SambaNova Breaks Cover: $450M AI Startup with 8-Socket AI Training Solutions (and more)
by Dr. Ian Cutress on December 9, 2020 8:00 AM EST
Users that follow the AI silicon space will have heard of SambaNova – a quiet company that has made very little noise but has racked up some serious backing. After three funding rounds, led by Google Ventures, Intel Capital, and Blackrock, and semi-hushhush deployments at the US Department of Energy at Laurence Livermore and Los Alamos, there is now a new product offering for limited customers. SambaNova is already making money, and the company is finally ready to break the crust on its very delicate crème brûlée and start talking about its new DataScale SN10-8R (catchy name) systems, built with its new Cardinal AI Processor.
AI Silicon: A Recap
Most artificial intelligence or machine learning workloads fall into two categories: training and inference.
The first is training, where an algorithm is either fed data, or a competitive model plays games, with the goal to create the best algorithm possible from millions, billions, or trillions of parameters. This is big boy computing, and requires beefy hardware (OpenAI's GPT3 required ~$12m of cloud compute time time) that scales well.
The second is inference, where an already trained (known as pre-trained) model is shown new data, and has to respond accordingly. This is by contrast a lightweight workload that only requires the mathematical function of the model, where benchmarks such as latency (time to respond), bandwidth (inferences per second), accuracy (is it correct), and power (inferences per watt) are important. Hardware focusing on inference exists in IoT and smartphones today.
So the idea is that you train a model to identify a cat by showing it 100 million images of cats and dogs and pandas and foxes to distinguish between them all. An inference is showing that trained model a new picture of a cat, and getting the correct result.
Both training and inference can be performed on regular compute processors, on high-performance graphics hardware, or as we are seeing more in this industry, dedicated AI solutions for one, the other, or both. Companies in this space tend to be focused on one or the other – training needs big silicon with lots of memory often in datacenters, whereas inference can be done in super small form factors and IoT style-functionality.
Most training hardware is also capable of inference, but due to power, tends to work on ‘bulk inference in the cloud’, such as analyzing the complete set of human text ever written, or a social media’s back catalogue of photographs, rather than immediate facial recognition in a shop window for sales purposes.
SambaNova and its new Cardinal AI chip
Most AI silicon companies are inference focused, and there’s about 50 thousand million of those (perhaps a slight exaggeration, perhaps not). It is a lot more complex to develop silicon for training, because it requires big silicon to do heavy lifting, and so there are only a few companies. There are other noticeable difficulties in also finding suitable customers - there's no point spending millions if there are only two companies who would buy what you create. As a result, most bets on AI training either peter out quickly, or the money gets big. Most big AI training companies over the last few years have pulled in a lot of funding from investors, while others have been acquired. SambaNova fits in that first category, with some $450m of venture capital funding for its new Cardinal AI chip.

The Cardinal AI chip is large, monolithic, and built on TSMC’s N7 process. At 40 billion transistors it measures in the 708 mm2 space, which is almost near the reticle limit, like a number of other high-performance AI training processors. SambaNova’s chip is an array of reconfigurable units for data, storage, or switching, optimized for data flow (they call it a Reconfigurable DataFlow Unit, or RDU), to cover a wide variety of bandwidth, storage, and compute requirements that come from a wide array of training workload requirements. The goal is that if a workload needs more memory, the silicon can adapt, almost like an FPGA/structured ASIC, but in this case with a lot more performance and efficiency.
One of the issues with training workloads is memory bandwidth, and being able to get training data from storage into the compute silicon. This is why a number of AI training hardware designers are implementing high bandwidth memory, innovative packaging techniques, or strong chip-to-chip communication topologies. SambaNova isn’t going to too many details about the chip right now, but did note on some key areas with regard the solution they are providing. The most important of which are memory capacity per Cardinal and interconnect bandwidth between neighboring Cardinal silicon.
