Arm Unveils 2023 Mobile CPU Core Designs: Cortex-X4, A720, and A520 - the Armv9.2 Family
by Gavin Bonshor on May 28, 2023 8:30 PM ESTArm Cortex-X4: Fastest Arm Core Ever Built (Again)
Diving further into Arm's new CPU core microarchitectures, we'll start with the Cortex-X4, which stands out as the most substantial advancement. Arm has consistently achieved significant double-digit improvements in instructions per cycle (IPC) with each iteration, starting from the original Cortex X1 core, then progressing to the Cortex X2, and continuing with the Cortex-X3 IP introduced last year, and they'll do so again for the Cortex-X4 in 2023 as well. The Cortex-X4 is specifically designed to cater to cutting-edge flagship Android-based smartphones and leading mobile devices that utilize robust Arm IP-based System-on-Chips (SoCs). Representing a subtle yet impactful enhancement over its predecessor, the Cortex-X4 further refines the capabilities of the Cortex-X3 core.
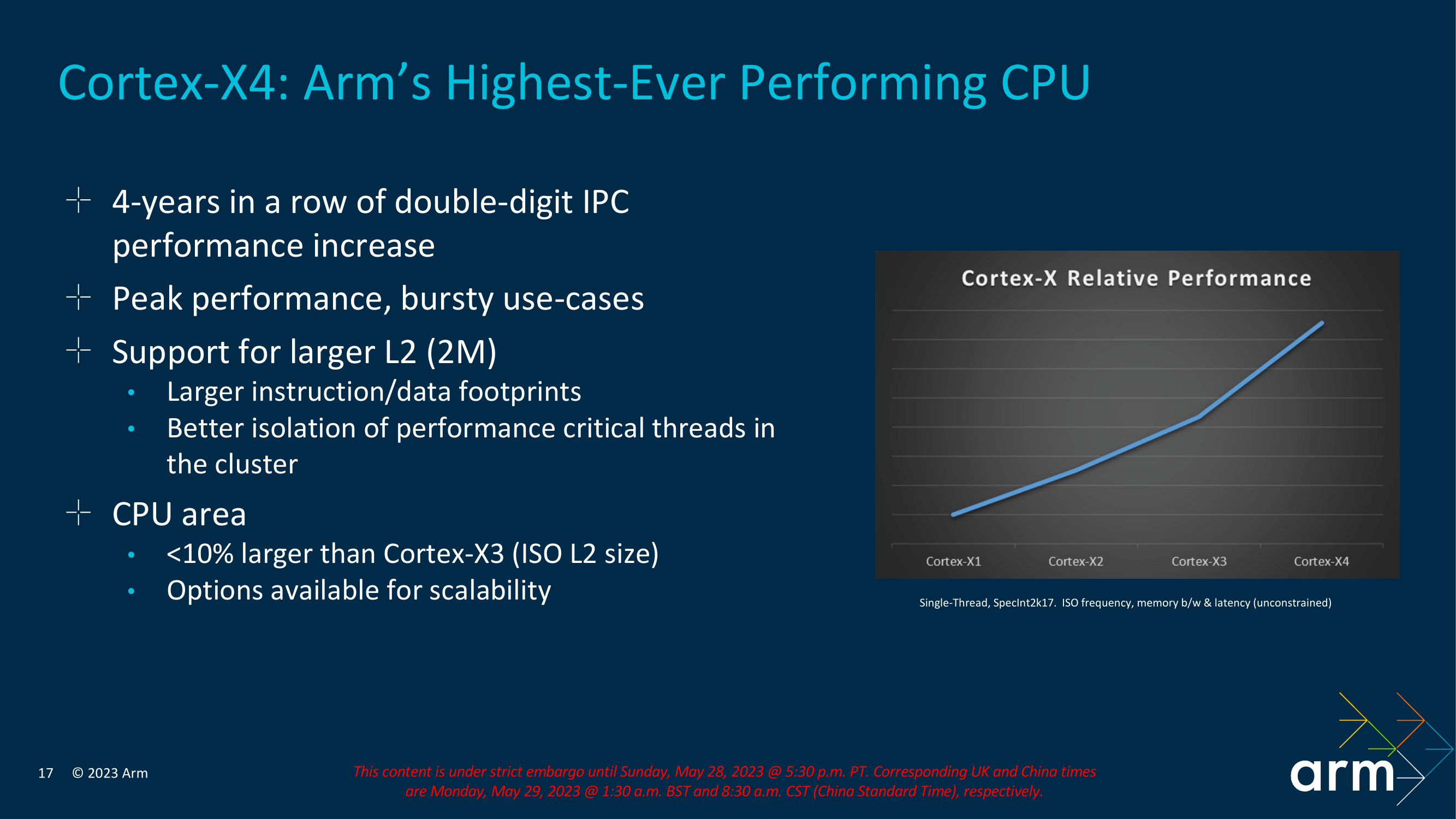
The Cortex-X4 is designed to deliver top-tier compute performance in mobile System-on-Chips (SoCs), particularly tailored to handle demanding workloads like AAA gaming and bursty operations. The Cortex-X4 is Arm's highest-performing core to date, featuring an anticipated core clock speed of 3.4 GHz and an increased L2 cache per core, doubling its capacity to 2 MB compared to last year's 1 MB Cortex-X3 . Despite these enhancements, Arm has managed to maintain a minimal increase in the physical size of the core, with the more complex X4 CPU core coming in at under a 10% die size increase (the additional L2 cache excluded).
