No more mysteries: Apple's G5 versus x86, Mac OS X versus Linux
by Johan De Gelas on June 3, 2005 7:48 AM EST- Posted in
- Mac
IBM PowerPC 970FX: Superscalar monster
Meet the G5 processor, which is in fact IBM's PowerPC 970FX processor. The RISC ISA, which is quite complex and can hardly be called "Reduced" (The R of RISC), provides 32 architectural registers. Architectural registers are the registers that are visible to the programmer, mostly the compiler programmer. These are the registers that can be used to program the calculations in the binary (and assembler) code.
The 970FX is deeply pipelined, quite a bit deeper than the Athlon 64 or Opteron. While the Opteron has a 12 stage pipeline for integer calculations, the 970FX goes deeper and ends up with 16 stages. Floating point is handled through 21 stages, and the Opteron only needs 17. 21 stages might make you think that the 970FX is close to a Pentium 4 Northwood, but you should remember that the Pentium 4 also had 8 stages in front of the trace cache. The 20 stages were counted from the trace cache. So, the Pentium 4 has to do less work in those 20 stages than what the 970FX performs in those 16 or 21 stages. When it comes to branch prediction penalties, the 970FX penalty will be closer to the Pentium 4 (Northwood). But when it comes to frequency headroom, the 970FX should do - in theory - better than the Opteron, but does not come close to the "old" Pentium 4.
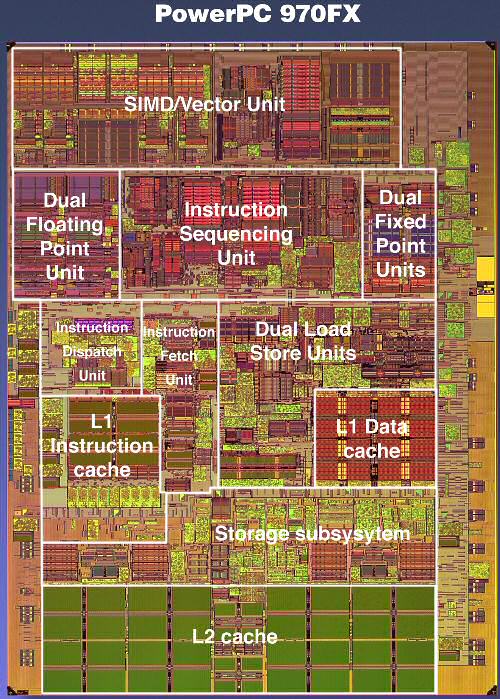
The 970FX works out of order and up to 200 instructions can be kept in flight, compared to 126 in the Pentium 4. The rate at which instructions are fetched will not limit the issue rate either. The PowerPC 970 FX fetches up to 8 instructions per cycle from the L1 and can decode at the same rate of 8 instructions per cycle. So, is the 970FX the ultimate out-of-order CPU?
While 200 instructions in flight are impressive, there is a catch. If there was no limitation except die size, CPUs would probably keep thousands of instructions in flight. However, the scheduler has to be able to pick out independent instructions (instructions that do not rely on the outcome of a previous one) out of those buffers. And searching and analysing the buffers takes time, and time is very limited at clock speeds of 2.5 GHz and more. Although it is true that the bigger the buffers, the better, the number of instructions that can be tracked and analysed per clock cycle is very limited. The buffer in front of the execution units is about 100 instructions big, still respectable compared to the Athlon 64's reorder buffer of 72 instructions, divided into 24 groups of 3 instructions.
The same grouping also happens on the 970FX or G5. But the grouping is a little coarser here, with 5 instructions in one group. This grouping makes reordering and tracking a little easier than when the scheduler would have to deal with 100 separate instructions.
The grouping is, at the same time, one of the biggest disadvantages. Yes, the Itanium also works with groups, but there the compilers should help the CPU with getting the slots filled. In the 970FX, the group must be assembled with pretty strict limitations, such as at one branch per group. Many other restrictions apply, but that is outside the scope of this article. Suffice it to say that it happens quite a lot that a few of the operations in the group consist of NOOP, no-operation, or useless "do nothing" instructions. Or that a group cannot be issued because some of the resources that one member of the group needs is not available ( registers, execution slots). You could say that the whole grouping thing makes the Superscalar monster less flexible.
Branch prediction is done by two different methods each with a gigantic 16K entry history table. A third "selector" keeps another 16K history to see which of the two methods has done the best job so far. Branch prediction seems to be a prime concern for the IBM designers.
Memory Subsystem
The caches are relatively small compared to the x86 competition. A 64 KB I-cache and 32 KB D-cache is relatively "normal", while the 512 KB L2-cache is a little small by today's standards. But, no complaints here. A real complaint can be lodged against the latency to the memory. Apple's own webpage talks about 135 ns access time to the RAM. Now, compare this to the 60 ns access time that the Opteron needs to access the RAM, and about 100-115 ns in the case of the Pentium 4 (with 875 chipset).A quick test with LM bench 2.04 confirms this:
| Host | OS | Mem read (MB/s) | Mem write (MB/s) | L2-cache latency (ns) | RAM Random Access (ns) |
| Xeon 3.06 GHz | Linux 2.4 | 1937 | 990 | 59.940 | 152.7 |
| G5 2.7 GHz | Darwin 8.1 | 2799 | 1575 | 49.190 | 303.4 |
| Xeon 3.6 GHz | Linux 2.6 | 3881 | 1669 | 78.380 | 153.4 |
| Opteron 850 | Linux 2.6 | 1920 | 1468 | 50.530 | 133.2 |
Memory latency is definitely a problem on the G5.