SambaNova isn’t going to sell a single chip on its own, but much like other start-ups will sell a solution to be installed in a data center. The basic unit of SambaNova’s offering will be a quarter rack design (9U?) called the DataScale SN10-8R, featuring an AMD EPYC Rome x86 host paired with eight Cardinal chips and 12 terabytes (yes that’s correct) of DDR4-3200 memory, or 1.5 TB per Cardinal. SambaNova will scale its offerings based on the number of quarter racks a customer requires, with default specifications of 1/4 rack (8 RDU), 1/2 rack (16 RDU, and 1 rack (32 RDU). Beyond that will be customer specific.
Each Cardinal chip has six DDR4 memory controllers for the memory, enabling 153 GB/s memory bandwidth. The eight chips are connected in an all-to-all configuration, enabled through a switching network (like an NVSwitch). We were told that each chip has 64x PCIe 4.0 lanes to that network (enabled through four x16 root complexes), which offers 128 GB/s in each direction to a switch, however the protocol being used over PCIe is custom to SambaNova.
The switches also enable system-to-system connectivity, which is where SambaNova can enable scale-out to multiple quarter-rack deployments. Each quarter rack will come with a default set of integrated networking and management features, which if the customer requires can be remotely managed by SambaNova. When asked at what level these systems can scale to, SambaNova said that there is a theoretical limit however trying to quantify that is ultimately not practical – they are quoting that two full racks worth, or eight SN10-8R systems (also 64 chips) can outperform the equivalent NVIDIA’s DGX-A100 deployment by 40% in performance at lower power.
On the software side of the equation, SambaNova have their own graph optimizer and compiler, enabling customers currently using PyTorch or TensorFlow to have their workloads recompiled for the hardware in less than an hour (citing one of SambaNova’s customer deployments). Head of Product at SambaNova, Marshall Choy, stated in our briefing that ease-of-use is one of SambaNova’s key pillars for the DataScale product line. It’s important to the company, according to Marshall, that customers want access to the hardware and to go in the quickest possible time, and that’s what the product delivers.
The four key attributes that Marshall went through for the company are (in order) performance, accuracy, scale, and ease-of-use. A number of highlighted customer testimonials as part of this new product announcement highlight these attributes to the new hardware, even with installation during COVID times and 100% remote management.
Even though today is the product announcement and the company coming out of semi-stealth mode, SambaNova is already shipping systems for revenue and has been through 2020. There are also four main customer targets that this first generation product are targeting, primarily due to the fact that these are the training workloads that SambaNova’s current customers are running. These product areas are:
- Transformers (Natural Language, Visual Analysis)
- High Resolution Computer Vision (4K to 50K images, such as stellar cartography)
- Recommendation Systems (Online Retail, Banking Fraud Detection)
- AI For Science
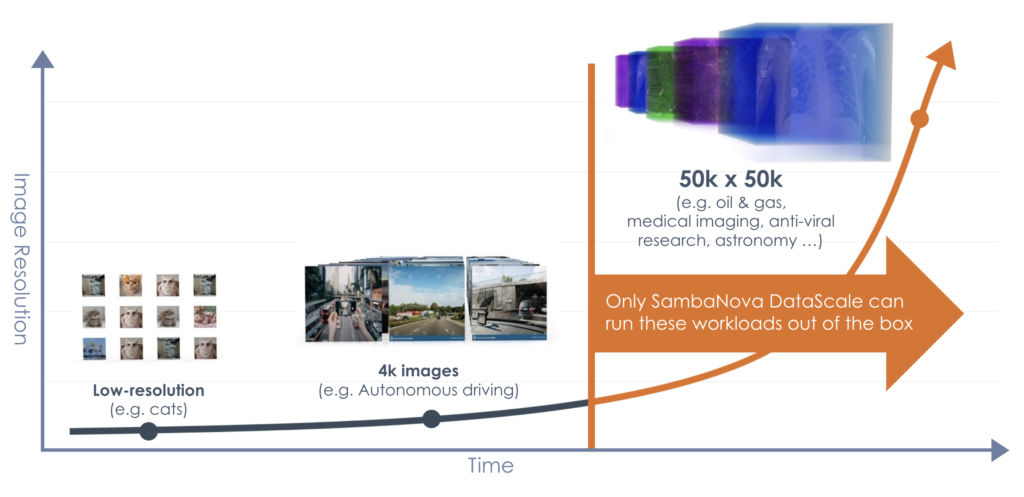
As part of the product announcement today, SambaNova is comparing itself favorably to some of the most common hardware available in the market for these segments, mostly against NVIDIA. SambaNova states that they perform better and at lower power than NVIDIA’s offering. SambaNova also highlights that its chip is built to perform in-the-loop training, allowing for model reclassification and optimization on the fly during inference-with-training workloads without requiring a memory dump and kernel switch and simply offering a heterogeneous zerocopy-style solution – by comparison, other hardware has to reconfigure itself to do one or the other.