As for power efficiency, Arm claims a notable improvement in power savings of approximately 40% compared to previous generations. Don't expect to see too many CPU vendors take advantage of that, since the primary job of the X-series is to run fast, but it goes to show what the X4 can accomplish in conjunction with the latest fab nodes.
Arm Cortex-X4: Front End Reshuffle, Redesigning Instruction Fetching
In terms of architecture, the Cortex-X4 exhibits similarities to its predecessor, the Cortex-X3, with the primary focus being on refining the existing architecture and optimizing efficiency across various core components.
Now while things haven't changed all too much architecturally from the Cortex-X4 to the Cortex-X3, the Cortex-X4 front end has had a reshuffle and a tweak of the instruction fetching block. The aim of Arm has been to keep latencies low while offering peak bandwidth throughout its Cortex-X4 core and within the entire TSC23 core cluster.

With regards to the Cortex-X4's front end, the big architectural change here has been through its dispatch width. The Cortex-X4 now has a more focused 10-wide dispatch width, up for the 6/8-wide dispatch width of the X3. That said, while the front-end has gotten wider, the effective pipeline length has actually shrunken even so slightly; the branch mispredict penalty is down from 11 cycles to 10.
The other big front-end focus has been on the instruction fetching process itself; Arm has essentially redesigned the entire instruction fetch delivery system to ensure better efficiency throughout the pipeline when compared to the Cortex-X3.
