The AMD FX (Bulldozer) Scheduling Hotfixes Tested
by Anand Lal Shimpi on January 27, 2012 12:47 PM ESTMixed Workloads: Mild Gains
The one thing all of the following benchmarks have in common is they feature more varied CPU utilization. With periods of heavy single and all core utilization, we also see times when these benchmarks use more than one core but fewer than all.
SYSMark has always been a fairly lightly threaded test. While there are definite gains seen when going from 2 to 4 cores, this is hardly a heavily threaded test. The performance impact of the hotfixes is negligible in the overall performance result or across the individual benchmark suites however:
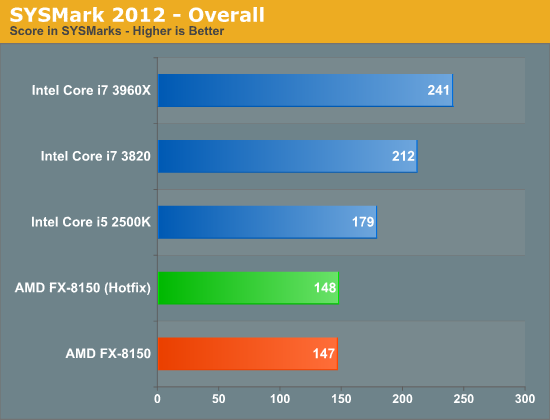
Our Visual Studio 2008 compile test is heavily threaded for the most part, however the beginning of the build process uses a fraction of the total available cores. The hotfixes show a reasonable impact on performance here (~5%):
The first pass of our x264 transcode benchmark doesn't use all available cores but it is more than just single threaded:

Performance goes up but only by ~2% here. As expected, the second pass which consumes all cores in the system remains unchanged:

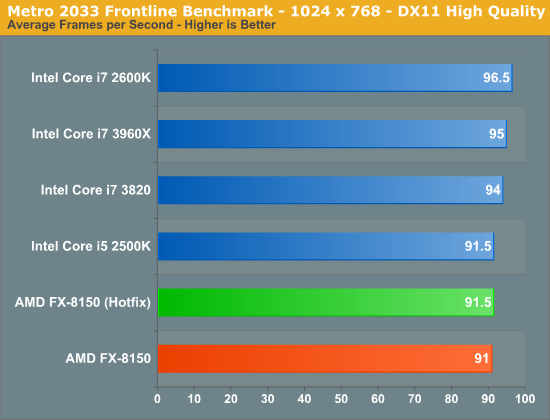
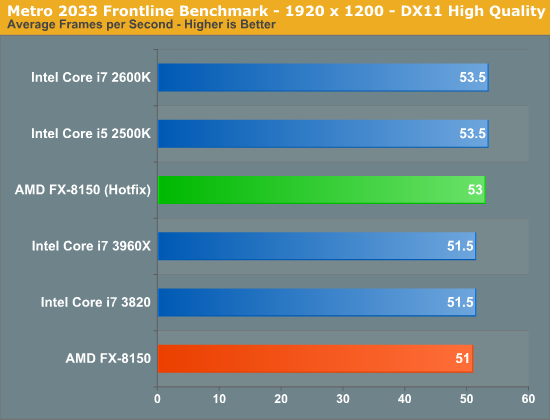
Games are another place we can look for performance improvements as it's rare to see consistent, many-core utilization while playing a modern title on a high-end CPU. Metro 2033 is fairly GPU bound and thus we don't see much of an improvement, although for whatever reason the 51.5 fps ceiling at 19x12 is broken by the hotfixes.
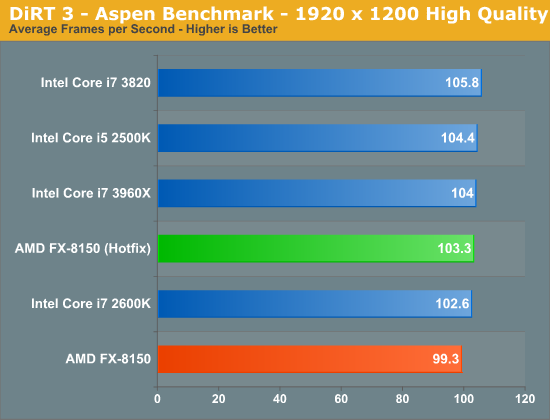
DiRT 3 shows a 5% performance gain from the hotfixes. The improvement isn't enough to really change the standings here, but it's an example of a larger performance gain.