For benchmarks that might mean something in the wider market, we did ask about MLPerf. We were told that even though SambaNova is one of the first companies involved with the MLPerf project (especially SN’s founders), they’re focused right now on deploying for customers and meeting their needs, rather than the general industry comparison metric. That doesn’t mean they are averse to MLPerf apparently, and they will get there at some point.
SambaFlow
Not to be confused with a popular in-game energy drink, SambaFlow is the software packaging for use with the SN10-8R. The toolchain takes inputs from TensorFlow, PyTorch, or custom graphs, and does graph analysis to convert what is needed in terms of machine learning compute or other custom compute. This includes tiling analysis, and according to SambaNova’s website, tiling can be automated. The analysis is then put through SambaNova’s compiler to optimize for the dataflow architecture, as well as taking into account physical data locations, before being passed through as a runtime.
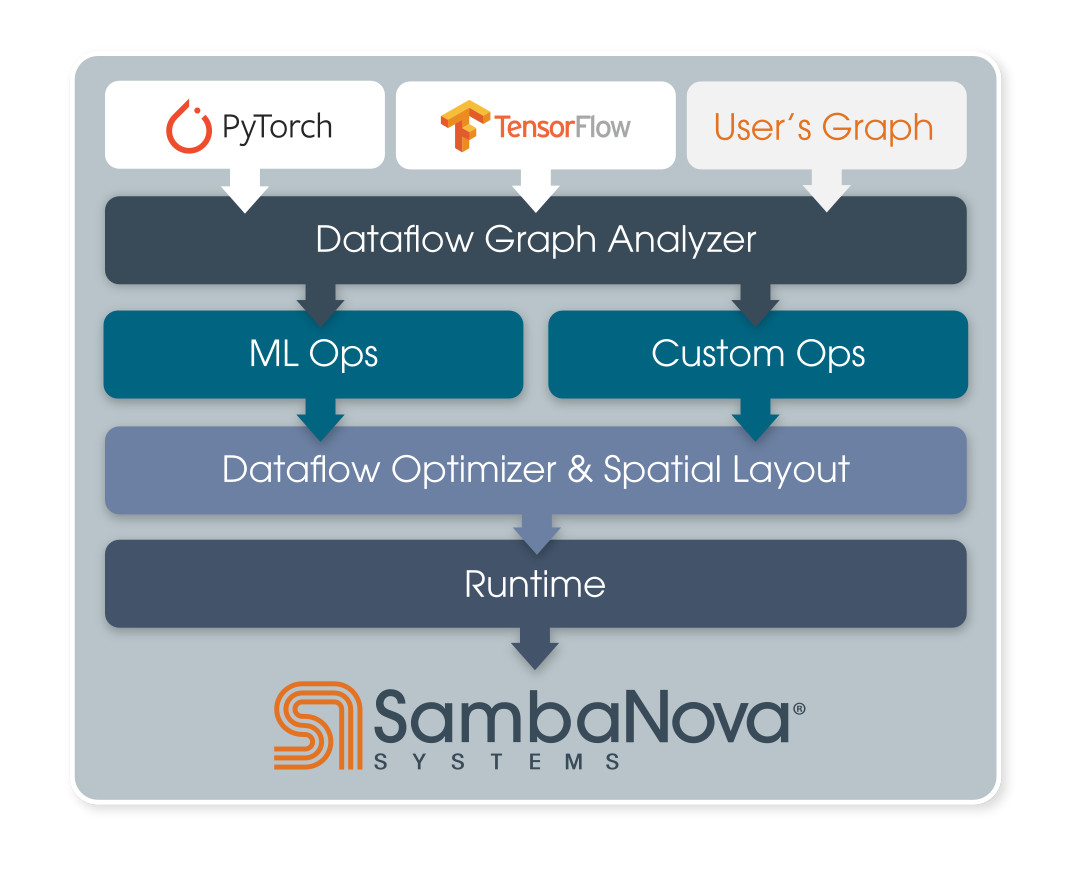
The key elements to SambaNova’s approach according to the company is to surpass limitations of GPUs for this sort of workload. Among the claims include support for 100 billion parameters in a training model, as well as a larger memory footprint allowing for larger batch sizes, model parallelism and hardware utilization, and greater accuracy.