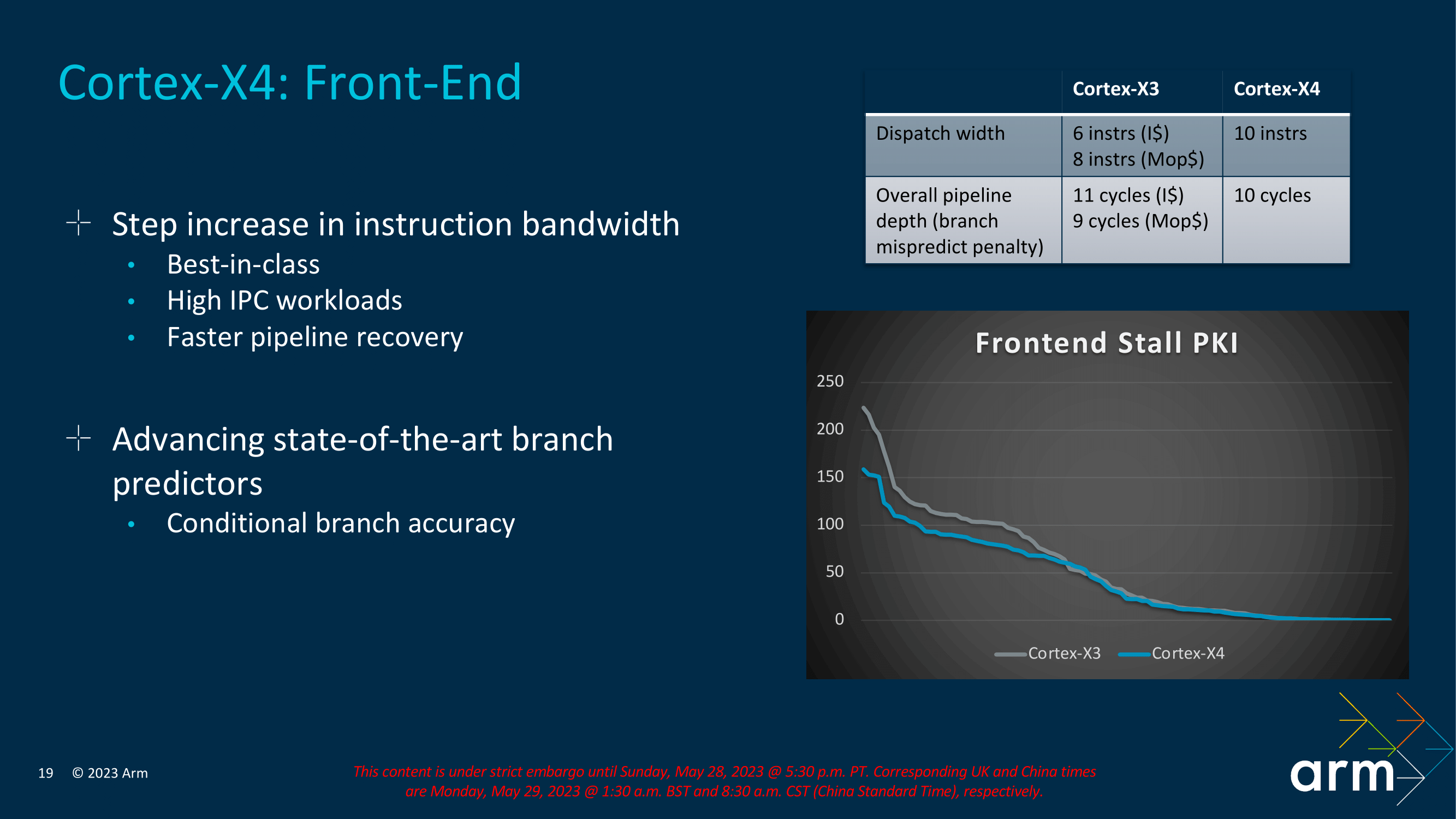
The latest architecture also takes another pass on improving Arm's branch prediction units, further improving their prediction accuracy. Arm isn't saying much about how they accomplished this, though we do know that they've targeted conditional branch accuracy in particular. None of this comes for free, though; Arm was quick to note that the improved predictors were more expensive to implement. Still, Arm believes this is worth it in keeping the beast (Cortex-X4) fed, so to speak.
Shifting to the back-end of the CPU core, Arm has taken a focus on execution bandwidth. Among other changes, Arm has increased the number of ALUs from 6 to 8. Of these, six are simple ALUs for processing single-cycle uOPS. Meanwhile, there are two complex ALUs for processing dual and multi-cycle instructions, Arm has also squeezed another branch unit in, giving the Cortex-X4 a total of 3, up from 2, as well as adding an extra Integer MAC. Meanwhile on the floating point side of matters, the Cortex-X4 also upgrades a pipelined FP divider.
So to some extent, the X4's performance improvements come from a brute force increase throughout the chip, with the chip able to dispatch and retire more instructions in a single clock. The goal for the Cortex-X4 is to offer peak performance on both benchmarks and real-world workloads, as well as an increase in the fetch bandwidth for any instruction set going through the pipeline. The benefits come through latency reductions and instruction fusion benefits for larger instruction footprint workloads.
