Intel’s Tiger Lake 11th Gen Core i7-1185G7 Review and Deep Dive: Baskin’ for the Exotic
by Dr. Ian Cutress & Andrei Frumusanu on September 17, 2020 9:35 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Tiger Lake
- Xe-LP
- Willow Cove
- SuperFin
- 11th Gen
- i7-1185G7
- Tiger King
CPU Performance: Simulation and Science
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
I reached out to the author of the software, who has added in several features to make the software conducive to benchmarking. The software comes with a series of batch files for testing, and we run the ‘small 64-bit nogui’ version with a modified command line to allow for ‘benchmark warmup’ and then perform the actual testing.
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected.
We also have an additional flag on the software to make the benchmark exit when complete (which is not default behavior). The final results are output into a predefined file, which can be parsed for the result. The number of interest for us is the ability to simulate this system in real-time, and results are given as a factor of this: hardware that can simulate double real-time is given the value of 2.0, for example.
The final result is a table that looks like this:
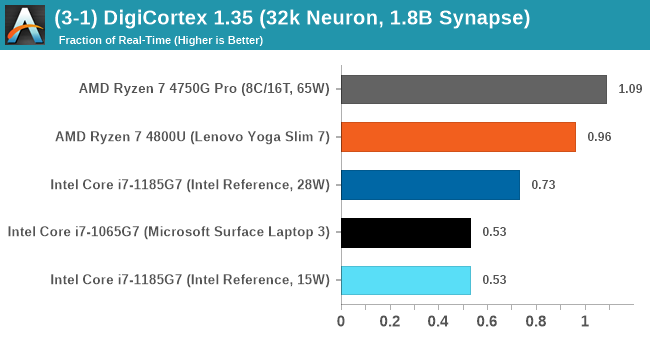
DigiCortex likes the 8-core AMD processors, but doesn't seem to like the LPDDR4 memory over the standard DDR4.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. We’ve tested a large world generation scenario:
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the large test for as many times in an hour.
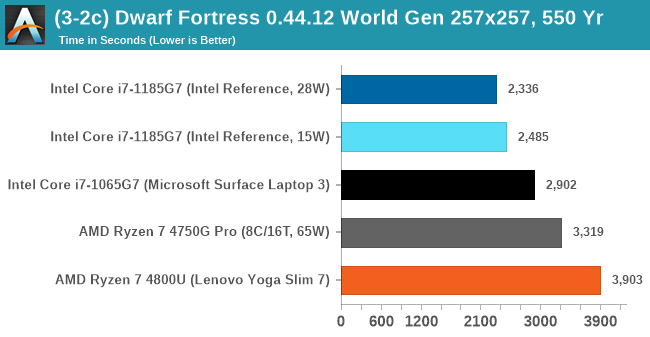
Intel's hardware likes Dwarf Fortress. It is primarily single threaded, and so a high IPC and a high frequency is what matters here.
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.
The Dolphin software has the ability to output a log, and we obtained a version of the benchmark from a Dolphin developer that outputs the display into that log file. The benchmark when finished will automatically try to close the Dolphin software (which is not normal behavior) and brings a pop-up on display to confirm, which our benchmark script can detects and remove. The log file is fairly verbose, so the benchmark script iterates through line-by-line looking for a regex match in line with the final time to complete.
The final result is a table that looks like this:
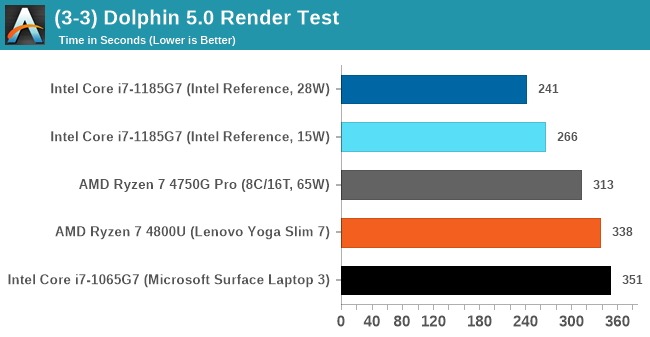
More often than not Intel's processors are the ones to choose for this sort of emulation - AMD catched up with Zen 2, but it would appear that Tiger Lake makes another leap forward.
