Arm Unveils 2023 Mobile CPU Core Designs: Cortex-X4, A720, and A520 - the Armv9.2 Family
by Gavin Bonshor on May 28, 2023 8:30 PM ESTCortex-A720: Middle Core, Big on Efficiency
Focusing on Arm's latest middle core, the Cortex-A720 hasn't changed much from the previous Cortex A715 design last year, which was also Arm's first AArch64-only middle core. Arm has a set philosophy for its A700 family, and that's mostly about increasing performance through optimizations, delivering maximum levels of power efficiency within set thermal limits, and optimizing workloads for actual use cases instead of blisteringly fast benchmark performance. Arm's key aims are to enhance performance metrics while maintaining power efficiency, area, and all within an acceptable thermal envelope. Cost is also essential, with many entry-level mobile devices already on the market leveraging the Cortex A700 family for its main cores.

Similar to the Cortex-X4 in that the Cortex-A720 is built around the Armv9.2 ISA, Arm has optimized its design to enable the A720 to deliver more performance within the same power budget compared to the Cortex A715. The Arm 700-series family typically covers a much broader range of applications and caters to various markets, including, and not limited to, digital TVs (DTV), smartphones, and laptops. Having more comprehensive flexibility in a more diverse space has its advantages, and Arm looks to capitalize on that with the Cortex-A720 acting as the 'workhorse' of the TSC23 core cluster.
Devices such as smartphones at the entry-level typically want to reduce cost but maximize performance and efficiency, and that's where cores such as the Cortex-A720 come into play; the Cortex-X4 is primarily allocated to devices with flagship status or those that require the most burst and sustained performance, such as top tier smartphones, tablets, and laptops. Meanwhile, Cortex-A720 is the next step down, giving up the X4's high peak performance for a much smaller core size and with correspondingly lower energy consumption.
For the Cortex-A720 in particular, Arm is also offering multiple configuration options. Along with the standard, highest-performing option, Arm has what they're terming an "entry-tier" configuration that shaves A720 down to the same size as Arm Cortex-A78, all while still offering a 10% uplift in overall performance. With some Arm customers being especially austere on die sizes, moves such as these are necessary to convince them to finally make the jump over to the Cortex-A7xx series and Armv9.
Arm's focus is to broaden the range of the entry-level market and expand on the possible use cases for its Cortex-A720 core so that it can be implemented into a wider variety of entry-level mobile devices and in lower-end markets.

Some of the critical improvements to the Cortex-A720, when compared to the previous A715, is Arm has opted for a faster branch mispredict recovery. Branch prediction breaks down the instructions into predicates, and a branch predictor will only execute statements it predicates to be true. Opting for a faster branch mispredict recovery has multiple benefits, as it not only reduces the delay within the execution of instructions, but it can improve overall performance. Another element of this is pipeline efficiency, as a branch misprediction can disrupt the flow of instruction throughout the pipeline, and the ability to do this faster not only yields benefits to performance but also to overall power efficiency.

Arm has reduced the overall branch mispredict penalty on A720 to 11 cycles, down from 12 on the Cortex A715. They have also improved upon their 2-taken branch prediction technique, which predicts the outcome of the instruction, and, again, adds efficiency to the pipeline and reduces the penalties regarding misprediction.
Another improvement is the Pipelined FDIV/FSQRT (division + square root), which performs operations on floating point numbers using the pipelines. Allowing for concurrent executions of both FDI and FSQRT can improve instruction throughput, and Arm claims to have achieved a significant speed boost without impacting the overall area. There are also faster transfers from floating point to floating point, including NEON and SVE2 integer, which Arm introduced for Armv9. This also includes overall improvements to issue queues and the execution units, which simplifies the forwarding of data forwarding to AGUs.