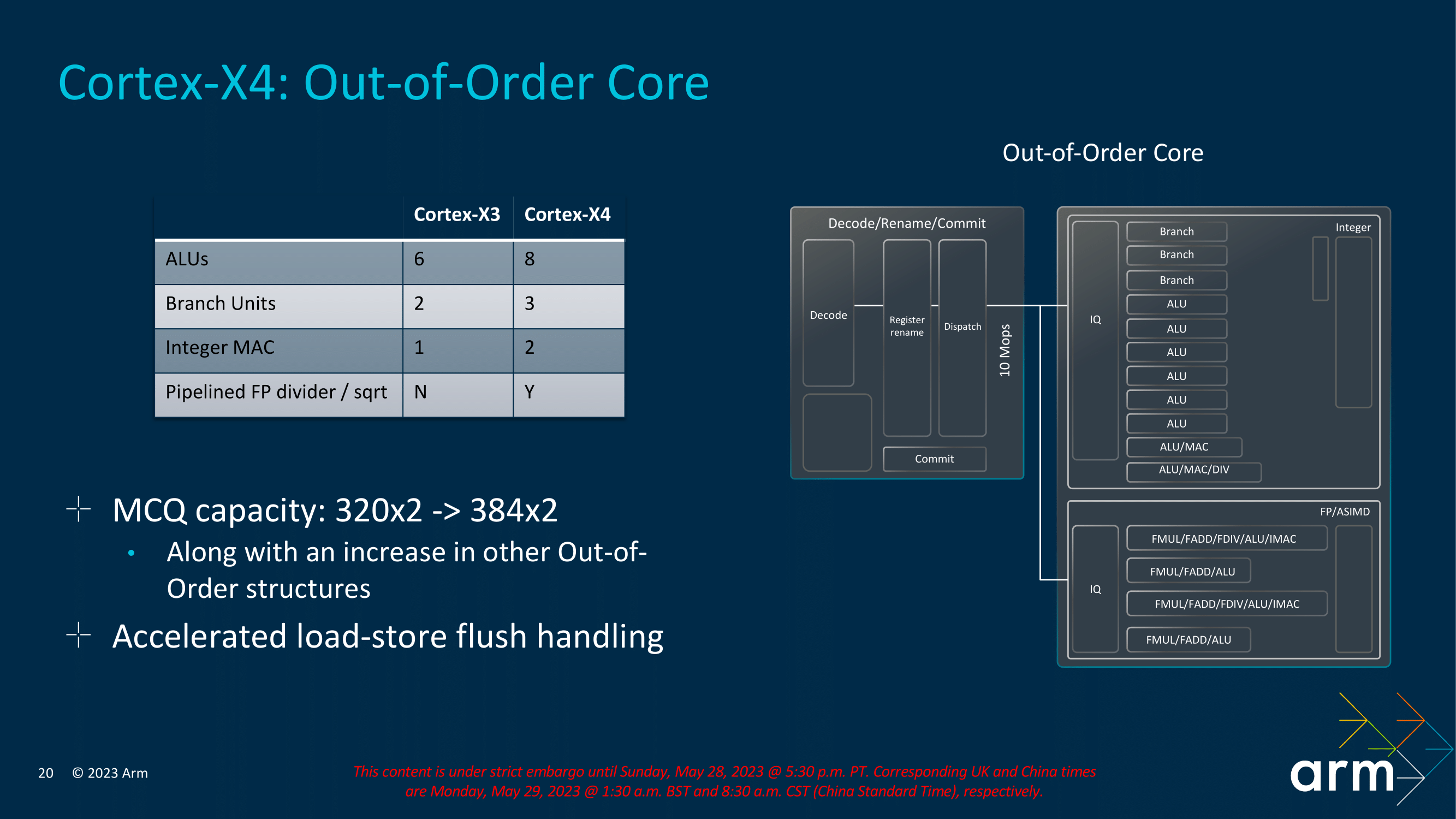
Increasing the Micro-op Commit Queue (MCQ) capacity – and thus the size of the window for instruction re-ordering – is another refinement in Arm's toolbox for Cortex-X4. As with previous increases in Arm's re-order buffers, the larger queue affords more opportunities to look for instruction re-ordering, to hide memory stalls and otherwise extract more opportunities for the rest of the CPU back-end to get some work done. And with CPU performance continuing to outpace memory bandwidth, the need for larger buffers only grows with each generation.
