with Note 5?Shalmanese - Monday, September 28, 2015 - link
So one of the big arguments people make towards moving to 2Gb of RAM is so that Safari pages don't refresh from the web when you go back to a previous tab. But desktop Safari users never encounter this problem, no matter how little RAM they have, because Safari caches tabs to disk when it runs out of memory.I get why the iPhone 2G decided not to implement swap files with it's abysmal I/O performance and limited write cycles. But this latest generation of phones is apparently using something close to a desktop SSD solution and yet iOS still has hard Out of Memory errors rather than introducing swap. Is there a reason at this point why iOS doesn't just mimic desktop OS behavior with regards to memory?
amonduin - Monday, September 28, 2015 - link
I think there are probably two reasons for this.1. Even though storage IO has gotten much quicker it is still quite a lot slower than lpddr4 memory access and so allowing apps to use swap memory for their data would likely (in Apple's mind) lead to a degraded user experience.
2. Limited storage. Many Apple products are still limited to only 16 GB of internal storage and filling it with swapped memory data could fill it up rather quickly. This second issue is one which they should have alleviated by now with larger base storage classes but apparently the money is too good to pass up.
name99 - Monday, September 28, 2015 - link
iOS provides a paging infrastructure. Code is paged in, and memory mapped files are supported (and encouraged by Apple as the best way to access files).What is NOT supported is demand paged writes. I suspect this is because of either the power cost (flash writes are expensive in power) or the jerkiness this might add to the UI.
This seems to be the common consensus for mobile OS's. Android and Win Mobile make exactly the same policy choices.
Of course if Apple can switch to some alternative to Flash in future iOS devices, the tradeoffs will differ, and at that point swapping might become a sensible choice.
tuxRoller - Monday, September 28, 2015 - link
And this is why all the other phone oems area behind Apple. They are proactive in their improvement attempts instead of adding halfbaked software and calling it a day. Samsung has the expertise to provide the fastest, bar none, phone storage solution, but no, better to be conservative and copy Apple.Apple, first to: high dpi screens, desktop class single core performance, reliable fingerprint scanner (speaking of, where the hell are those amazing Qualcomm fingerprint scanner that can fit on the screen?), desktop class storage performance.
I'm still not going to buy an Apple product but this is getting to be ridiculous. With all of the various Android manufacturers you'd think at least one would produce something as good as Apple's hardware.
tempestglen - Monday, September 28, 2015 - link
please run SPEC06 because A9 is a desktop class cpu and with 2G ram.tuxRoller - Tuesday, September 29, 2015 - link
Sure. Get me a device with an a9 soc and a copy of spec06 that will run on it.I'll give you my address later.