CPU Tests: Science
In this version of our test suite, all the science focused tests that aren’t ‘simulation’ work are now in our science section. This includes Brownian Motion, calculating digits of Pi, molecular dynamics, and for the first time, we’re trialing an artificial intelligence benchmark, both inference and training, that works under Windows using python and TensorFlow. Where possible these benchmarks have been optimized with the latest in vector instructions, except for the AI test – we were told that while it uses Intel’s Math Kernel Libraries, they’re optimized more for Linux than for Windows, and so it gives an interesting result when unoptimized software is used.
3D Particle Movement v2.1: Non-AVX and AVX2/AVX512
This is the latest version of the benchmark designed to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. This involves randomly moving particles in a 3D space using a set of algorithms that define random movement. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in.
The initial version of v2.1 is a custom C++ binary of my own code, flags are in place to allow for multiple loops of the code with a custom benchmark length. By default this version runs six times and outputs the average score to the console, which we capture with a redirection operator that writes to file.
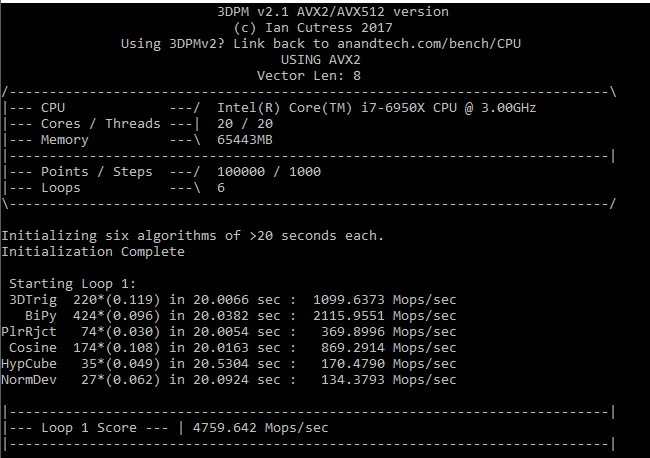
For v2.1, we also have a fully optimized AVX2/AVX512 version, which uses intrinsics to get the best performance out of the software. This was done by a former Intel AVX-512 engineer who now works elsewhere. According to Jim Keller, there are only a couple dozen or so people who understand how to extract the best performance out of a CPU, and this guy is one of them. To keep things honest, AMD also has a copy of the code, but has not proposed any changes.
The final result is a table that looks like this:
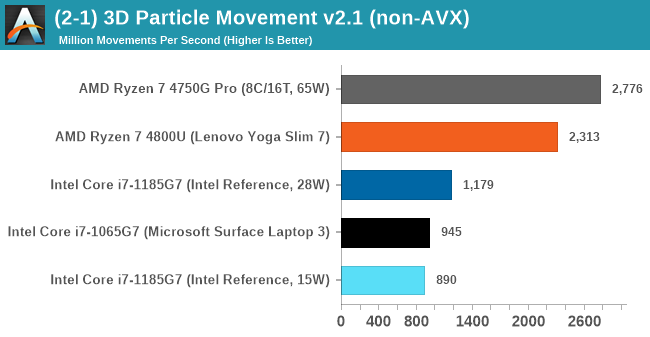
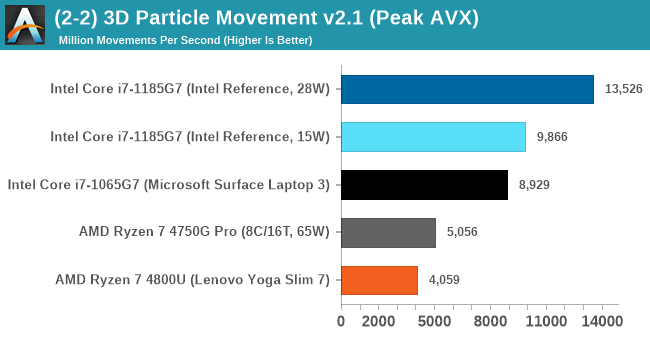
For the non-AVX compute, the eight cores of the AMD processors are ahead, however AVX-512 is a powerful tool in the right hands, with the 1185G7 offering 2x-3x performance for the same power than AMD.
y-Cruncher 0.78.9506: www.numberworld.org/y-cruncher
If you ask anyone what sort of computer holds the world record for calculating the most digits of pi, I can guarantee that a good portion of those answers might point to some colossus super computer built into a mountain by a super-villain. Fortunately nothing could be further from the truth – the computer with the record is a quad socket Ivy Bridge server with 300 TB of storage. The software that was run to get that was y-cruncher.