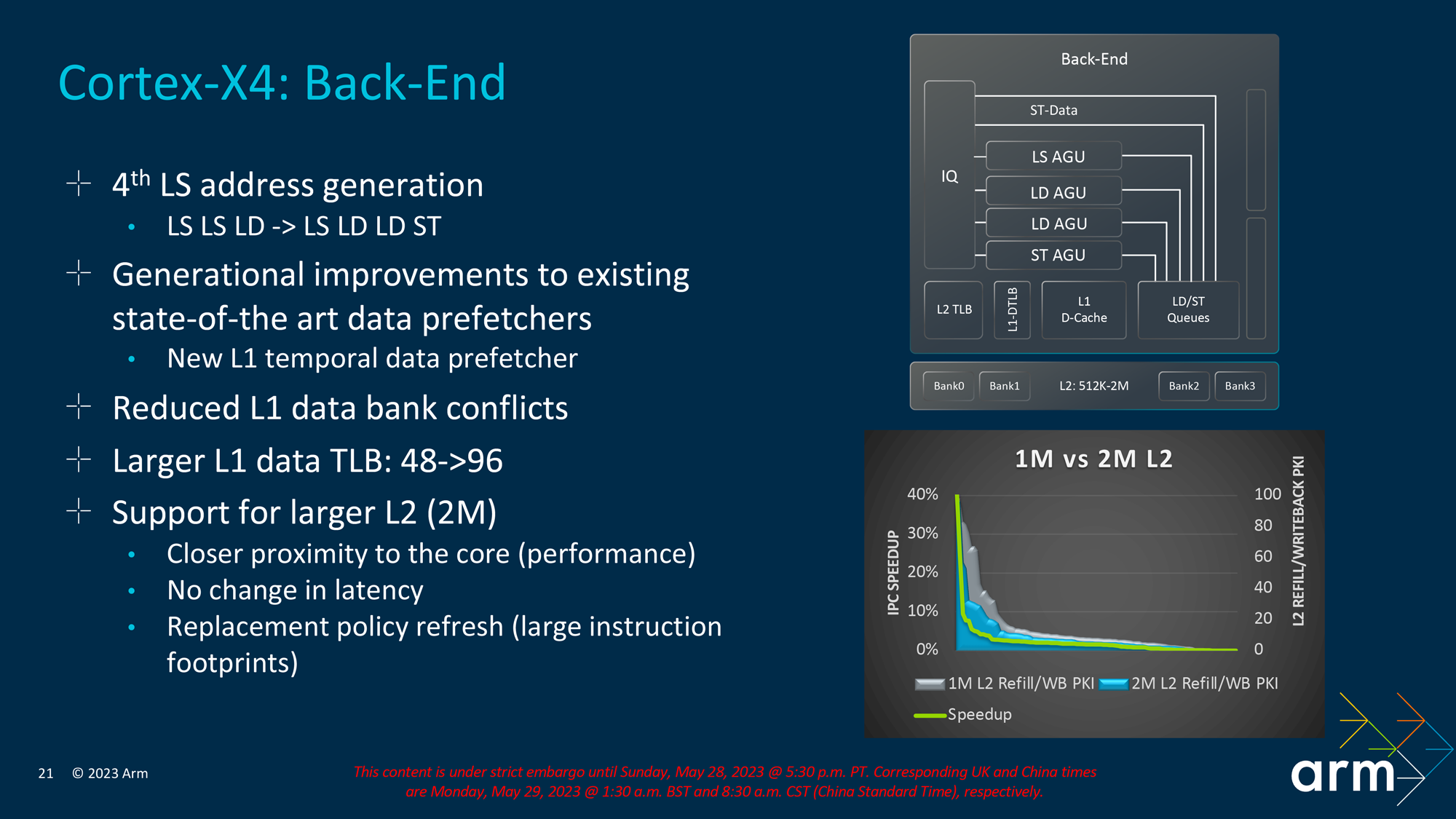
Finally, at the far back end of the X4 CPU core, Arm has added a fourth address generation unit. Interestingly, this one is just for stores; Arm already had a load-only unit, but opted for a store-only unit rather than converting it to a full mixed LS unit.