Within the memory system of the Cortex-A720, reduced the L2 cache latency to 9-cycles, and Arm claims to have up to 2x the memset(0) bandwidth within the L2 cache. Without going into much detail about their methods, Arm also claims to have improved generationally on accuracy and coverage to the prefetcher. However, it has a new L2 spatial prefetch engine, which was previously a pioneering Cortex-X core system design feature.
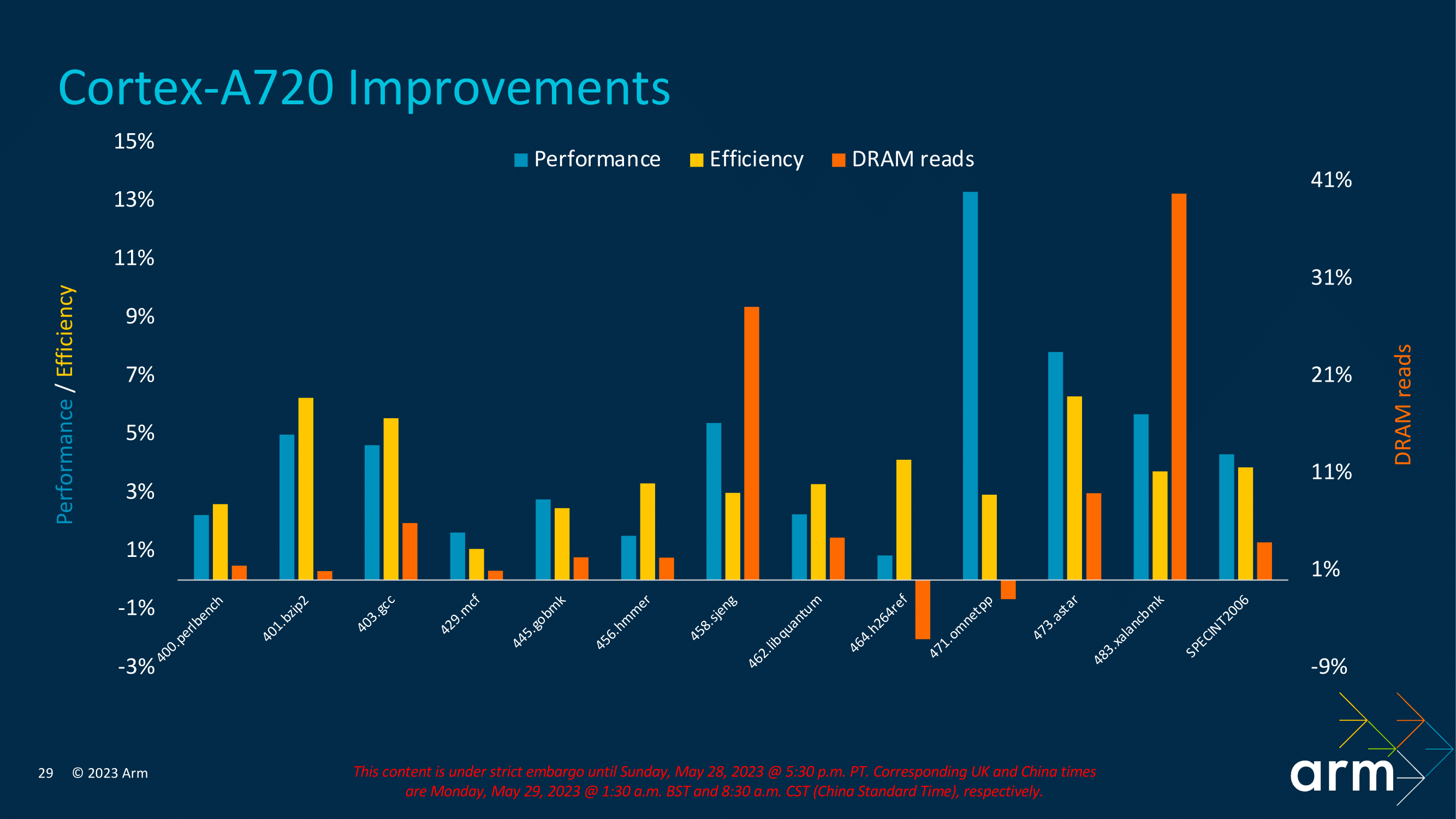
Translating the refinements and improvements to performance, Arm estimates the performance uplift to be about 15% at iso-frequency, depending on the workload. Among other benchmarkmarks, thare are clear gains over the previous generation in SPECint2017 and improvements within internal testing with SPECint2006. For example, using SPECint2007 as its performance indication metric in SPECint2007_403.gcc, the Cortex-A720 has a gain of around 5% over the Cortex A715, with an even more significant improvement of about 6% in power efficiency.
Other performance metrics on offer include DRAM reads, which Arm has focused a lot of attention on making more efficient, showing minor gains overall; SPEC2007int_483.xalacbmk shows a massive increase of up to 41% in DRAM read performance. While everything is relative and subjective to the workload tasked, Arm has made some clear forward progress with its latest Cortex-A720 CPU core microarchitecture.