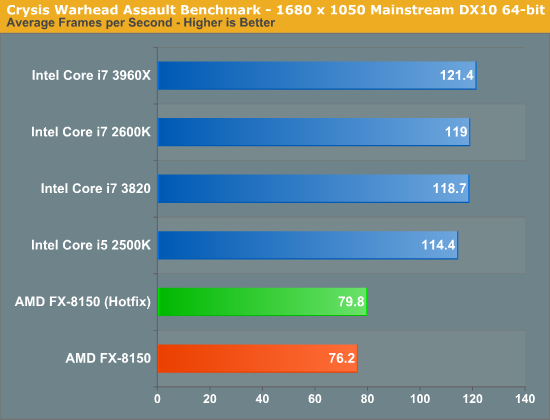
Crysis Warhead mirrors the roughly 5% gain we saw in DiRT 3:
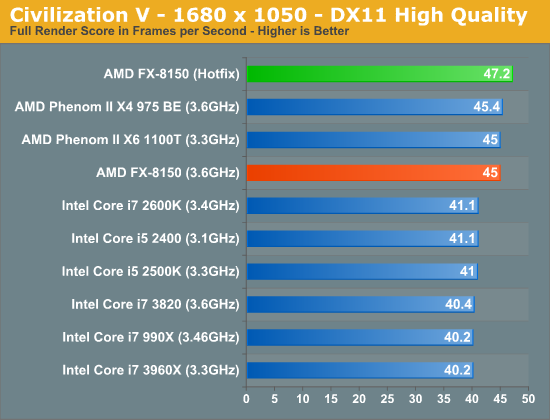
Civilization V's CPU bound no render results show no gains, which is to be expected. But looking at the average frame rate during the simulation we see a 4.9% increase in performance.









79 Comments
View All Comments
KonradK - Friday, January 27, 2012 - link
"Ideally, threads with shared data sets would get scheduled on the same module, while threads that share no data would be scheduled on separate modules."I think that it is impossible for sheduler to predict how thread will behave and it is not practical to track the behaviour of running thread (tracking which areas of memory are accessed by threads would be so computational intensive as computational intensive is emulation).
So ultimately there is choice between "threads should be scheduled on separate modules if possible" or "do not care which cores belongs to the same module" (pre-hotfix behaviour).
Second means that Bulldozer will behave as PIV EE (2 core, 4 threads) on Windows2000, at least for threads that uses FPU heavily. Windows 2000 does not ditinguish between logical and physical cores.
Araemo - Friday, January 27, 2012 - link
I've noticed that windows doesn't always schedule jobs well to take advantage of Intel Turbo Boost.. I realize that it probably doesn't have a noticeable level of impact, but I do notice that running only 1 thread of high-cpu-utilization still doesn't often kick turbo above the 3/4 cores active frequency.. I can use processor affinity on the various common background tasks to pull them all to 1 or 2 cores to activate full turbo, but if a process is only using a percent or so of cpu resources, why schedule it to an otherwise-inactive core if there is an already-active, but 98% un-utilized core available? I think the power gating efficiencies would actually be more useful than the pure mhz-related turbo efficiencies (Running 2 cores 100Mhz faster is probably going to waste less power than you gain by shutting down the other two cores completely/partially).Is there anything to address that behavior?
taltamir - Friday, January 27, 2012 - link
Wouldn't those hotfixes improve performance on intel HT processors as well?tipoo - Friday, January 27, 2012 - link
No, Windows already leaves virtual threads from hyperthreading alone until all the physical cores are used, so this won't improve things on the Intel side any. This is specifically for Bulldozer and future architectures like this.Hale_ru - Monday, February 6, 2012 - link
Bullshit!Win7 had nothing to do with Intel HT until AMD hit them in the head!
I had so much asspain with Win7 shity CPU scheduler on FEM and FDTD simulations.
8HT-core setup just reduces overall performance up to 50%(a HALF!!!) comparing to NO-HT setup.
Simpel task manager checkup showed that Win7 just was putting low-threaded processes on the same core without an option. Just simplest increment scheduler they have for Intels.
Hale_ru - Monday, February 6, 2012 - link
So, it is recommended to use AMD optimization patches (only the core-addresing one, not the C6 state patch) on any Win7 machine using simple multithreaded mathematics.hescominsoon - Friday, January 27, 2012 - link
Shared cpu modules that have to compete for resources? Reminds me of HT v1. IMO this is basically a quad core chip with the other 4 threads available in the primary core isn't being used all the way. I've looked at the design and it's just nonsensical. This is not a futuristic bet but a desperate attempt at differentiation...with most likely disastrous results. AMD has now painted themselves into a niche product instead of a high performance general purpose cpu.dgingeri - Friday, January 27, 2012 - link
I like the design of the Bulldozer overall, but there is obviously a bottleneck that is causing problems with this chip. I'm thinking the bottleneck is likely the decoder. it can only handle 4 instructions per clock cycle, and feeds 2 full Int cores and the FP unit shared between the two cores. I bet increasing the decoder capacity would show a really big increase in speed. What do you think?bji - Saturday, January 28, 2012 - link
I think that if it was something easy, AMD would have done it already or are in the process of doing it.I also think that it's unlikely that it's something as simple as improving the decoder throughput, because one would think that AMD would have tried that pretty early on when evaluations of the chip showed that the decoder was limiting performance.
These chips are incredibly complicated and all of the parts are incredibly interrelated. The last 25% of IPC is incredibly hard to achieve.
bobbozzo - Friday, January 27, 2012 - link
The hotfixes also support Windows Server 2008 R2 Service Pack 1 (SP1)