The L1 cache subsystem of the Cortex-X4 has also received a lot of work. The L1's translation lookaside buffer (TLB) has been doubled to 96 entries, and there's a new L1 temporal data prefetcher. Finally, Arm has taken steps to reduce the number of L1 data bank conflicts on the X4.
There have also been some changes made to better support the larger L2 cache size of the Cortex-X4 that we previously discussed. The L2 has been moved physically closer to the CPU core for performance reasons, and Arm has been able to expand the L2 size without any resulting increase in latency. So there is less of a trade off here than is often the case for increasing cache sizes.
Cortex-X4: IPC Uplift, Scalable up to 14-Cores, Up to 32 MB L3 Cache
One of the primary benefits of Arm's v9.2 architecture shift is that it offers increased scalability. The TSC23 core cluster now supports up to 14 cores which adds a level of flexibility for SoC vendors to implement into their latest designs. Perhaps one of the biggest changes is support for up to 32 MB of shared L3 cache within the TSC23 core cluster. The levels of L3 cache implemented is of course down to the SoC manufacturer, but the maximum levels that can be offered is 32 MB, which allows increased support for higher-end mobile devices such as tablets and notebooks, where applicable.
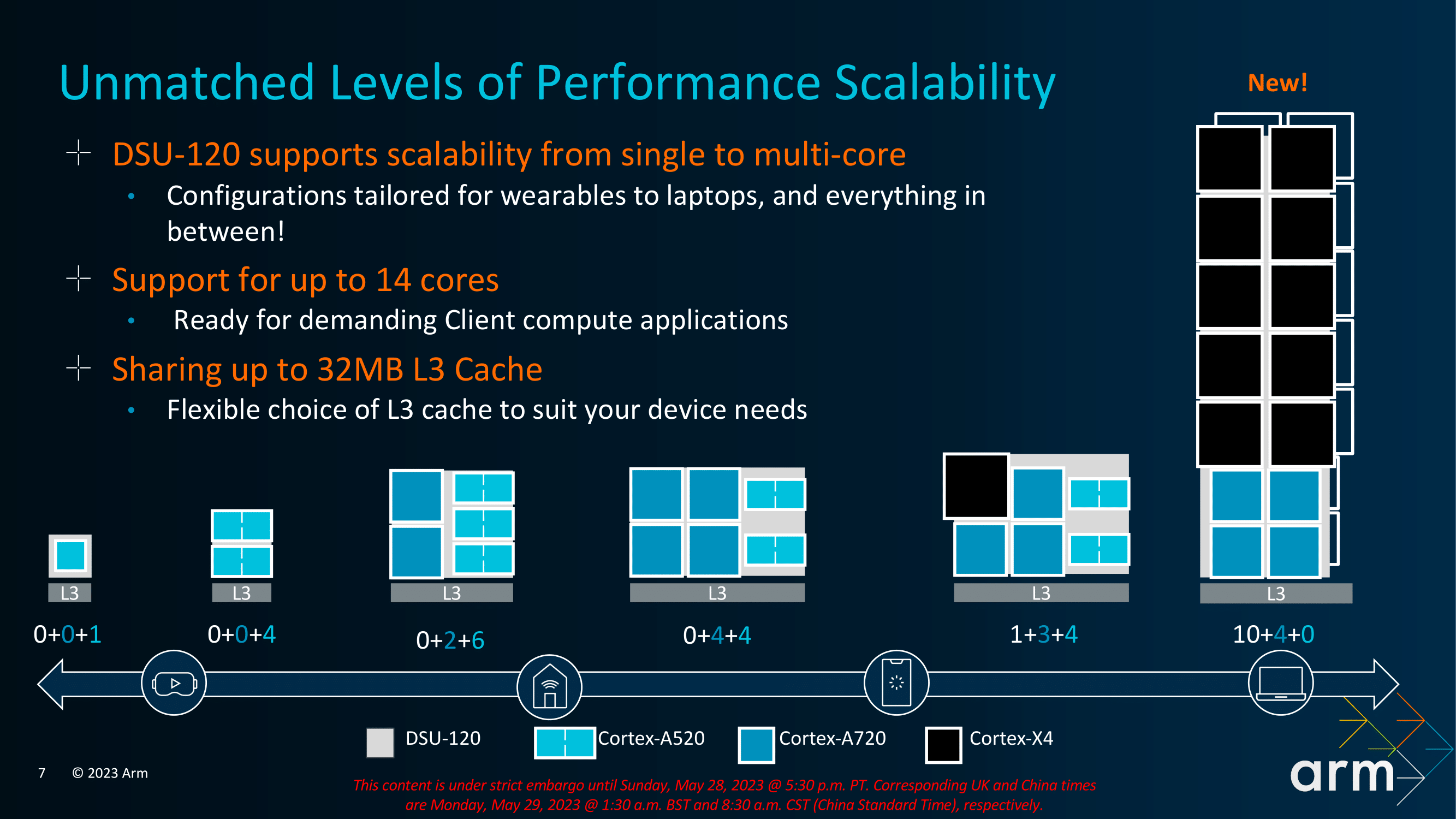
