Correcting Apple's A9 SoC L3 Cache Size: A 4MB Victim Cache
by Ryan Smith on November 30, 2015 10:31 AM EST
Along with today’s analysis of Chipworks’ A9X die shot, I’m also going to use this time to revisit Apple’s A9 SoC. Based on some new information from Chipworks and some additional internal test data, I am issuing a correction to our original analysis of Apple’s latest-generation phone SoC.
In our original analysis of the A9, I wrote that the L3 cache was 8MB. This was based upon our initial tests along with Chipworks’ own analysis of the physical layout of the A9, which pointed to an 8MB L3 cache. Specifically, at the time I wrote:
However it’s also worth mentioning that as Apple is using an inclusive style cache here – where all cache data is replicated at the lower levels to allow for quick eviction at the upper levels – then Apple would have needed to increase the L3 cache size by 2MB in the first place just to offset the larger L2 cache. So the “effective” increase in the L3 cache size won’t be quite as great. Otherwise I’m a bit surprised that Apple has been able to pack in what amounts to 6MB more of SRAM on to A9 versus A8 despite the lack of a full manufacturing node’s increase in transistor density.

My Layout Analysis For A9 (Die Shot Courtesy Chipworks)
As it turns out, 8MB of cache was too good to be true. After a few enlightening discussions with some other individuals, some further testing, and further discussions with Chipworks, both our performance analysis and their die analysis far more strongly point to a 4MB cache. In particular, Chipworks puts the physical size of the TSMC A9 variant’s L3 cache at ~4.5mm2, versus ~4.9mm2 for A8’s L3 cache. Ultimately TSMC’s 16nm FinFET process is built on top of their 20nm process – the metal pitch size as used by Apple is the same with both processes – and this is the limiting factor for the L3 cache SRAM density.
| Apple SoC Comparison | ||||||
| A9X | A9 | A8 | A7 | |||
| CPU | 2x Twister | 2x Twister | 2x Typhoon | 2x Cyclone | ||
| CPU Clockspeed | 2.26GHz | 1.85GHz | 1.4GHz | 1.3GHz | ||
| GPU | PVR 12 Cluster Series7 | PVR GT7600 | PVR GX6450 | PVR G6430 | ||
| RAM | 4GB LPDDR4 | 2GB LPDDR4 | 1GB LPDDR3 | 1GB LPDDR3 | ||
| Memory Bus Width | 128-bit | 64-bit | 64-bit | 64-bit | ||
| Memory Bandwidth | 51.2GB/sec | 25.6GB/sec | 12.8GB/sec | 12.8GB/sec | ||
| L2 Cache | 3MB | 3MB | 1MB | 1MB | ||
| L3 Cache | None | 4MB (Victim) | 4MB (Inclusive) | 4MB (Inclusive) | ||
| Manufacturing Process | TSMC 16nm FinFET | TSMC 16nm & Samsung 14nm |
TSMC 20nm | Samsung 28nm | ||
But what is perhaps more interesting is what Apple is doing with their 4MB of L3 cache. An inclusive cache needs to be larger than the previous (inner) cache level, as it contains a copy of everything from the previous cache level. On A8 this was a 4:1 ratio, whereas with A9 this is a 4:3 ratio. One could technically still have an inclusive L3 cache with this setup, but the majority of its space would be occupied by the copy of the A9’s now 3MB L2 cache.
So what has Apple done instead? Inlight of Chipworks’ reassessment of the A9’s L3 cache size it’s clear that Apple has re-architected their L3 cache design instead.
What I believe we’re looking at here is that Apple has gone from an inclusive cache on A7 and A8 to a victim cache on A9. A victim cache, in a nutshell, is a type of exclusive catch that is filled (and only filled) by cache lines evicted from the previous cache level. In A9’s case, this means that items evicted from the L2 caches are sent to the L3. This keeps recently used data and instructions that don’t fit in the L2 cache still on-chip, improving performance and saving power versus having to go to main memory, as recently used data is still likely to be needed again.
The shift from an inclusive cache to a victim cache allows the 4MB cache on A9 to still be useful, despite the fact that it’s now only slightly larger than the CPU’s L2 cache. Of course there are tradeoffs here – if you actually need something in the L3, it’s more work to manage moving data between L2 and L3 – but at the same time this allows Apple to retain many of the benefits of a cache without dedicating more space to an overall larger L3 cache.
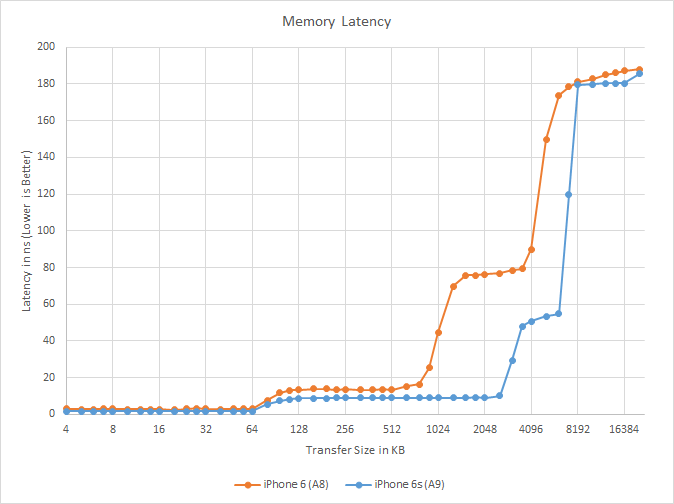
Meanwhile from the software side we can validate that it’s a victim cache by going back to our A9 latency graph. With the exclusive nature of the victim cache, the effective range of the L3 cache on A9 is the first 4MB after the end of the L2 cache; in other words, the L3 cache covers the 3MB to 7MB range in this test. Looking at our results, there’s a significant jump up in latency from 7MB to 8MB. Previously I had believed this to be due to the fact that our testing can’t control everything in the cache – the rest of the OS still needs to run – but in retrospect this fits the data much better, especially when coupled with Chipworks’ further analysis.