Built by Alex Yee over the last part of a decade and some more, y-Cruncher is the software of choice for calculating billions and trillions of digits of the most popular mathematical constants. The software has held the world record for Pi since August 2010, and has broken the record a total of 7 times since. It also holds records for e, the Golden Ratio, and others. According to Alex, the program runs around 500,000 lines of code, and he has multiple binaries each optimized for different families of processors, such as Zen, Ice Lake, Sky Lake, all the way back to Nehalem, using the latest SSE/AVX2/AVX512 instructions where they fit in, and then further optimized for how each core is built.
For our purposes, we’re calculating Pi, as it is more compute bound than memory bound.
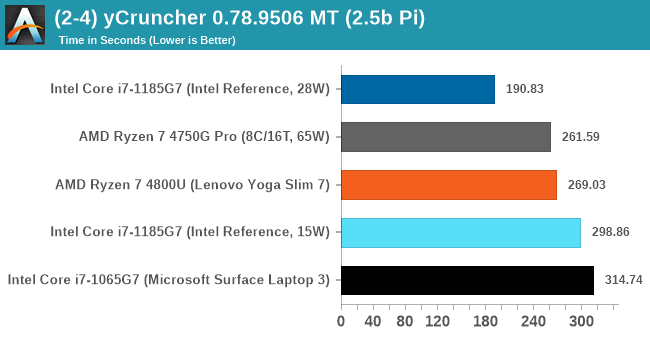
y-Cruncher takes advantage of the extra power available in the 28 W TDP mode, utilizing AVX-512 better than AMD can do with eight cores on AVX2 at 65 W.
NAMD 2.13 (ApoA1): Molecular Dynamics
One of the popular science fields is modelling the dynamics of proteins. By looking at how the energy of active sites within a large protein structure over time, scientists behind the research can calculate required activation energies for potential interactions. This becomes very important in drug discovery. Molecular dynamics also plays a large role in protein folding, and in understanding what happens when proteins misfold, and what can be done to prevent it. Two of the most popular molecular dynamics packages in use today are NAMD and GROMACS.
NAMD, or Nanoscale Molecular Dynamics, has already been used in extensive Coronavirus research on the Frontier supercomputer. Typical simulations using the package are measured in how many nanoseconds per day can be calculated with the given hardware, and the ApoA1 protein (92,224 atoms) has been the standard model for molecular dynamics simulation.
Luckily the compute can home in on a typical ‘nanoseconds-per-day’ rate after only 60 seconds of simulation, however we stretch that out to 10 minutes to take a more sustained value, as by that time most turbo limits should be surpassed. The simulation itself works with 2 femtosecond timesteps.
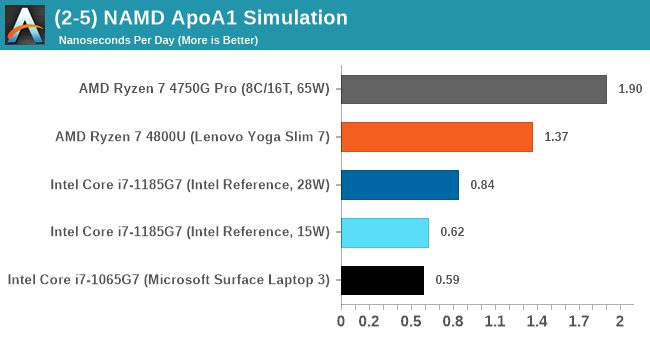
NAMD scales well with cores.
