AMD Demonstrates Stacked 3D V-Cache Technology: 192 MB at 2 TB/sec
by Dr. Ian Cutress on May 31, 2021 11:50 PM EST
The AMD team surprised us here. What seemed like a very par-for-the-course Computex keynote turned into an incredible demonstration of what AMD is testing in the lab with TSMC’s new 3D Fabric technologies. We’ve covered 3D Fabric before, but AMD is putting it to good use by stacking up its processors with additional cache, enabling super-fast bandwidth, and better gaming performance. That’s the claim at any rate, and AMD showcased its new demo processor on stage at Computex. Here’s a deeper run-down into what it actually is.
3D Chiplets: The Next Step
AMD announced it was looking into 3D stacking technologies with ‘X3D’ back in March 2020 at its Financial Analyst Day, with a very odd diagram showing a chiplet processor with what looked like stacks of HBM or some sort of memory around the outside. At the time AMD said it was a mix of 2.5D and 3D packaging technologies enabling 10x bandwidth density or higher. The ‘X’ in ‘X3D’ was meant to stand for Hybrid, and the technology was set for ‘the future’. Since then TSMC has announced its 3D Fabric line of technologies, a broad name for its combination of 2.5D and 3D integration offerings.

Today AMD presented the first stage of its 3D chiplet journey. The first application is a stacked cache on top of a standard processor chiplet. On stage, Lisa Su showcased one of AMD’s Ryzen 5000 dual-chiplet processors with Zen 3 cores. On one of the compute chiplets, a 64 MB SRAM built on TSMC’s 7nm was integrated on the top, effectively tripling the amount of cache that the cores have access to.
That means that the original Ryzen 5000 chiplet, with eight cores having access to 32 MB of L3 cache, now becomes an eight-core complex with access to 96 MB of L3 cache. The two dies are bonded with Through Silicon Vias (TSVs), passing power and data between the two. AMD claims that the total bandwidth of the L3 cache increases to beyond 2 TB/sec, which would technically be faster than the L1 cache on the die (but with higher latency).

As part of the chip diagram, the TSVs would be direct copper-to-copper bonding. The cache die is not the same size as the core complex, and as a result additional structural silicon is needed to ensure that there is equal pressure across both the bottom compute die and the top cache die. Both dies are thinned, with the goal to enable the new chiplet in the same substrate and heatspreader technology currently in use in Ryzen 5000 processors.
The prototype processor shown on stage had one of its chiplets using this new caching technology. The other chiplet was left as standard to show the difference, and the one chiplet that had the cache die ‘exposed’ made it obvious and comparable with the regular non- integrated chiplet. CEO Dr. Lisa Su said that the 64 MB SRAM in this case is a 6mm x 6mm design (36 mm2), which puts it at just under half the die area of a full Zen 3 chiplet.

In a full product Lisa explained that all the chiplets would have the stacked cache enabled, for 96 MB of cache per chiplet, or 192 MB total for a processor like this that has 12 or 16 cores.
As part of the technology, it was explained that this packaging enables a >200x interconnect density compared to regular 2D packaging (which is something we already know from HBM stacking), a >15x density increase compared to microbump technology (a shot straight across the bow of Intel’s Foveros), and >3x better interconnect efficiency compared to microbumps. The TSV interface is a direct die-to-die copper interconnect, meaning that AMD is using TSMC’s Chip-on-Wafer technology. Dr Su claimed on stage that these features make this the most advanced and flexible ‘active-on-active’ chip stacking technology in the industry.
As for performance demonstrations, AMD compared a before and after using Gears of War 5. On one side was a standard Ryzen 9 5900X 12-core processor, while the other was a prototype using the new 3D V-Cache built upon a Ryzen 9 5900X. Both processors were fixed at 4 GHz, and paired with an un-named graphics card.