The maximum number of cores across the entire TSC23 core cluster stretches to 14 in total, with a mixture of big and little cores, with multiple avenues for SoC vendors to explore to capitalize on things like performance gains and efficiency. All of this flexibility is given to the SoC vendors to design their own variations depending on the level of the device. So a flagship mobile device will leverage different combinations of Cortex-X4, Cortex-A720, and Cortex-A520 depending on multiple factors such as cost, power budget, and expected performance levels.
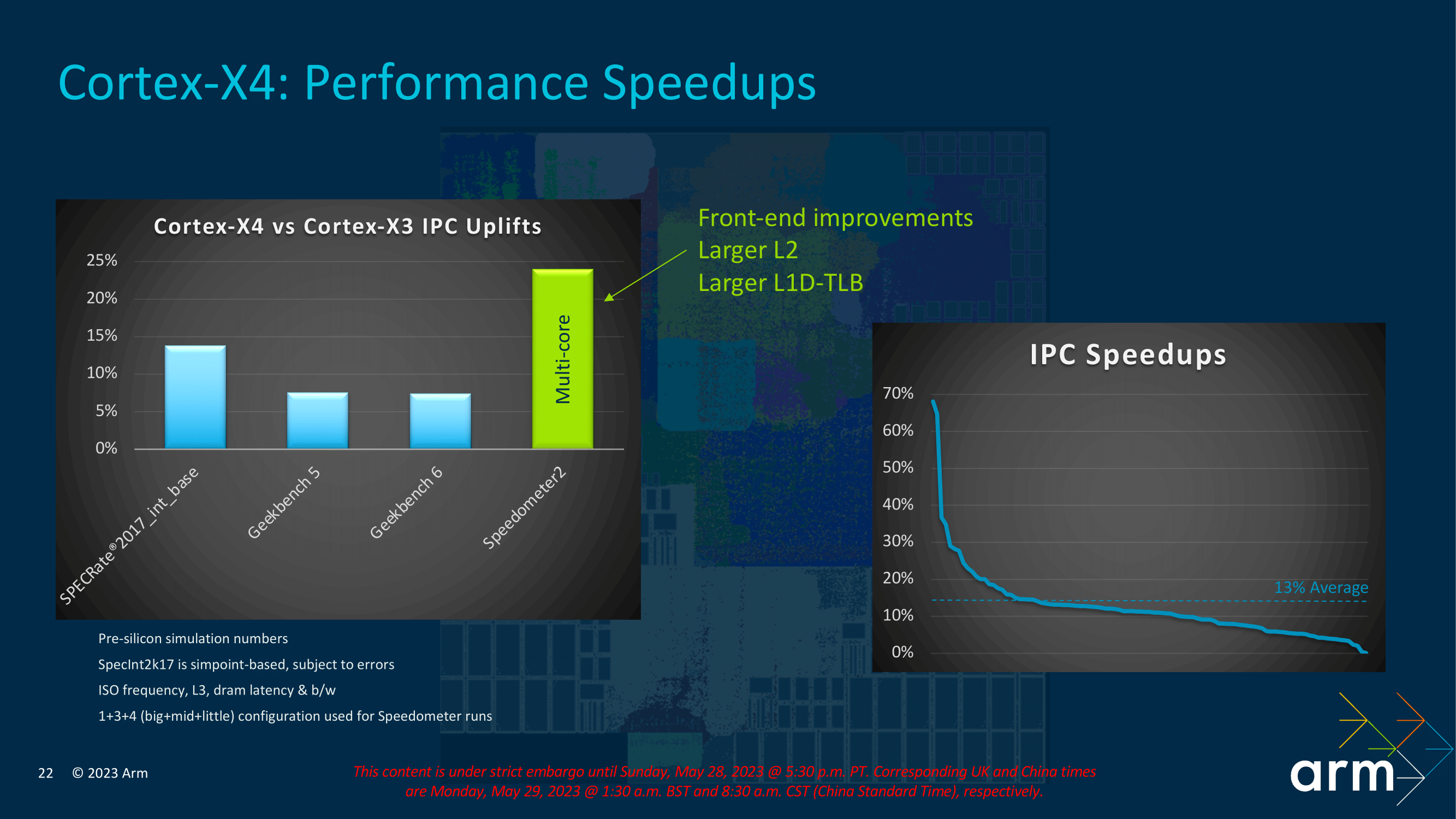
A bigger core and optimizations of existing processes typically come with a performance benefit. Arm is claiming that, based on its pre-silicon simulation numbers, the Cortex-X4 will deliver a 15% IPC uplift at iso-frequency and iso-bandwidth versus the Cortex-X3 used in last year's flagship Android SoCs. There are a number of factors at play here in delivering that total performance improvement, including front-end optimizations and improvements, as well as a larger L2 per core cache of 2 MB and a larger L1D-TLB, which is a cache designed for recently accessed page transitions.








52 Comments
View All Comments
Ryan Smith - Monday, May 29, 2023 - link
Thanks!GC2:CS - Tuesday, May 30, 2023 - link
Mediatek dimensity 93004xx4 + 4x A720 no little cores. 50% lower power, beats next gen Apple CPU (A17).
First time one ever with more than 3 X CPU’s ?
https://m.gsmarena.com/mediatek_dimensity_9300_tip...
iphonebestgamephone - Tuesday, May 30, 2023 - link
8cx gen 3 - 4x x1 + 4x a78tipoo - Thursday, June 1, 2023 - link