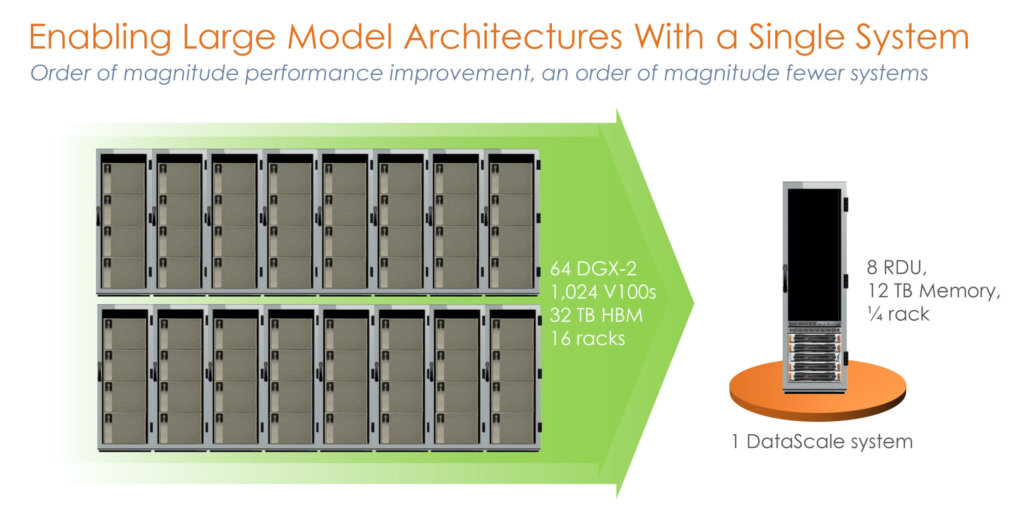
This also converts into lower power consumption and (one would assume) better TCO.
SambaNova
The company itself was founded in September 2017, and has roots in ex-Sun Oracle architects. The three founders all have backgrounds in creating silicon solutions:
- CEO Rodrigo Liang, Sun/Oracle Processor Development of SPARC and ASICs
- CTO Prof. Kunle Olukotun, Sun/Oracle, lead of Stanford’s Hydra Chip CMP research project
- Prof. Chris Ré, Stanford AI Lab and InfoLab, sold two data management companies to Apple
The company has been through three rounds of funding:
- Series A, $56m, led by Walden International and Google Ventures
- Series B, $150m, led by Intel Capital
- Series C, $250m, led by BlackRock
This puts SambaNova near the top of AI chip funding with $456m, surpassed only by GraphCore ($460m) and Horizon Robotics ($700m), and closely followed by Nuvia ($293m), Cambricon ($200m), and Cerebras ($120m).
SambaNova employs around 150 employees, based in Palo Alto. This first generation chip taped out in Spring 2019, with first samples of A0 silicon being powered on within the hour of arrival. The company was running customer models within the month. Since then, SambaNova has already been selling to select customers for over a year before this point – the only ones public are from the Department of Energy at Lawrence Livermore and Los Alamos. We clarified that the other customers are not investors, but high-profile companies that see the need to be on the leading edge with something new. Customers are across a number of segments, primarily involved in the four segments listed above.