In this scenario the comparison point is that one processor has 64 MB of L3 cache, while the other has 192 MB of L3 cache. One of the selling points of Ryzen 5000 processors was the extended L3 cache available to each processor to help with gaming performance, and moving that up to 96 MB per chiplet extends that advantage even further, with AMD showing a +12% FPS gain (184 FPS vs 206 FPS) with the increased cache size at 1080p. Over a series of games, AMD claimed +15% average gaming performance:
- DOTA2 (Vulkan): +18%
- Gears 5 (DX12): +12%
- Monster Hunter World (DX11): +25%
- League of Legends (DX11): +4%
- Fortnite (DX12): +17%
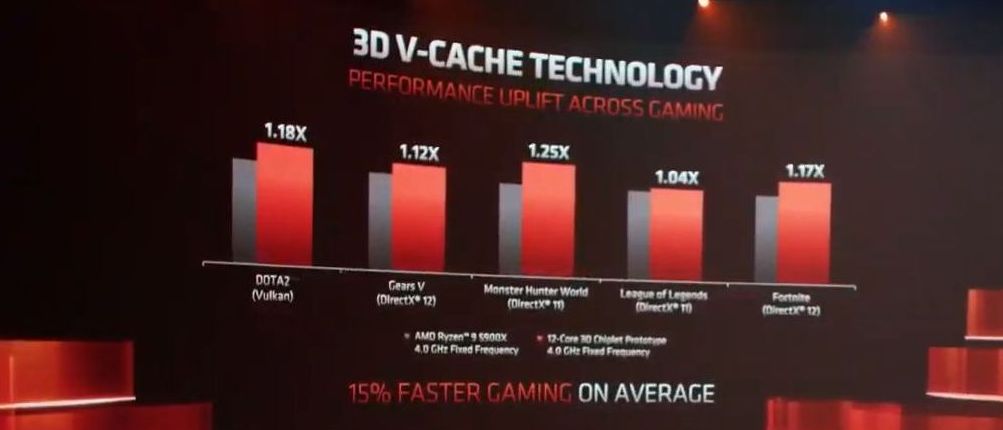
This is not an exhaustive list by any means, but it makes for interesting reading. AMD’s claim here is that a +15% bump is akin to a full architecture generation jump, effectively enabling a rare improvement through philosophical design differences. Here at AnandTech we would like to note that as it becomes harder to drill down into new process nodes, philosophical design enhancements might become the main driver of future performance.
AMD says that it has made great strides with the technology, and is set to put it into production with its highest-end processors by the end of the year. It wasn’t stated on what products it would be coming to, whether that was consumer or enterprise. Apropos of this, AMD has said that Zen 4 is set for launch in 2022.
The AnandTech Analysis
Well that was unexpected. We knew that AMD was going to be investing in TSMC’s 3D Fabric technology, but I guess we didn’t expect it to be this soon or with a demo on a desktop processor first.

Starting with the technology, this is clearly TSMC’s SoIC Chip-on-Wafer in action, albeit with only two layers. TSMC has demonstrated twelve layers, however those were non-active layers. The problem with stacking silicon is going to be in the activity, and subsequently thermals. We’ve seen with other TSV stacked hardware, like HBM, that SRAM/memory/cache is the perfect vehicle for this as it doesn’t add that much to the thermal requirements of the processor. The downside is that the cache you stack on top is little more than just cache.

This is where AMD and Intel’s stacking differs. By using TSVs rather than microbumps, AMD can get greater bandwidth and power efficiency out of TSVs, but also stack multiple chiplets high if needed. TSVs can carry power and data, but you still have to design around the two for cross signaling. Intel’s Foveros technology, while it is also 3D stacking, it relies on microbumps between the two chiplets. These are bigger and power-hungry, but allow Intel to put logic on both the lower die and upper die. The other element is thermals – usually you want the logic on the top die to manage the thermals better as it is close to the heatspreader/heatsink, but moving logic further away from the substrate means that power has to be transported up to the top die. Intel is hoping to mix microbumps and TSVs in upcoming technologies, and TSMC has a similar roadmap for the future for its customers.
Moving to the chiplet itself, it was claimed that the 64 MB L3 cache chiplet is 6mm x 6mm, or 36 mm2, and is built on TSMC 7nm. The fact that it is built on TSMC 7nm is going to be a critical point here – you might think that a cache chiplet might be better suited to a cheaper process node. The tradeoff in cost is power and die area (yield at such a small die size isn’t worth considering). If AMD is to make these cache chiplets on TSMC 7nm, then that means a Zen 3 with additional cache requires 80.7 mm2 for the Zen 3 chiplet as normal, then another 36 mm2 for the cache, effectively requiring 45% more silicon per processor. While we’re currently in a silicon shortage, this might have an effect on how many processors are made available for wider use. This might be why AMD said it was looking at ‘highest-end’ products first.
Now adding 64 MB of cache to a chip that already has 32 MB of L3 cache isn’t as straightforward as it seems. If AMD is directly integrating it as an adjacency to the L3 cache, then we have a dual-tiered L3 cache. Likely accessing that 64 MB requires more power, but that provides greater bandwidth. It would depend on the workload if the regular 32 MB is enough, compared to the extra 64 MB provided by the stacked die. We could see the extra 64 MB seen as an equivalent L4 cache, however the issue here is that in order for that extra 64 MB to go out to main memory, it has to pass through the main chiplet under it. That’s an additional power draw worth noting. I am very interested in seeing how the memory profile from the perspective of a core comes out with this extra chiplet, and how AMD is integrating that into the structure. AMD has stated that it is an SRAM-based design, so unfortunately it isn’t anything fancy like persistent memory, which would have been a whole different design ethos. By sticking to SRAM it means that at least it can seamlessly provide performance uplifts.
On the performance, we’ve seen L3 cache depth improve gaming performance, both for discrete and integrated gaming. However, increased L3 cache depth doesn’t do much else for performance. This was best exemplified in our review of Intel’s Broadwell processors, with 128 MB of L4 cache (~77 mm2 on Intel 22nm), wherein the extra cache only improved gaming and compression/decompression tests. It will be interesting to see how AMD markets the technology beyond gaming.
Finally, interception into the mainstream - AMD says that it is ready to start integrating the technology into its high-end portfolio with production at the end of the year. AMD has said that Zen 4 on 5nm launch is in 2022. Based on previous timescales, we have predicted that AMD’s next processor family is roughly a Feb 2022 launch. Whether that would be Zen 4 it’s unclear at this point, but also Zen 4 is on 5nm and AMD is showcasing this 3D V-Cache on 7nm. Whether AMD has plans to monetize this feature on 7nm, or whether it might combine a 5nm Zen 4 chiplet with a 7nm 64 MB cache chiplet is unclear. It wouldn’t be too difficult to combine the two, however I suspect that AMD might want to push its caching technology into more premium products than Ryzen desktop. We might see special one-off editions as the technology ramps through the stack.
To conclude, I have a number of questions I’d like to ask AMD. I’m hoping that I will get some answers, and if I do, I’ll cycle back with the details.