AI Benchmark 0.1.2 using TensorFlow: Link
Finding an appropriate artificial intelligence benchmark for Windows has been a holy grail of mine for quite a while. The problem is that AI is such a fast moving, fast paced word that whatever I compute this quarter will no longer be relevant in the next, and one of the key metrics in this benchmarking suite is being able to keep data over a long period of time. We’ve had AI benchmarks on smartphones for a while, given that smartphones are a better target for AI workloads, but it also makes some sense that everything on PC is geared towards Linux as well.
Thankfully however, the good folks over at ETH Zurich in Switzerland have converted their smartphone AI benchmark into something that’s useable in Windows. It uses TensorFlow, and for our benchmark purposes we’ve locked our testing down to TensorFlow 2.10, AI Benchmark 0.1.2, while using Python 3.7.6 – this was the only combination of versions we could get to work, because Python 3.8 has some quirks.

The benchmark runs through 19 different networks including MobileNet-V2, ResNet-V2, VGG-19 Super-Res, NVIDIA-SPADE, PSPNet, DeepLab, Pixel-RNN, and GNMT-Translation. All the tests probe both the inference and the training at various input sizes and batch sizes, except the translation that only does inference. It measures the time taken to do a given amount of work, and spits out a value at the end.
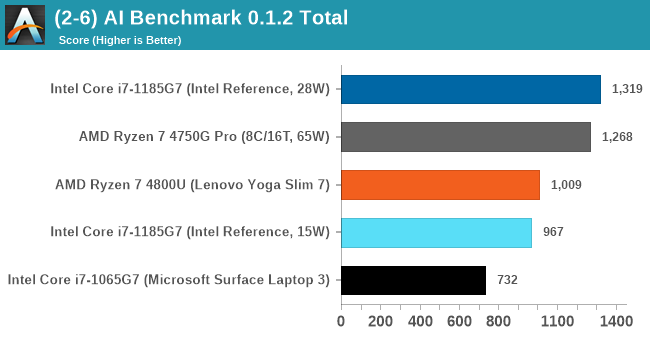
Intel currently has the easier tools for AI acceleration, and the developers here use the Intel Math Kernel Libraries. These libraries aren't to fond of scaling in windows compared to Linux, but we still see a sizeable uplift for Tiger Lake from Ice Lake.








253 Comments
View All Comments
tipoo - Thursday, September 17, 2020 - link
“Baskin for the exotic”I see what you did there...
ingwe - Thursday, September 17, 2020 - link
I didn't get it until I read your comment.Luminar - Thursday, September 17, 2020 - link
RIP AMDAMDSuperFan - Thursday, September 17, 2020 - link
"Against the x86 competition, Tiger Lake leaves AMD’s Zen2-based Renoir in the dust when it comes to single-threaded performance." - But I am hoping Big Navi can compete well against this Intel chip.tipoo - Thursday, September 17, 2020 - link
What does Big Navi have to do with a laptop CPU?AMDSuperFan - Thursday, September 17, 2020 - link
You care about games don't you? This Intel Tiger won't have an answer for Big Navi. We can look forward to that showing who is the boss.blppt - Thursday, September 17, 2020 - link
Based on preliminary data, they'll both be about 2 years behind Nvidia, what with Big Navi only matching a 2080ti, and not available for another month at the earliest.hecksagon - Friday, September 18, 2020 - link
Crazy how you can make that prediction, the only preliminary data that is out is a photograph of the card. Are you a wizard?blppt - Friday, September 18, 2020 - link
Incorrect.https://wccftech.com/amd-radeon-navi-gpu-specs-per...
HarryVoyager - Friday, September 18, 2020 - link
I'm not really seeing where you are getting that from. We know that RDNA2 can hit 2.23Ghz from the PS5 implementation, and we have solid rumors that it the top end one will be an 80CU chip, rather than a 40 CU chip. That implies on the order of a 230% improvement over the 5700XT, if their are no other performance improvements. That alone puts it in the 30-40% improvement range over the 2080 Ti. Given we've already seen at least a few AMD benchmarks of unidentified cards showing a 30-40% improvement over 2080 To performance, that sort of lift does seem likely.If I had to guess, that RDNA2 that recently showed up with a near 2080 TI performance is probably a 6700 competitor to the 3070, not the top end card. Those do have to be developed and tested too, after all.