SambaNova has promised more announcements regarding its product portfolio over time. This announcement coincides with the NeurIPS (Neural Information Processing Systems) conference, and historically the company has also attended HPC-style events as well. As and when more details are made available, we’ve asked to be notified.
Two More Small Announcements
Along with the new SN10-8R product, SambaNova is set to offer two cloud-like service options: one for academia and research, and one for customers.
The first for academia is the SambaNova AI Platform (SNAP), which is a free-to-use developer cloud for research institutions with compute access to the hardware. Access is granted based on a project application process – exact details are to be confirmed.
The second is for business customers that want the flexibility of the cloud without paying for the hardware. DataFlow as a Service (DFaaS, if you will) will enable customers to ‘rent’ a system and for it to be placed within a corporate firewall, but with cloud-like access. Management and updates will be done remotely by SambaNova, as if it was a true cloud offering, but with that security aspect of having the hardware in-house. This will be a subscription offering, focused mainly on Natural Language, Recommendation engines, and High Resolution Computer Vision customers
Source: SambaNova
Related Reading
- Intel’s New eASIC N5X Series: Hardened Security for 5G and AI Through Structured ASICs
- Qualcomm's Cloud AI 100 Now Sampling: Up to 400TOPs at 75W
- TSMC and Graphcore Prepare for AI Acceleration on 3nm
- Cerebras Wafer Scale Engine News: DoE Supercomputer Gets 400,000 AI Cores
- Intel Whittles Down AI Portfolio, Folds Nervana in Favor of Habana
- Samsung Kicks Off Mass Production of AI Chip for Baidu: 260 TOPS at 150 W
- AI On The Edge: New Flex Logix X1 Inference AI Chip For Fanless Designs
- Cambricon, Makers of Huawei's Kirin NPU IP, Build A Big AI Chip and PCIe Card








9 Comments
View All Comments
Elchanan Haas - Wednesday, December 9, 2020 - link
I believe OpenAI created GPT3, not Googlep1esk - Wednesday, December 9, 2020 - link
“ SambaNova have their own graph optimizer and compiler, enabling customers currently using PyTorch or TensorFlow to have their workloads recompiled for the hardware in less than an hour”What? For every training run?
anandam108 - Thursday, December 10, 2020 - link
I think it would be once for a new model architecture.webdoctors - Wednesday, December 9, 2020 - link
There's open benchmark competitions.MLPerf, why can't companies just be honest and throw their results there so the customer can get clear comparisons rather than all this random marketing nonsense. Seems ridiculous to keep reinventing the wheel.
https://mlperf.org/
Kresimir - Friday, December 11, 2020 - link
MlPerf is now MLCommons and Sambanova Systems is a founding member.https://mlcommons.org/en/
opticalai - Wednesday, April 14, 2021 - link
can you point to the submission of results?quorm - Wednesday, December 9, 2020 - link
Stellar cartography, huh. I'm guessing there's a tiny bit more money in analyzing images from the satellites pointed at Earth.PaulHoule - Monday, December 14, 2020 - link
The reason you see so much competition for inference accelerators as opposed to training accelerators is that commercially viable AI involves doing inference many thousands or millions of times for every time you train.Because so many people are learning ML, training is front-of-mind for many people, but it makes no sense to train on 10000 examples and then infer on 10 examples from an economic viewpoint. (unless the product is that you learned how to look up the answers in the PyTorch manual.)
It is a tricky market to be in. The Department of Energy has sufficient spend on HPC (which that machine must crush) that it can finance this sort of thing, but a focus on a big customer like that will make you absolutely blind to the needs of anyone else.
TomWomack - Tuesday, December 15, 2020 - link
If I wanted to invert a very large sparse binary matrix (that is, to factor a large number, an activity that I hear some people do out of other than purely mathematical interest) this looks a lot like the hardware I would want. (Cerebras looks maybe even more like it, but the internal memory on its wafers isn't anything like enough)