Update: June 1st:
In a call with AMD, we have confirmed the following:
- This technology will be productized with 7nm Zen 3-based Ryzen processors. Nothing was said about EPYC.
- Those processors will start production at the end of the year. No comment on availability, although Q1 2022 would fit into AMD's regular cadence.
- This V-Cache chiplet is 64 MB of additional L3, with no stepped penalty on latency. The V-Cache is address striped with the normal L3 and can be powered down when not in use. The V-Cache sits on the same power plane as the regular L3.
- The processor with V-Cache is the same z-height as current Zen 3 products - both the core chiplet and the V-Cache are thinned to have an equal z-height as the IOD die for seamless integration
- As the V-Cache is built over the L3 cache on the main CCX, it doesn't sit over any of the hotspots created by the cores and so thermal considerations are less of an issue. The support silicon above the cores is designed to be thermally efficient.
- The V-Cache is a single 64 MB die, and is relatively denser than the normal L3 because it uses SRAM-optimized libraries of TSMC's 7nm process, AMD knows that TSMC can do multiple stacked dies, however AMD is only talking about a 1-High stack at this time which it will bring to market.








93 Comments
View All Comments
name99 - Tuesday, June 1, 2021 - link
"We’ve seen with other TSV stacked hardware, like HBM, that SRAM/memory/cache is the perfect vehicle for this as it doesn’t add that much to the thermal requirements of the processor. The downside is that the cache you stack on top is little more than just cache."Yes and no. We've heard about PiM (Processor in Memory) for years, to little practical effect.
A more feasible route to the same end (not perfect, but "good enough", at least to get the ball rolling) might be PiC3 (Processor in L3 Cache), once 3D allows for enough cache that you can start thinking beyond just moar moar capacity?
mode_13h - Tuesday, June 1, 2021 - link
> We've heard about PiM (Processor in Memory) for years, to little practical effect.Didn't Samsung recently announce HBM with embedded processing?
AI accelerators tend to have lots of on-chip memory (usually/always SRAM). For instance, the Grayskull processor, by recently-profiled Tenstorrent, has 120 MB SRAM, and is made on a 12 nm process node.
ChaosFenix - Tuesday, June 1, 2021 - link
So some things I think would make sense here. Dr. Cutress mentions that TSMCs stacking tech goes up to 12 layers currently. Wouldn't it make more sense to have the layers that generate the most heat up top with the lower powered layers on bottom. This should put them closer to the heat spreader. An effective design in my opinion would have something like layer 1-5 NAND, Layer 6-9 DRAM, Layer 10 SRAM, layer 11 efficiency cores, Layer 12 high power cores. I obviously have no idea what said stack would cost but even something as simple as having layer 1 SRAM and layer 2 Processing cores would be better than the inverse right?IntelUser2000 - Tuesday, June 1, 2021 - link
Please. This is wrong."AMD claims that the total bandwidth of the L3 cache increases to beyond 2 TB/sec, which would technically be faster than the L1 cache on the die (but with higher latency)."
Zen 3 can sustain 2x 256-bit loads per cycle which at 4GHz equals to 256GB/s bandwidth. But that's per core. If you multiply that by 16x, that's 4TB, or double the V-Cache.
Otritus - Wednesday, June 2, 2021 - link
It doesn't work like that. Individual cores don't have access to the L1$ or L2$ of other cores, meaning the individual caches don't have access to each other. 2TB/s of bandwidth is more bandwidth than the L1$ because the CPU doesn't have 1 L1$, it has 16(or 32 if you break apart data and instructions).serendip - Tuesday, June 1, 2021 - link
ARM designs need this, huge high speed caches.del42sa - Wednesday, June 2, 2021 - link
yes and 8 ALU529th - Wednesday, June 2, 2021 - link
So are we all thinking this will be for the 5k series desktops, too? Being demonstrated on a 5900X led me to believe so.Santoval - Thursday, June 3, 2021 - link
"This V-Cache chiplet is 64 MB of additional L3, with no stepped penalty on latency."Does this mean it is going to have the same latency as the in-die L3 cache despite being off-die (barely off-die but still off-die)? Is that really possible? What does "stepped" mean in the above context?
coffeeandknives - Friday, June 4, 2021 - link
I'm curious what implications this has in conjunction with the Xilinx merger. Can you stack an FPGA in the loop and what is possible? I recently saw an article regarding an FPGA + CPU that had a continuously changing architecture which made it safe from certain hacks.