Ultimately the fact that Apple made such a significant cache change with A9 is more than I was expecting, but at the same time it’s worth keeping in mind that the L3 cache was only introduced back alongside Cyclone (A7) to begin with. So like several other aspects of Apple’s SoC design, A9 is very much an Intel-style “tock” on the microarchitecture side, with Apple having made significant changes to much more than just the CPU. Though coupled with what we now know about A9X, it does make me wonder whether Apple will keep around the L3 victim cache for A10 and beyond, or if it too will go the way of A9X’s L3 cache and be removed entirely in future generations.








14 Comments
View All Comments
tipoo - Monday, November 30, 2015 - link
All very interesting, particularly as I thought that not-8MB would have been helping with the large GPU gains. /None/ on A9X? Very, very interesting.xype - Monday, November 30, 2015 - link
Could that be due to the bigger bandwidth on the A9X? (sorry if the question is stupid, I’m not a CPU guy, just graphics designer who reads AT :P)xype - Monday, November 30, 2015 - link
Never mind, just read the same speculation in the other article…asendra - Monday, November 30, 2015 - link
This is super interesting, and better explains why there isn´t one in the A9X.Any rough estimate on the full A9X review (with SPEC2006 results :P)?
jasonelmore - Monday, November 30, 2015 - link
i knew it, people were giving apple to much credit for matching L3 Cache sizes with Core i7 CPU's and keeping the die so small.Everyone guess wrong, and this teaches us even Geekbench reports are to be taken with a grain of salt.
I am surprised they gimped the A9X with no L3 at all. Something more has to be going on here or did apple seriously just not have enough die space with all that gpu.
Regarding the Metal Pitch being 20nm even on a 16nm process, this has me worried about future Nvidia and AMD GPU's being built on TSMC. Both GPU vendors tried 20nm internally on prototypes, and saw negligible benifits, hence why they skipped it entirely.
extide - Monday, November 30, 2015 - link
The problem with the 20nm node was that it was not finfet -- and thus the leakage was super high making that process unsuitable for large chips running at high clock speeds. It was purely a problem with the FEOL (transistors) not the BEOL (metal layers). With the 16FF node -- this will not be an issue.name99 - Monday, November 30, 2015 - link
Way to miss the point along multiple dimensions.(a) What Apple is doing here is likely more sophisticated than what Intel is doing. The tricky point is not having an exclusive or victim cache, it is maintaining coherence between the GPUs and CPUs. An inclusive cache is a simple (but inefficient) solution to this problem. A more efficient solution is to use a directory (which you can imagine as something like the L3 holds a whole of additional tags without lines attached, tags describing the contents of the CPU and GPU L2 caches).
It is somewhat unclear just how much coherency both the Apple/ARM/Imagination world and the Intel world offer between GPUs and CPUs today. The impression I get is that such coherency as exists in TODAY's products is limited; but all parties want this to move to full coherence ASAP.
Given how fast Apple is moving, I suspect there is a lot happening on the successive A- chips that's not 100% ready for shipping, and which is not exposed to users/developers, but which was implemented for testing and experimentation, to inform the future; and I suspect that the A9 L3 in part fits into this category. (Which in part explains why it wasn't on the A9X --- it can perform a secondary job of testing Apple's directory implementation and clarifying any holes in the implementation/protocol by being on just one SoC; and clearly the combination of GPU L2 and wider memory bus is good enough for the iPad Pro to perform well.)
(b) WTF does Geekbench have to do with any of this? GB does not report L3 sizes. GB does not claim to be testing L3 performance.
You have the causality exactly backwards. The A9 posted spectacular GB (and every other benchmark) results, and we were immediately told by certain noisy individuals on the internet that this was PURELY because Apple had placed a massive 8MiB L3 on the CPU in order to game GB.
DarkXale - Monday, November 30, 2015 - link
>and we were immediately told by certain noisy individuals on the internetWho? Again, GB not testing L3 (or L2) is well known.
hlovatt - Monday, November 30, 2015 - link
There was a number of comments after Linus Torvalds of Linux fame said referring to Geekbench 3 (GB3) "I suspect most of them have a code footprint that basically fits in a L1I cache." This has led other people to sat that the Apple processors only give good GB3 scores because of large caches, L1 through L3. Note Linus only said L1 cache and only commented on GB3 other expanded this to all caches and Apple.Fmehard - Tuesday, December 1, 2015 - link
Those are wild and rosy guesses based on nothing more than your hunch ("Given how fast Apple is moving..") Fanboi much?