On the flipside of the coin is the excellent FSB bandwidth. The G5/Power PC 970FX 2.7 GHz has a 1.35 GHz FSB (Full Duplex), capable of sending 10.8 GB/s in each direction. Of course, the (half duplex) dual channel DDR400 bus can only use 6.4 GB/s at most. Still, all this bandwidth can be put to good use with up to 8 data prefetch streams.








116 Comments
View All Comments
edchi - Tuesday, June 26, 2007 - link
I haven't tried this yet, but will do tomorrow. Here is what Apple suggests to create a better MySQL installation:
http://docs.info.apple.com/article.html?artnum=303...">http://docs.info.apple.com/article.html?artnum=303...
grantma - Tuesday, April 18, 2006 - link
I found Gnome was a lot more snappy than OS X desktop under Debian PowerPC. You could tell the kernel was far faster using Linux 2.6 - programs would just start immediately.heaneyforestrntpe68 - Thursday, October 21, 2021 - link
At least the non-ECC RAM, that is. https://bit.ly/2XwdzPtpecosbill - Wednesday, June 15, 2005 - link
I'm not going to waste my time searching to see if these same comments below were made already, but the summary of them is those who are performance oriented tune their code for a CPU. You can do the same for an OS. Also, the "Big Mac" cluster in VA tech speaks otherwise to raw performance as OS X was the OS of choice. From macintouch.com:Okay, stop, I have to make an argument about why this article fails, before I explode. MySQL has a disgusting tendency to fork() at random moments, which is bad for performance essentially everywhere but Linux. OS X server includes a version of MySQL that doesn't have this issue.
No real arguments that Power Macs are somewhat behind the times on memory latency, but that's because they're still using PC3200 DDR1 memory from 2003. AMD/Intel chips use DDR2 or Rambus now ... this could be solved without switching CPUs.
The article also goes out of its way to get bad results for PPC. Why are they using an old version of GCC (3.3.x has no autovectorization, much worse performance on non-x86 platforms), then a brand spanking new version of mySQL (see above)? The floating point benchmark was particularly absurd:
"The results are quite interesting. First of all, the gcc compiler isn't very good in vectorizing. With vectorizing, we mean generating SIMD (SSE, Altivec) code. From the numbers, it seems like gcc was only capable of using Altivec in one test, the third one. In this test, the G5 really shows superiority compared to the Opteron and especially the Xeons"
In fact, gcc 3.3 is unable to generate AltiVec code ANYWHERE, except on x86 where they added a special SSE mode because x87 floating point is so miserable. This could have been discovered with about 5 minutes of Google research. It wouldn't had to have been discovered at all if they hadn't gone out of their way to use a compiler which is the non-default on OS X 10.4. Alarm bells should have been going off in the benchmarkers head when an AMD chips outperforms an Intel one by 3x, but, anyway ...
I hate to seem like I'm just blindly defending Apple here, but this article seems to have been written with an agenda. There's no way one guy could stuff this much stuff up. To claim there's something inherently wrong with OS X's ability to be a server is going against so much publicly available information it's not even funny. Notice Apple seems to have no trouble getting Apache to run with Linux-like performance: [Xserve G5 Performance].
Anyway ... on a more serious note, a switch of sorts to x86 may not be a hugely insane idea. IBM's ability to produce a low power G5 part seems to be seriously in question, so for PowerBooks Apple is pretty much running out of options. Worse comes to worst - if they started selling x86-powered portables, that might get IBM to work a bit harder to get them faster desktop chips.
-- "A Macintosh MPEG software developer"
christiansen89 - Monday, December 6, 2021 - link
Guess there's no one arguing that the PPC is not keeping its pace with the current market, but rather OS/X able to do Big Iron computing. And if rumors are true, where will you be able to get a PPC built once Apple drops IBM for Intel? https://tvzyon.com/aladdin0tw - Tuesday, June 14, 2005 - link
This is my first time to see someone use 'ab' command to conduct a test, and trying to tell us something from the test.In my opinion, ab is never a 'stress test' tool for any reason, especially when you want to conclude some creditable benchmark from this test. If we can accept 'ab', why I have to code so much for a stress test?
The 'localhost' is another problematic area, DNS. Why not using a fixed ip as an address? The first rule of benchmaking is isolated the domain in question, but I can not see you obey these rule. So how can you interpret your result as a performance faulty, not a dns related problem?
I think you should benchmark again, and try some good practices used in software industry.
Aladdin from Taiwan
demuynckr - Sunday, June 12, 2005 - link
jhagman, the number in the apache test table means the request per second that the server handles.jhagman - Wednesday, June 8, 2005 - link
Hi again, demuynckr.Could you please answer to me, or preferably add the information to the article. What the does the number in the apache test table mean and what kind of a page was loaded?
I assumed that the numbers given were hits per second or transfer rate. I've been testing a bit on my powerbook (although with a lower n) and I can very easily beat the numbers you have. So it is apparent that my assumption was wrong.
BTW, gcc-3.3 on Tiger knows the switch -mcpu=G5
rubikcube - Wednesday, June 8, 2005 - link
I thought I would post this set of benchmarks for os x on x86 vs. PPC. Even though XBench is a questionable benchmark, it still is capable of vindicating these questions about linux-ppc.http://www.macrumors.com/pages/2005/06/20050608063...
webflits - Wednesday, June 8, 2005 - link
"Yes I have read the article, I also personally compiled the microbenchmarks on linux as well as on the PPC, and I can tell you I used gcc 3.3 on Mac for all compilation needs :)."I believe you :)
But why my are results I get way higher than the numbers listed in the article?