52 Comments
View All Comments
tipoo - Sunday, May 28, 2023 - link
6 years after iOS went 64 bit only. I'm guessing the cores have also been 64 bit only there for a while?goatfajitas - Monday, May 29, 2023 - link
IOS is an OS from one company that is made for a few specific products from that one company. You cant evenly compare an open platform to a narrow closed market like that.iAPX - Monday, May 29, 2023 - link
Yes Apple SoC seems to be 64bit-only for years, that simplify their own design and gives more efficiency.As 64bit ARM ISA as nothing in common with 32bit ARM ISA, contrary to the x86 and AMD64, they basically started with a blank page, profiting from experience of various preceding 64bit ISA, I feel it was the right way to go.
dotjaz - Monday, May 29, 2023 - link
No it's not, Apple is not allowed to modify ARM ISA. If it's ARMv8 compliant, it CANNOT possibly be 64bit only.Doug_S - Monday, May 29, 2023 - link
ARMv8 makes execution of AArch32 optional. Apple may have been responsible for that as they were involved in the spec of ARMv8 and AArch64 - they would have known they'd want to drop 32 bit code as soon as it was practical.dotjaz - Tuesday, May 30, 2023 - link
That's factually UNTRUE, Aarch32 execution is mandatory in **hardware implementation**, Aarch64 **OS** can choose not to execute Aarch32 codesDoug_S - Tuesday, May 30, 2023 - link
Sorry but you are wrong, ARMv8 specifically makes support for AArch32 optional for hardware implementations.Jaybird99 - Monday, May 29, 2023 - link
Apple is a founding partner with an architectural license. They can change anything they wish on the CPU design, then have it fabricated. I thought this was known because of the wildly different core design from Apple. They take the ISA they pick and choose and add/delete what they need. They actually help ARM in the long run as seeing how Apple uses 64bit and finds solutions to their issues, because as stated above 64bit was blank slate for ARM. I'm very fairly certain of this, but if you know something I don't? (I might not..)Doug_S - Monday, May 29, 2023 - link
An architectural license allows them to implement the ISA, but they can't delete things from it. They are able to add things to it (i.e. TSO, their AMX instructions, etc.) but it still has to pass ARM's conformance tests to show it is capable of running ARM code.They were able to "delete" AArch32 because ARMv8 allows that. ARMv9 goes further and makes AArch32 a special license addition or something like that - basically Aarch32 is deprecated with ARMv9 and will probably go away entirely with ARMv10.
dotjaz - Tuesday, May 30, 2023 - link
No, they were not able to "delete" AArch32. They can disallow AArch32 codes execution in their OS just like Google Pixel 7-series, they cannot remove the support from hardware.And Apple did not add anything to ARM ISA. AMX is masked as a co-processor only available through frameworks, it doesn't directly execute any code other than a "firmware".
TSO is not an instruction. It's a **mode**. It pertains to HOW the CPU reorders L/S queue. It has nothing to do with the ISA.