Given that A17 isn't out yet, how do we know?Zoolook - Sunday, June 4, 2023 - link
4 X4s would make for a very big chip, I doubt it, but we'll see, A17 is on N3 and Dimensity 9300 will be on N4P so also doubt that.NextGen_Gamer - Tuesday, May 30, 2023 - link
Is there going to be another follow-up article about the new Immortalis-G720 GPU?brucethemoose - Tuesday, May 30, 2023 - link
^I think the GPU is becoming the more critical part in phones... I hate to downplay CPU advances, but what does being faster than an X1 really get you on mobile these days?
GPUs, on the other hand, are the bottleneck for running local AI. Flagships can already run 7B LLMs and other generative models reasonably well, but every ounce of extra GPU speed allows for significantly better inference. They are also the bottleneck for VR/AR and ports of PC/console games.
nandnandnand - Tuesday, May 30, 2023 - link
The real advance for CPU might be locking the performance in place but lowering the power usage. Which is why we're hearing about Dimensity 9300 supposedly packing four Cortex-X4 cores and four Cortex-A720 cores, with no presence of Cortex-A520. In a smartphone SoC.Shouldn't these flagships being using their dedicated AI accelerators instead of the GPU for inference?
TheinsanegamerN - Wednesday, May 31, 2023 - link
AI accelerators are just that, accelerators. You still need heavy compute power, and that comes from GPUs.nandnandnand - Wednesday, May 31, 2023 - link
I don't think an iGPU is significantly more powerful than an AI accelerator.